六、数组
二、一维数组
一维数组定义的三种方式:
1、数据类型 数组名[ 元素个数 ];
2、数据类型 数组名[ 元素个数 ] = { 值1,值2 ...};
3、数据类型 数组名[ ] = { 值1,值2 ...};
int a[3]; /* 定义了一个数组。 1、int: 代表数组中每一个元素是 int 类型。就代表该数组是 int 类型 2、a: 数组名是 a。 a既可以表示数组名,也表示数组的首地址(指针) 3、3: 数组a中有3个元素,每一个元素都是 int 类型,他们在内存中的地址是连续的。也就是说, 每一个int占 4 个字节,3个元素共占 12 个字节的内存空间,而且是连续的12个字节。数组中元素的个数又称数组的长度。 4、数组的下标是从 0 开始的(不是 1)。所以这个数组的三个元素 分别是 a[0], a[1], a[2] 5、 所以定义一个数组 a[n],那么这个数组中元素最大的下标是 n–1;而元素 a[i] 表示数组 a 中第 i+1 个元素。 */ // 利用下标赋值 a[0] = 1; a[1] = 2; a[2] = 3;
// 1) 定义数组时给所有元素赋初值,这叫 "完全初始化" // int a[3] = {0,1,2}。 // 完全初始化时,初始化的元素个数必须等于数组长度,当初始化元素个数大于数组长度的时候,会报错。 // 完全初始化 #include<stdio.h> int main(void) { int a[3] = {0,1,2}; for(int i=0;i<3;i++) { printf("%d\n",a[i]); // 0,1,2 } return 0; }// 2) 可以只给一部分元素赋值,这叫 "不完全初始化" // int a[3] = {1, 2}; // 1. 不完全初始化时,没有被初始化的元素自动为 0。 ==> a[3] = {1,2,0} // 2. 需要注意,"不完全初始化" 和 "完全不初始化" 不一样。如果 "完全不初始化" ,即只定义 int a[3] 而不初始化,那么各个元素的值就不是0了,所有元素都是垃圾值。 // 3. int a[3]={}, 如果大括号中什么都不写,那就是极其严重的语法错误。大括号中最少要写一个数。比如“int a[3]={0}; ,这时就是给数组 清零 ,此时数组中每个元素都是零 // 4. 如果定义的数组的长度比花括号中所提供的初值的个数少,也是语法错误。如 a[3]={1,2,3,4,5}; // 5. C语言新标准允许 int[10] = {1,2,[7]=12}这样赋值,等价于 a[10] = {1,2,0,0,0,0,12,0,0,0}。目前大部分编辑器不怎么支持,不建议使用。 // 不完全初始化 #include<stdio.h> int main(void) { int a[3] = {1,2}; for(int i=0;i<3;i++) { printf("%d\n",a[i]); // 1,2,0 } return 0; } // 完全不初始化 #include<stdio.h> int main(void) { int a[3]; for(int i=0;i<3;i++) { printf("%d\n",a[i]); // 任意的随机数 } return 0; }
// int a[] = {0,1,2, 4}; // 1. 一定要初始化 // 2. 最终数组的长度为初始化的数据个数决定。 // 3. 数组长度的计算: 数组占内存总空间,除以单个元素占内存空间大小 #include<stdio.h> int main(void) { int a[] = {0,1,2, 4}; printf("%d\n", sizeof(a)/sizeof(a[0])); // 数组占内存总空间,除以单个元素占内存空间大小 for(int i=0;i<4;i++) { printf("%d\n",a[i]); } return 0; }
C语言中一维数组的访问一般通过数组的 下标来访问。数组的下标是从 0开始到数组的长度-1
数组的长度计算:
1. 看数组名后面的数字。
2. 数组占内存总空间,除以单个元素占内存空间大小。访问数组元素的时候,不能超过数组的元素个数,否则超过的访问值是随机数。
#include<stdio.h> int main(void) { int a[] = {0,1,2}; for(int i=0;i<4;i++) { printf("%d\n",a[i]); // 超出的值是一个随机值。 } return 0; }// 判断数组中是否含有某个元素。如果有,返回这个元素所在的位置 #include<stdio.h> int main(void) { int arr[10] = {15, 6, 64, 23, 56, 99, 78, 42, 14}; int pos = -1; int num, i; printf("请输入要查找的数字\n"); scanf("%d", &num); for(i=0; i<10; i++) { if (arr[i] == num) { pos = i; break; // 查找到数据直接break掉,后面的就没必要继续循环了,减少运行时间。 } } if(pos>=0) { printf("找到了数字%d, 在位置%d\n",num,pos); } else { printf("没有找到\n"); } return 0; } // 思考: 如果给定的数组中含有两个值是一样的,该怎么办?
/* C语言中,一维数组的数组名就代表数组的地址,同时也是数组中第一个 元素的地址 即: a = &a[0], &a代表着整个数组的地址,在数值上也 a = &a == &a[0],但是代表的意思并不一样。 */ // & 取地址符。 #include<stdio.h> int main(void) { int a[] = {0,1,2}; printf("%d\n", a); // 6487616 printf("%d\n", &a); // 6487616 printf("%d\n", &a[0]); // 6487616 return 0; }/* 当数组地址相加的情况下 1. 一维数组的数组名就相当于一维数组第一个元素的地址 即 a=&a[0] 2. 我们将一个数组看成是一排房子。 a的地址就是第一间房子的 地址,也就是 &a[0],当a+1的时候就指向第二个元素的地址,也就是 &a[1]的值。 而 &a代表着这个数组的地址,也就是这一排楼的地址。 但是 &a+1就代表着第二排房子的地址了。 */ #include<stdio.h> int main(void) { int a[] = {0,1,2}; printf("%d\n", a); // 6487616, 这一排房子的第一间房子的地址 printf("%d\n", &a); // 6487616, 这一排房子的地址 printf("%d\n", &a[0]); // 6487616, 第一间房子的地址 printf("%d\n", &a[1]); // 6487620, 第二间房子的地址 printf("%d\n", &a[1]+1); // 6487624, 加了一间房子的地址大小 printf("%d\n", &a[2]); // 6487624, 第三间房子的地址 printf("%d\n", a+1); // 6487620, 加了一间房子的地址大小 printf("%d\n", a+2); // 6487624, 加了两间房子的地址大小 printf("%d\n", &a+1); // 6487628, 加了一排房子的地址大小 printf("%d\n", &a+2); // 6487640, 加了两排房子的地址大小 return 0; }
作用: 最常用的排序算法,对数组内元素进行排序
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
重复以上的步骤,每次比较次数-1,直到不需要比较#include<stdio.h> int main(void) { int arr[9] = { 4,2,8,0,5,7,1,3,9 }; int i,j; for(i=0;i<9-1;i++) // 外层循环代表需要循环的轮数 { for(j=0;j<9-1-i;j++) // 内层循环代表每轮循环要进行比较的次数 { int tem; // 定义一个初始变量用于临时存储数据 if(arr[j]>arr[j+1]) { tem = arr[j]; // 交换两个数据 arr[j] = arr[j+1]; arr[j+1] = tem; } } } for(i=0;i<9;i++) { printf("%d\n",arr[i]); } return 0; }
选择排序是从数组的第一个元素分别与数组后面的元素依次进行比较,当后面的元素比第一个元素大的时候,交换两个元素。这样一轮结束后,最左边的元素就是数组中最小的值。
然后从第二个元素开始再依次往后进行比较。再第三个,......
依次这样至结束。#include<stdio.h> int main(void) { int arr[9] = { 4,2,8,0,5,7,1,3,6 }; int i,j; for(i=0;i<8;i++) // 外层循环代表使用数组中的第几个元素进行判断 { for(j=i+1;j<9;j++) // 内存循环代表依次和外层循环判断的数据 { int tem; if(arr[i]>arr[j]) { tem = arr[i]; arr[i] = arr[j]; arr[j] = tem; } } } for(i=0;i<9;i++) { printf("%d\n",arr[i]); } return 0; }
三、字符数组
字符数组: 顾名思义就是数组中每个元素都是字符。
#include<stdio.h> int main(void) { char arr[5] = {'a', 'b', 'c'}; for(int i=0; i<5; i++) { printf("%c ", arr[i]); // 按照字符依次输出 a b c } printf("\n"); // 价格换行区分打印内容 for(int i=0; i<5; i++) { printf("%d ", arr[i]); // 按照数字依次输出 97 98 99 0 0 } return 0; } // 从上述输出可以看出 字符数组未初始化的值在ASCII码中为编号为0的值为NUL。即 空字符(Null)
#include<stdio.h> int main(void) { char arr[5] = {'a', 'b', 'c'}; char str[] = {'a', 'b', 'c'}; char str1[5] = {'a', 'b','\0' ,'c'}; char str2[] = {'a', 'b' ,'c','\0'}; printf("%d\n",sizeof(arr)); // 5 printf("%d\n",sizeof(char [5])); // 5 printf("%d\n",sizeof(str)); // 3 printf("%d\n", sizeof(str1)); // 5 printf("%d\n", sizeof(str2)); // 4 return 0; } // 字符数组的大小为初始化 [] 设置的大小,不是看初始化变量的个数。当初始化 []中未声明大小的时候,则字符数组的大小为初始化元素的个数
四、字符串
字符串就是以 '\0' 结尾的字符数组。 '\0' 就是0, ASCII码的第一个 char str[5] = {'a', 'b', 'c', 'd', 'e'}; // 这是纯字符数组 char str1[5] = {'a', 'b', 'c', 'd', '\0'};// 字符串 char str2[5] = {'a', 'b', 'c', 'd', 0}; // 字符串 char str3[5] = {'a', 'b', 'c', '\0'}; // 字符串 char str4[5] = {'a', 'b', 'c'}; // 字符串 char str5[] = {'a','b', 'c','d','\0'}; // 字符串,
4.2 字符串的输出 (%s, puts)
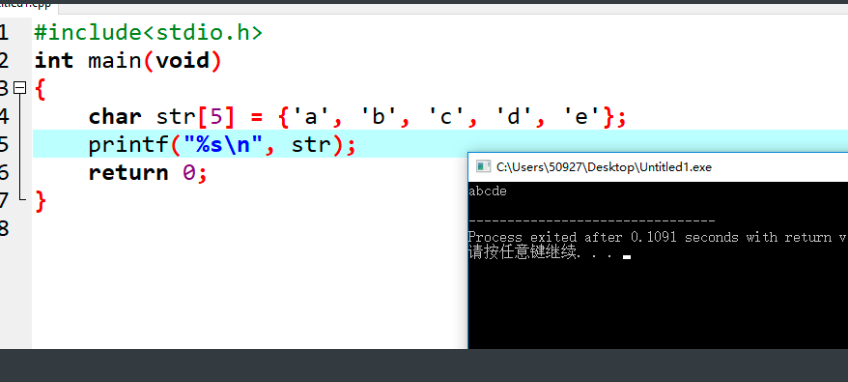
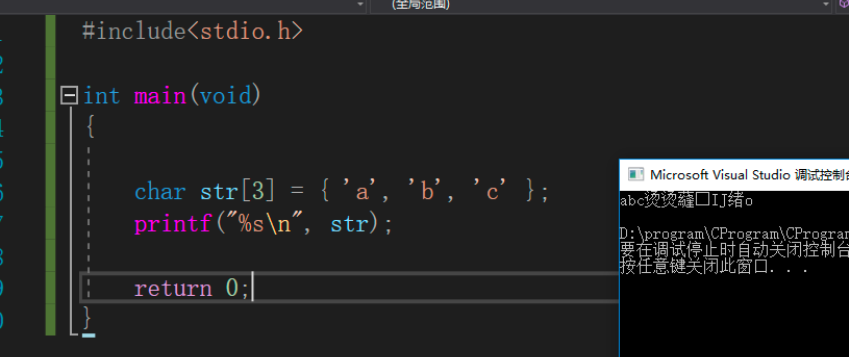
#include<stdio.h> int main(void) { char str[5] = {'a', 'b', 'c', 'd', 'e'}; printf("%s\n", str); return 0; } // 字符数组 使用 %s 进行输出的时候,在 DevC++中与Visual Studio两种编辑器中出现的结果不一样。
字符串按照 '\0'结束,当 char d[] 打印的时候,一直没有遇到 '\0',也就是 0,就会一直随机打印。因此出现上面的现象。
#include<stdio.h> int main(void) { char arr[4]; arr[0] = 'a'; // 字符串赋值 arr[1] = 'b'; arr[2] = 'c'; printf("%s\n", arr); //乱码输出, a[3]没有赋值。必须手动赋值 arr[3] = '\0'; return 0; } // 定义之后再一个个赋值与初始化之后直接少元素赋值是不一样的。
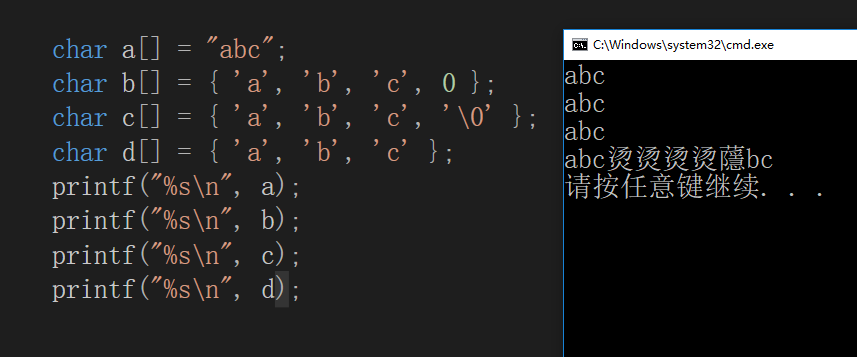
// 直接少元素赋值会默认添加'\0', 一个一个赋值不会添加'\0';#include<stdio.h> int main(void) { char str1[5] = {'a', 'b', 'c', 'd', '\0'}; char str2[5] = {'a', 'b', 'c', 'd', 0}; char str3[5] = {'a', 'b', 'c', '\0'}; char str4[5] = {'a', 'b', 'c'}; char str5[5] = {'a', 'b', '\0', 'c', 'd'}; char str6[5] = {'a', 'b', 0, 'c'}; char str7[] = {'a','b', 'c','d','\0'}; printf("%s\n", str1); // abcd str1代表字符串的首地址 printf("%s\n", &str1[0]); // abcd &str1[0]代表字符串的首地址 printf("%s\n", str2); // abcd printf("%s\n", str3); // abc printf("%s\n", str4); // abc printf("%s\n", str5); // ab, 打印到ab以后就遇到 '\0'了 printf("%s\n", str6); // ab, 打印到ab以后就遇到 0 了 printf("%s\n", str7); // abcd return 0; }
从上面的例子中我们能够得出: 如果字符串没有'\0',按照这种样式,后一直输出(可能就是乱码 visual studio,也可能正常退出 Dev C++),当内存往后遇到了第一个 0 或者 '\0'就会自动停下来。所以字符数组最好用 for来输出,字符串可以用 %s 输出。当字符串在输出的时候, 字符串中间出现的 0 或者 '\0'就代表字符串已经结束,此时后面的 字符就当做不存在了。
// puts函数是用来输出字符串, 当输出字符数组的时候,有的编辑器同样也可能或出现最后乱码的情况 // puts #include<stdio.h> int main(void) { char arr[6] = {'a','b', 'c','d','f'}; puts(arr); // abcdf return 0; }
4.3 常见字符串形式(" ")
// 用 "" 包括在内的多字符,会自动添加 '\0' char str[] = {'a', 'b','c', '\0'}; char str[] = "abc" // 会自动添加 '\0'char str[12] = "hello world"; /* 自带 '\0' 注意别越界 原理: 系统在栈区申请12字节的空间 将hello world\0依次复制进栈区字符数组str中 此时,系统是存在两个"hello world"的,一个是常量字符串"hello world",在字符常量区。
一份是str里,在栈区,我们通过str操作的,是栈区这份,常量字符串一点儿没变 */ char str[] = "hello world"; printf("%d\n", sizeof(str)) // 12 /* 自带 '\0' 这个不用考虑越界,长度系统自动计算。 原理: 系统计算常量字符串的长度12 系统在栈区申请12字节的空间 将hello world\0依次复制进栈区字符数组str中 此时,系统是存在两个"hello world"的,一个是常量字符串"hello world",在字符常量;
一份是str里,在栈区,我们通过str操作的,是栈区这份,常量字符串一点儿没变 */
char str[10]; str[10] = "wangyong"; // 错误 char str[12] = "Hello World"; char str[] = "Hello World";// 将str2的值赋值给str1 #include<stdio.h> int main(void) { char str1[] = "wang"; printf("%s\n", str1); // wang char str2[] = "yong"; for (int i = 0; i < sizeof(str2); i++) { str1[i] = str2[i]; } printf("%s\n", str1); // yong return 0; }
4.4 字符串操作函数(string.h)
用VS写程序时,经常遇到error C4996: 'strcpy': This function or variable may be unsafe.之类的错误提示。网上查原因是因为这些C库函数很多没有内部检查,微软担心这些函数可能造成栈溢出,所以改写了这些函数,并在原来的函数名字后加上_s以和C库函数区分,比如strcpy->strcpy_s,fopen->fopen_s等。
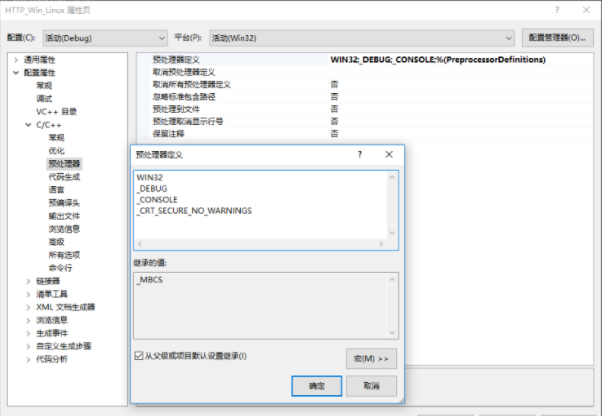
解决方式:
1. 在文件头上面添加: #define _CRT_SECURE_NO_WARNINGS
2.
4.4.1 strcpy,strcpy_s, strncpy,strncpy_s(复制字符串)
// strcpy /* char *strcpy(char *strDestination, const char *strSource ); 头文件, string.h 将参数2的内容复制进参数1中,所以参数1必须是字符数组, 并且参数1的字节数要>= 参数2的字节数,防止越界 */ #define _CRT_SECURE_NO_WARNINGS // strcpy 不安全, 微软的visual studio 会自动识别不安全, 因为参数2的字节可能大于参数1的字节长度。所以加上这个是为了不让编译器编译的时候报错, 其他的编译器可能不会 #include<stdio.h> #include<string.h> int main(void) { char str1[] = "wang"; char str2[] = "yong"; strcpy(str1, str2); printf("%s\n", str1); // yong return 0; }// strcpy_s /* errno_t strcpy_s(char *strDestination, size_t sizeInBytes, const char *strSource ); 多了一个参数,第二个参数,是指定参数1的字节数,这样, 复制就不会有越界了, 最大就到指定的这个字节数 Dev-C++编译报错,因为 strcpy_s 是微软公司为自己编译器 visual studio增加的功能 */ #include<stdio.h> #include<string.h> int main(void) { char str1[] = "Hello World"; char str2[] = "Wangyong123"; strcpy_s(str1, sizeof(str1), str2); // 第二个参数的 != str1 的长度的时候,报错 printf("%s\n", str1); // wangyong123 return 0; }// strncpy 用的最多 /* char *strncpy(char *strDest, const char *strSource, size_t count ); 复制指定个字符, 参数3表示复制的字符数 */ #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> int main(void) { char str1[12] = "Hello World"; char str2[] = "Wangyong123456"; strncpy(str1, str2, 5); // 第三个参数大小 原则上应该 小于或等于 目标字符串的大小。但是在有些编译器中,大于目标字符串的长度也可以编译通过,不过不建议这样使用。 printf("%s\n", str1); // wangy World return 0; }// strncpy_s visual studio中使用 /* errno_t strncpy_s(char *strDest, size_t sizeInBytes, const char *strSource, size_t count); 多了一个参数,第二个参数,是指定参数1的字节数,这样, 复制就不会有越界了 */ #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> int main(void) { char str1[] = "Hello World"; char str2[] = "Wangyong123456"; strncpy_s(str1, sizeof(str1), str2, 10); // strncpy_s(str1, 12, str2, 10); printf("%s\n", str1); // wangyong12 return 0; }
// scanf("%s",str); #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> int main(void) { char str[20]; printf("请输入字符串:"); scanf("%s", &str); // sfsdf dgdf 无法读取空格, %s会自动给我们加\0 printf("%s\n", str); // sfsdf scanf("%s", &str); printf("%s", str); // dgdf return 0; }// scanf_s /* char str[20] scanf_s("%s", str, 19); // 20指的str的字节数-1, 给'\0'留一个. 越界输入, 什么都不会显示 */ #include<stdio.h> #include<string.h> int main() { char str[20]; printf("请输入字符串: "); scanf_s("%s", str, sizeof(str)-1); // sizeof(str) - 1,留下一个字符给 '\0',此时也是最大的输入字符个数。当超多这个个数的时候,输出什么都不会显示 printf("%s\n", str); }// gets /* 跟scanf对比,可以读空格 小心越界, visual studio越界结束异常,Dev-C++结束正常能全部输入。不建议越界 */ #include<stdio.h> int main(void) { char str[20]; gets(str); // sffas dsfvsv printf("%s\n", str); // sffas dsfvsv return 0; }// gets_s(str, bytes) #include<stdio.h> int main(void) { char str[20]; gets_s(str, 19); // 留下一个给 '\0' printf("%s\n", str); return 0; }
/* size_t strlen(const char *str); 返回值返回长度的值 这个长度不计算 \0 */ #include<stdio.h> #include<string.h> int main(void) { char p[] = "12345"; size_t a = strlen(p); // 5 size_t == unsigned int printf("%d\n", a); return 0; }
字符串的长度代表以 '\0'结束之前的长度,不包括 '\0'在内。当字符数组找不到 '\0',就会一直往下走, 15代表随机数。
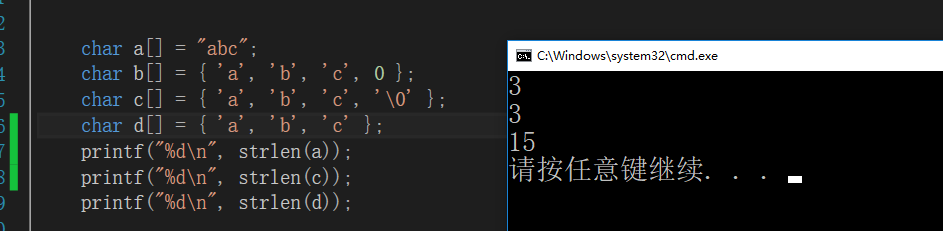
/* 原理:从第一个开始比较,比较 ASCII 码的数字,遇到不一样的立刻分出胜负, 谁大就是谁大,跟字符串长短无关 函数: int strcmp( const char *string1, const char *string2 ); 1>2 >0 两个字符的差值 1==2 =0 1<2 <0 int strncmp( const char *string1, const char *string2 , size_t count ); // 参数3:比前多少个 */// strcmp #include<stdio.h> #include<string.h> int main(void) { int a = strcmp("abcd", "abef"); printf("%d\n", a); // -1 return 0; }// strncmp #include<stdio.h> #include<string.h> int main(void) { int a = strncmp("abcd", "abef", 2); printf("%d\n", a); // 0 return 0; }
// strcat /* char *strcat( char *strDestination, const char *strSource ); 将参数2拼接到参数1上, 注意别越界 */ #include<stdio.h> #include<string.h> int main(void) { char str[20] = "abc"; strcat(str, 20, "defgh"); printf("%s\n", str); // abcdefgh,越界在这一行报错 return 0; }// strcat_s /* errno_t strcat_s( char *strDestination, size_t sizeInBytes, const char *strSource ); 参数2表示参数1的字节数 */ #include<stdio.h> #include<string.h> int main(void) { char str[20] = "abc"; strcat_s(str, 20, "defgh"); // 越界的话在此行报错 printf("%s\n", str); // abcdefgh return 0; }// strncat /* char *strncat( char *strDestination, const char *strSource ,size_t count ); 将参数2拼接到参数1上, 参数3,是拼接几个, 注意别越界 */ #include<stdio.h> #include<string.h> int main(void) { char str[20] = "abc"; strncat(str, "defgadgas", 3); // printf("%s\n", str); // abcdef return 0; }// strncat_s /* errno_t strncat_s( char *strDestination, size_t sizeInBytes, const char *strSource ,size_t count ); 参数2需要小于或者等于参数1的字节数 */ #include<stdio.h> #include<string.h> int main(void) { char str[20] = "abc"; strncat_s(str, 20, "defgadgas", 3); // 当 str的字符个数 + 参数4 的值 + 1 大于 参数 2 的时候,报错 printf("%s\n", str); // abcdef return 0; }
// atoi /* int atoi(const char *str ); 返回值是转好的整数 有些编译器需要添加头文件 stdlib.h。 visual studio不用添加 当字符串全部是数字的时候,直接转换成数字。 当字符串前面是数字,就后面是字符的时候。字符前面的数字转换成数字 当字符串以字符开头 返回值是0 */ #include<stdio.h> #include<string.h> #include<stdlib.h> int main(void) { int a = atoi("12345"); printf("%d\n", a); // 12345 int b = atoi("qwqw12345"); printf("%d\n", b); // 0 int c = atoi("12345qwqwqw"); printf("%d\n", c); // 12345 int d = atoi("1234wqw5qwq"); printf("%d\n", d); // 1234 int e = atoi("wqw1235qwq"); printf("%d\n", e); // 0 return 0; }
_itoa_s
// itoa /* char *itoa( int value, char *str, int radix ); stdlib.h 参数1是整数 参数2是转好后装进这里 参数3是指定转成几进制 2~36进制 先将整数转换成 2~36进制, 再转换成字符串存储起来 */ #define _CRT_SECURE_NO_WARNINGS #define _CRT_NONSTDC_NO_DEPRECATE #include<stdio.h> #include<string.h> #include<stdlib.h> int main(void) { char str[20]; itoa(255, str, 2); // printf("%s\n", str); // 11111111 itoa(235, str, 10); // printf("%s\n", str); // 255 itoa(235, str, 16); // printf("%s\n", str); // ff return 0; }// _itoa_s /* errno_t _itoa_s( int value, char *buffer, size_t sizeInCharacters, int radix ); 参数3是指定参数2的字节数, 参数4是进制 */ #include<stdio.h> #include<string.h> #include<stdlib.h> int main(void) { char str[20]; _itoa_s(255, str,20, 2); printf("%s\n", str); // 1111111 return 0; }
// sprintf /* int sprintf(char *buffer,const char *format [,argument] ... ); 格式化字符串 将参数2 的 整体字符串 存放到 参数1 buffer照片那个 */ #define _CRT_SECURE_NO_WARNINGS #define _USE_MATH_DEFINES // visual studio 中要有 #include <stdio.h> #include <math.h> #include<string.h> int main() { char str[80]; sprintf(str, "Pi 的值 = %f", M_PI); // M_PI 数学中的 π puts(str); // Pi 的值 = 3.141563 return(0); }// sprintf_s #include<stdio.h> #include<string.h> #include<stdlib.h> int main(void) { char str[20] = { 0 }; sprintf_s(str, 20, "%d, %c, %f", 12, 'v', 12.3f); printf("%s\n", str); // 12, v, 12.300000 return 0; }
// 在参数 str 所指向的字符串的前 n 个字节中搜索第一次出现字符 c(一个无符号字符)的位置。 void *memchr(const void *str, int c, size_t n) // 前 n 个字节进行比较。 int memcmp(const void *str1, const void *str2, size_t n) // 从 src 复制 n 个字符到 dest void *memcpy(void *dest, const void *src, size_t n) // 另一个用于从 str2 复制 n 个字符到 str1 的函数。 void *memmove(void *dest, const void *src, size_t n) // 复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。 void *memset(void *str, int c, size_t n) // 在参数 str 所指向的字符串中搜索第一次出现字符 c(一个无符号字符)的位置。 char *strchr(const char *str, int c) // 把 str1 和 str2 进行比较,结果取决于 LC_COLLATE 的位置设置。 int strcoll(const char *str1, const char *str2) // 检索字符串 str1 开头连续有几个字符都不含字符串 str2 中的字符。 size_t strcspn(const char *str1, const char *str2) // 从内部数组中搜索错误号 errnum,并返回一个指向错误消息字符串的指针。 char *strerror(int errnum) // 检索字符串 str1 中第一个匹配字符串 str2 中字符的字符,不包含空结束字符。也就是说,依次检验字符串 str1 中的字符,当被检验字符在字符串 str2 中也包含时,则停止检验,并返回该字符位置。 char *strpbrk(const char *str1, const char *str2) // 在参数 str 所指向的字符串中搜索最后一次出现字符 c(一个无符号字符)的位置。 char *strrchr(const char *str, int c) // 检索字符串 str1 中第一个不在字符串 str2 中出现的字符下标。 size_t strspn(const char *str1, const char *str2) // 在字符串 haystack 中查找第一次出现字符串 needle(不包含空结束字符)的位置。 char *strstr(const char *haystack, const char *needle) // 分解字符串 str 为一组字符串,delim 为分隔符。 char *strtok(char *str, const char *delim) // 根据程序当前的区域选项中的 LC_COLLATE 来转换字符串 src 的前 n 个字符,并把它们放置在字符串 dest 中。 size_t strxfrm(char *dest, const char *src, size_t n)
一个char能表示(0~255)256个数,这256个数都被ASCII码占用了,所以中文等其他字符,就要是用>255的数表示,即大于1字节的
2字节的话,能表示的数是0~65535 共65536个数,而世界收录的中文是4万多个,刚好在这个范围能全部分配一个数字,完美.
既然一个汉字是两个字节,用一个char肯定是装不下了,要用两个char,那好,两个char就是字符数组了,我们顺便加个'\0',他就变成字符串了
如何得到一个中文的数字码?
1. 百度“汉字国标码查询”
2. printf("%x%x", str[0], str[1]);#include<stdio.h> int main(void) { char str[3] = "王"; printf("%s\n", str); // 王 printf("%d\n", sizeof(str)); // 3 printf("%c%c\n", str[0], str[1]); // 王, %c一定要挨在一起 printf("%x%x\n", str[0], str[1]); //ffffffcdfffffff5, 中文的数字码 /* 一个字节刚好用两个16进制数 表示,那这个数对应的十进制是多少? printf("%x,%d\n", *(short*)str, *(short*)str); 发现结果是反着的, 原理,当一个类型是多个字节时候,系统从高字节向低字节组合 所以要想输出正确的,需要交换str[0] str[1]里的值 unsigned char temp = str[0]; str[0] = str[1]; str[1] = temp; printf("%x,%d\n", *(short*)str, *(short*)str); */ unsigned char temp = str[0]; str[0] = str[1]; str[1] = temp; printf("%x,%hu\n", *(short*)str, *(short*)str); //ffffcdf5,52725 return 0; }
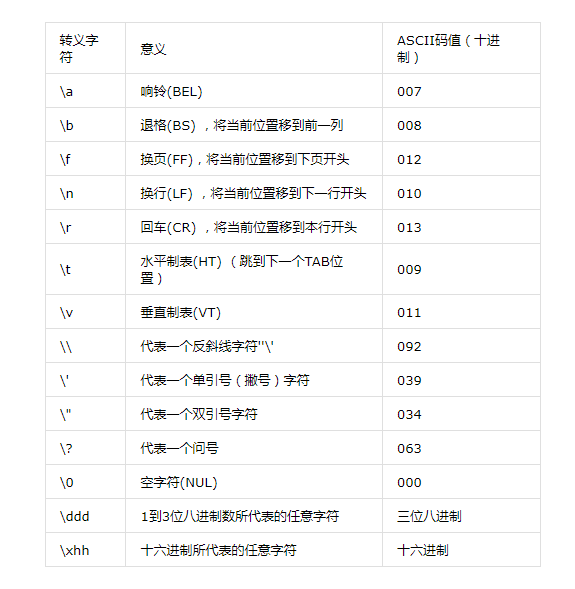
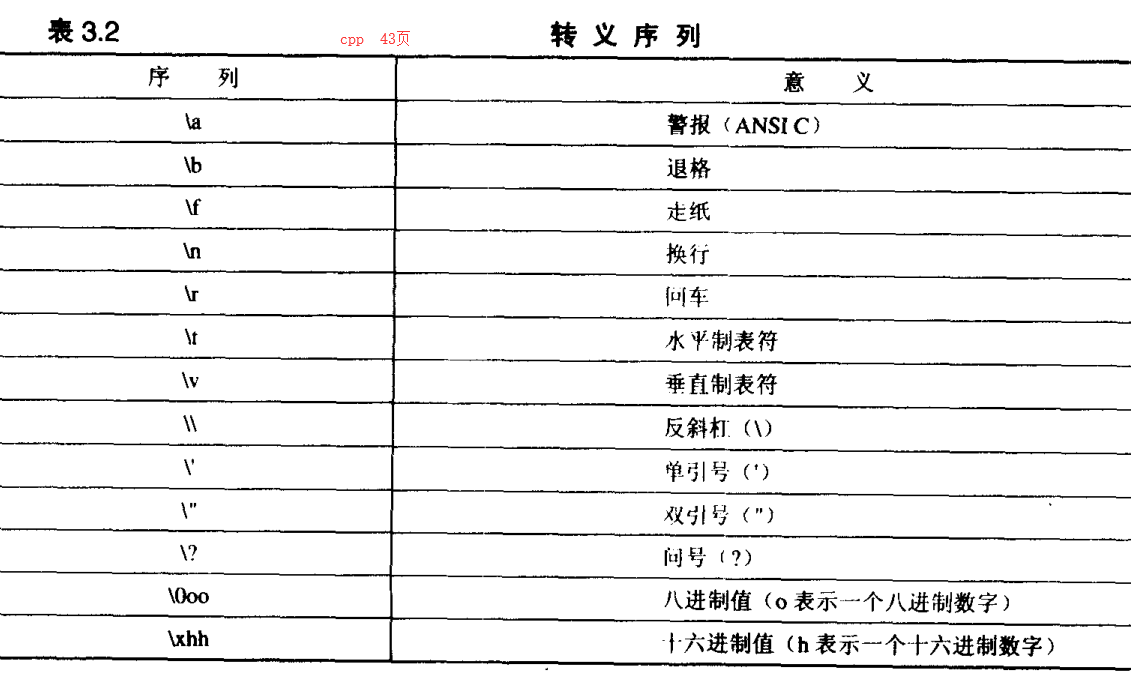

'\n': 这种输出不可见,所以只能%d 输出看看ASCII码值
' " \ : \' \" \\
% : %% 两个%输出一个
1. 用strlen测试
2. 转换说明符号是2个字节
3. 转义字符是1字节
\+字母 1字节 , 即使是未定义的,也是一字节 \+数字 \+数字 (1~3个) 0~377 是8进制 对应10进制 0~255 \+0+数字(1~2个) 0~77 是8进制 对应10进制 0~63 \+x+数字(1~2个) 0~ff 是16进制 对应10进制 0~255 这些是一字节,超过了这个范围就不一定了 测试 \58 // 2 \555 // 超过377 报错了 \5555 // 超过377 报错了 \018 // 2个 \xfff // 不能超过两个超过 报错了 \xfs // 2个
int a[3][2]; /* 1、二维数组就是两个[ ], 同理10维数组就是10个[ ] 2、前边的3表示大的数组里有3个小的一维数组 3、2表示每个小的一维数组有两个元素 4、元素个数==2*3, 5、字节大小 sizeof(a) */// 1. 二维数组的本质,元素是一维数组的一维数组 int a[3][2] = {{1,2},{3,4},{5,6}}; // 2. 三行两列的形式,便于理解.但是一定要注意,行列只是为了理解方便抽象出来的,数组本身都是线性的,
// 不会分行列,也就是说这 6 个元素在内存中是连续存储的 int a[3][2] = {{1,2}, {3,4}, {5,6}}; // 3. 其他形式的初始化 未指定数据的元素默认是0 int a[3][2] = {{1,2},{3,4}}; // {{1,2},{3,4},{0,0}} int a[3][2] = {{1},{3,4},{6}}; // {{1,0},{3,4},{6,0}} int a[3][2] = {1,2,3}; // {{1,2},{3,0},{0,0}} int a[][2] = {1,2,3}; // {{1,2},{3,0}}// 二维数组的访问:下标也是从0开始 #include<stdio.h> int main(void) { int a[][2] = {1,2,3}; printf("%d\n", a[1][0]); // 3 scanf("%d", &a[1][0]); // 4 给二维数组赋值 for (int i=0; i<2; i++) { for (int j=0; j<2; j++) { printf("%d ",a[i][j]); // 1 2 4 0 } } return 0; }
/* 类比一维数组,一维数组的数组名代表一维数组收元素首地址 1. 二维数组的数组名就是数组的首地址,也就是二维数组的第一个元素即第一个一维数组的地址 a = &a[0] 2. 在数值上 a == &a == &a[0] == &a[0][0], 但是意义是不一样的。 我们将二维数组看成是一个小区,(假设小区是里面每栋楼都是在一条直线上)每一个小区里面有很多栋楼,
每栋楼又有很多的房间。小区的名称就代表的地址, 3. a可以与&a[0]看成是一个意思。&a代表整个小区的地址, 当 &a+1 的时候,代表加了整个小区的地址到了
下一个小区。a+1 == &a[0]+1 代表小区第二栋楼的地址, &a[0][0]代表小区第一栋楼第一个房间的地址,
&a[0][0]+1就代表小区第一栋楼第二个房间的地址 */ #include<stdio.h> int main(void) { int a[3][2] = {{1,2}, {3,4}, {5,6}}; printf("%d\n", a); // 6487600 printf("%d\n", &a); // 6487600 printf("%d\n", &a[0]); // 6487600 printf("%d\n", &a[0][0]); // 6487600 printf("%d\n", &a[0][1]); // 6487604 printf("%d\n", &a[1][0]); // 6487608 printf("%d\n", a+1); // 6487608 printf("%d\n", &a+1); // 6487624 printf("%d\n", &a[0]+1); // 6487608 printf("%d\n", &a[0][0]+1);// 6487604 return 0; }
数组之间的赋值就是将一个数组的值赋值给另一个数组
一维数组和二维数组是一样的。
#include<stdio.h> int main(void) { int a[5] = {1,2,3,4,5}; // int b[5] = a; // 报错,不能用数组名字直接赋值,因为给数组初始化必须用 {} // int b[5] = {a}; // 警告,因为 a 代表的是数组 a的地址,二数组 b中的元素应该是 int类型 int b[5]; // b = a; // 报错,左操作数数左值。意思是数组名字是常量,不允许改变 for(int i=0; i<5; i++) { b[i] = a[i]; } for(int i=0; i<5; i++) { printf("%d\n",b[i]); // 1 2 3 4 5 } // 赋值指定元素 3,4,5 int c[5]; for(int i=0; i<3; i++) { c[i] = a[i+2]; } return 0; }
// memcpy(); /* 参数1:目标数组 参数2:被复制的数组 参数3:要复制的字节数,不是个数,不要越界赋值 */ #include<stdio.h> #include<string.h> int main(void) { int a[5] = { 1,2,3,4,5 }; int b[5],c[5]; memcpy(b,a,sizeof(int)*5); // 等价于 memcpy(&b[0],&a[0],sizeof(int)*5); for(int i=0; i<5; i++) { printf("%d\n", b[i]); } memcpy(&c[0], &a[2], sizeof(int) * 3); // 指定元素赋值过去 for (int i = 0; i < 5; i++) { printf("%d\n", c[i]); } return 0; }
// 类似二维数组,每个元素继续往上加数组就行。 #include<stdio.h> #include<string.h> int main(void) { int a[2][3][4] = { {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}}, {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}}}; // 两行三列,每列4个元素 // 数据获取 printf("%d\n", a[0][0][3] ); // 4 // 赋值 a[1][1][2] = 100; for(int i=0; i<2;i++) { for(int j=0; j<3; j++) { for (int k=0; k<4; k++) { printf("%d\n", a[i][j][k]); } } } return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号