三、xlrd、xlwt、xml、openpyxl
# xlrd模块是用于读取表格数据的, xrld是一个第三方的需要自己安装pip install xlrd # 打开文件 wb = xlrd.open_workbook(路径) # 获取某个表格 sheet = wb.sheet_by_name() sheet = wb.sheet_by_index() # 获取行数列数 sheet.nrows() sheet.ncols() # 取某行数据 sheet.row_values(行索引) # 获取某行的数据 sheet.cell(行,列).valueimport xlrd # 1. 打开文件 workbook = xlrd.open_workbook("123.xlsx") # 2. 查看所有工作表的名称 print(workbook.sheet_names()) # ['Sheet1', 'Sheet2', 'Sheet3'] # 3. 获取某个工作表 # sheet = workbook.sheet_by_index(1) sheet = workbook.sheet_by_name("Sheet1") print(sheet.name) # Sheet1 # 获取某一行 row = sheet.row(2) print(row) # [text:'asd', number:16.0] # 获取单元格 cell = row[1] # 单元格的数据类型 print(cell.ctype) # 2 # 单元格的数据 print(cell.value) # 16.0 # 获取表格行数列数 print(sheet.ncols) # 列 print(sheet.nrows) # 行 # 获取第一行的单元格个数 print(sheet.row_len(1)) # 案例 将每个数据提取为python类型 li = [] # 先拿出所有的名称 keys = sheet.row_values(1) for i in range(2,sheet.nrows): print(i) # 直接取出所有值 row = sheet.row_values(i) dic = {} for k in keys: # 每次拿出一个key与一个value一一对应 dic[k] = row[keys.index(k)] li.append(dic) print(li) # [{'name': 'wang', 'age': 26.0}, {'name': 'qwe', 'yong': 18.0}]
import xlwt # 常用方法 # 创建一个工作簿 wb = xlwt.Workbook() # 创建一个工作表 sheet = wb.add_sheet("456") # type:xlwt.Worksheet # 写入数据 sheet.write_merge(0,0,0,4,"这是标题") # 将工作簿写入到文件 wb.save("abc.xlsx")# 案例 import xlwt data = [{'name': 'wangyong', '代号': 1.0, 'gender': 'man', 'age': 18.0, '生日': '2001-01-01 00:00:00'}, {'name': 'qwer', '代号': 748.0, 'gender': 'woman', 'age': 68.0, '生日': '1950-01-01 00:00:00'}, {'name': 'asdf', '代号': 168.0, 'gender': 'man', 'age': 18.0, '生日': '2001-01-01 00:00:00'}] wb = xlwt.Workbook() sheet = wb.add_sheet("砖家信息") # 写入标题 sheet.write_merge(0,0,0,4,"砖家信息表") # 写入列名称 keys = data[0].keys() i = 0 for k in keys: sheet.write(1,i,k) i += 1 #写入数据 for dic in data: values = list(dic.values()) row_inder = 2 + data.index(dic) for v in values: sheet.write(row_inder,values.index(v),v) # 保存文件 wb.save("国家机密数据")
三、xml模块
XML:可扩展标记语言
<tag style="color:red" age="18">12345</tag>
<tag></tag>双标签
<tag/>单标签,没有文本一般用于设计文档结构,例如换行等 </r>表示换行
一个标签分为三个部分:
tag是标签名称
12345是文本内容 text
age="18" 是标签的属性
其他的规范
1.又开始就必须有结束
2.所有属性值必须包含在双引号里面
3.只能有一个根标签 (最外层只能有一个标签)
4.开始标签和结束标签的顺序是相反的 最先打开谁 就最后关闭谁 最后打开的最先关闭
文档声明可不写 主要是告诉浏览器 该怎么解析这个文件
xml模块是自带的 不需要安装与json的区别
xml 是一种可扩展的标记语言
可以高度自定义文档的结构 数据类型 标签的含义等等
所以扩展性远比JSON要强json更加适用于 前后台数据交换 优点 轻量级 跨平台 语法简洁
xml更多用来作为配置文件 当然 python不太常用
html就是一种xml
<data> <country name="Liechtenstein">123<rank updated="yes">2</rank> <year>2010</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> <country>123</country> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2013</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2013</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
3.2.1 查
import xml.etree.ElementTree as ET # 打开一个文档,得到一个元素树(XML文档) tree = ET.parse("test.xml") # 获取根标签 root = tree.getroot() # print(root) # <Element 'data' at 0x000001F105CF5958> # 遍历出root标签的所有子标签 for tag in root: print(tag) # iter() # 如果没有参数则查找所有标签 # 如果有参数则查找所有名字匹配的标签 # 查找范围 为全文 for tag in root.iter(): print(tag) for tag in root.iter("country"): print(tag) # find() # 必须给参数 # 查找当前标签的子标签 返回第一个名字匹配的 country = root.find("country") print(country) # findall() # 必须给参数 # 查找当前标签的子标签 返回所有名字匹配的(返回为列表类型) countrys = root.findall("country") print(countrys)
import xml.etree.ElementTree as ET # 获得元素树 tree = ET.parse("test.xml") # 得到根标签 root = tree.getroot() # 获得所有的子标签 countrys = root.findall("country") for current_msg in countrys: print(current_msg.tag) # 查找当前标签的名称 print(current_msg.attrib) # 获得标签的所有属性 # print(current_msg.text) # 获得标签的文本内容 for inner_msg in countrys: print("%s的邻居如下:" % inner_msg.attrib.get("name")) for n in inner_msg.findall("neighbor"): print(n.attrib.get("name")) print("更新时间:%s" % inner_msg.find("year").text)
# 添加书签 import xml.etree.ElementTree as ET from xml.etree.ElementTree import Element tree = ET.parse("test.xml") root = tree.getroot() # type:# Element # 创建需要被添加的子标签 new_tag = Element("ThisIsNewTag") new_tag.text = "123" # 设置文本内容 root.append(new_tag) # 添加到root下 tree.write("test1.xml") # 写入的内容 <ThisIsNewTag>123</ThisIsNewTag>
# 删 将test.xml所有的gdppc删除 # remove函数,需要一个标签作为参数,即要被删除的标签,然后只能由父标签来删除子标签 import xml.etree.ElementTree as ET tree = ET.parse("test.xml") root = tree.getroot() for countrys in root.iter("country"): gdppc = countrys.find("gdppc") if gdppc != None: countrys.remove(gdppc) tree.write("test2.xml")
# 改 将test.xml中所有的year标签的text加1 import xml.etree.ElementTree as ET tree = ET.parse("test.xml") root = tree.getroot() for year in root.iter("year"): year.text = str(int(year.text) + 1) tree.write("test3.xml")
# 用代码生成一个xml文件 import xml.etree.ElementTree as ET # 创建标签 tag = ET.Element("DATA") tag.text = "12345" tag.set("name","wangyong") # 创建一个元素树,并把tag添加到上面 tree = ET.ElementTree(tag) tree.write("data.xml") # <DATA name="wangyong">12345</DATA>
四、openpyxl模块
4. 1 openpyxl介绍
安装第三方库openpyxl:pip install openpyxl此模块用于处理Excel表格,和上面的 xled、xlwt功能类似
4.2 创建excel文件
import openpyxl def create_excel(): """ 创建 excel :return: """ # 创建工作簿 wk = openpyxl.Workbook() # 获取当前工作表 sheet = wk.active # 写数据到单元格中 sheet.cell(1, 1).value = "姓名" sheet.cell(1, 2).value = "年龄" sheet.cell(1, 3).value = "婚姻" sheet.cell(2, 1).value = "王勇" sheet.cell(2, 2).value = "29" sheet.cell(2, 3).value = "单身" wk.save("机密文件.xlsx")
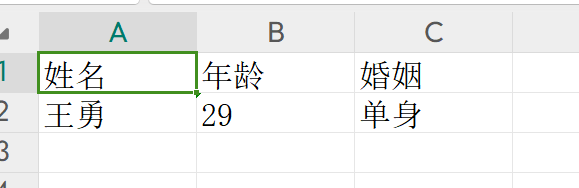
4.3 读excel文件
def read_excel(): """ 读取文件 :return: """ # 获取工作簿 wk = openpyxl.load_workbook("机密文件.xlsx") # 获取工作表(方式一) # sheet = wk.get_sheet_by_name("Sheet") # print(sheet) # 获取工作表(方式二) sheet = wk["Sheet"] # 获取单元格坐标 location = sheet.cell(2, 3) # 获取单元格的值 value = location.value print(location, value) # <Cell 'Sheet'.C2> 单身 # 获取工作表的行数和列数 rows = sheet.max_row cols = sheet.max_column print(f"行数{rows}, 列数{cols}") # 行数2, 列数3 # 获取工作表中的数据 data_list = [] for row in range(1, rows + 1): data_row = [] for col in range(1, cols + 1): value = sheet.cell(row, col).value data_row.append(value) data_list.append(data_row) print(data_list) # [['姓名', '年龄', '婚姻'], ['王勇', '29', '单身']] if __name__ == '__main__': read_excel()
4.4 编辑excel文件
def edit_excel(): # 加载工作簿 wk = openpyxl.load_workbook("机密文件.xlsx") # 创建新的工作表 new_sheet = wk.create_sheet("new_sheet") # 写入数据 new_sheet.cell(1, 1).value = "薇薇" new_sheet.cell(1, 2).value = "25" # 保存 wk.save("机密文件.xlsx") if __name__ == '__main__': edit_excel()

4.5 删除excel的sheet文件
def delete_excel(): """ 删除工作表 :return: """ wk = openpyxl.load_workbook("机密文件.xlsx") wk.remove(wk["new_sheet"]) wk.save("机密文件.xlsx") if __name__ == '__main__': delete_excel()
4.6 一次性添加多个数据
def add_data_to_excel(): """ 一次性添加多个数据到excel的工作表中 :return: """ wk = openpyxl.load_workbook("机密文件.xlsx") # 创建一个新的工作表 new_sheet = wk.create_sheet("new_sheet") data_list = ["王勇", "29", "单身"] new_sheet.append(data_list) wk.save("机密文件.xlsx") if __name__ == '__main__': add_data_to_excel()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号