
from docx import Document
from docx.shared import Inches, Pt
from docx.oxml.ns import qn
from docx.enum.text import WD_TAB_ALIGNMENT
# 设置用例表格的内容
USeCaseNumber = "USeCaseNumber"
Test_Case_Description = "Test_Case_Description"
Test_Method = "Test_Method"
Pre_Condition = "Pre-condition"
# Test_STeps = "Test_Steps"
Actions = "Actions"
Expected_Result = "Result"
# 创建document对象
document = Document()
# 设置字体
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 添加段落文字说明,表示用例编号内容
p = document.add_paragraph()
p.paragraph_format.alignment = WD_TAB_ALIGNMENT.LEFT # 设置文字居左
r = p.add_run(USeCaseNumber) # 设置文字内容
r.font.size = Pt(14) # 设置字体大小
# r.bold = True # 字体是否加粗
# 设置表格内容
table = document.add_table(rows=5, cols=3, style='Table Grid') # 设置行数5和列数3
table.autofit = False
table.columns[0].width = Inches(2) # 设置每个单元格的宽度是2
# 合并单元格(cell(x,y)中 x代表行,y代表列,都从0开始,比如第一行第一列即为cell(0,0))
table.cell(0, 0).merge(table.cell(0, 0)) # 0行0列 与 0行0列合并
table.cell(0, 1).merge(table.cell(0, 2)) # 0行1列 与 0行2列合并
table.cell(1, 0).merge(table.cell(1, 0))
table.cell(1, 1).merge(table.cell(1, 2))
table.cell(2, 0).merge(table.cell(2, 0))
table.cell(2, 1).merge(table.cell(2, 2))
table.cell(3, 0).merge(table.cell(3, 0))
table.cell(3, 1).merge(table.cell(3, 1))
table.cell(3, 2).merge(table.cell(3, 2))
table.cell(4, 0).merge(table.cell(4, 0))
table.cell(4, 1).merge(table.cell(4, 1))
table.cell(4, 2).merge(table.cell(4, 2))
hdr_cells0 = table.rows[0].cells # 将第0行设为对象 hdr_cells0
hdr_cells1 = table.rows[1].cells # 将第1行设为对象 hdr_cells1
hdr_cells2 = table.rows[2].cells
hdr_cells3 = table.rows[3].cells
hdr_cells4 = table.rows[4].cells
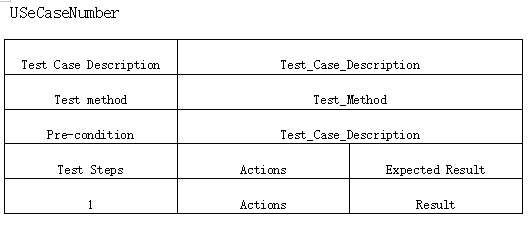
# 设置第0行 0 列的 为标题 文字描述为 Test Case Description
hdr_cells0[0].add_paragraph('Test Case Description').alignment=WD_TAB_ALIGNMENT.CENTER
# 设置第0行 1 列的 为内容 文字描述为 自定义的数据 Test_Case_Description
hdr_cells0[1].add_paragraph(Test_Case_Description).alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells1[0].add_paragraph('Test method').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells1[1].add_paragraph(Test_Method).alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells2[0].add_paragraph('Pre-condition').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells2[1].add_paragraph(Test_Case_Description).alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells3[0].add_paragraph('Test Steps').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells3[1].add_paragraph('Actions').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells3[2].add_paragraph('Expected Result').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells4[0].add_paragraph('1').alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells4[1].add_paragraph(Actions).alignment=WD_TAB_ALIGNMENT.CENTER
hdr_cells4[2].add_paragraph(Expected_Result).alignment=WD_TAB_ALIGNMENT.CENTER
# 创建文件名称并保存文件
document.save("用例文档.docx")



【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步