Python入门
1.1 安装cpython解释器
https://www.python.org/
# 将python.exe 和 pip的路径加入到环境变量中 D:\python36 D:\python36\Scripts

1.4 运行python代码
1.4.1 交互式
# 控制台直接编写Python代码 1.打开终端 2.进入Python解释器 3.编写一行代码回车就执行>>> print("hello World") hello World
# 文件编写Python代码 把文件作为脚本交给解释器执行 1.在文件中编写好代码 2.打开终端 3.用指定版本的接收器命令执行文件的绝对路径# test.txt内容 print("hello world") C:\Users\wangyong>python C:\Users\wangyong\Desktop\test.txt hello world
注释:不会被python解释器解释执行,是提供给开发者阅读代码的提示
单行注释: #开头的语句
多行注释:出现在文件最上方,用''''''包裹的语句
pycharm快捷键:ctrl + /
二、变量与常量
# 变量即变化的量,核心是“变”与“量”二字,变即变化,量即衡量状态 程序中变量的本质:在程序运行中,值可以发生改变的量 python中所有的量在程序运行中都可以发生改变,所以python中没有绝对的常量 为什么要使用变量:让计算机有记录事物状态的功能
""" 定义变量:变量名 = 变量值 变量名:记录状态的名 = : 赋值符号 变量值:记录的状态 """ name = 'wangyong' sex = 'male'
1. 只能由字母、数字、_ 组成 2. 不能以数字开头 3. 避免与系统关键字重名:重名不会报错,但系统的功能就会被自定义的功能屏蔽掉了 【注】:一下关键字变为变量名直接会出现错误 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] 4. 以_开头的变量都有特殊含义 5. 以__开头和结尾的叫做魔法变量:内置变量 6. 建议使用_连接语法来声明长变量名:wang_yong 7. 支持小驼峰与大驼峰命名规范:wangYong WangYong 8. 多个单词的简写建议使用全大写:WY 9. 用全大写来标识常量:PI = 3.1415926

值:通过 变量名 直接访问就是访问值
地址:通过 id(变量名) 访问的就是变量堆区的地址
类型:通过 type(变量名) 访问的就是变量的类型
>>> a = "wangyong:sdsdsdsd" >>> b = "wangyong:sdsdsdsd" >>> id(a), id(b) (2257594873080, 2257594873152) >>> type(a), type(b) (<class 'str'>, <class 'str'>) >>> a == b True >>> a is b False >>>#1、在交互式模式下 Python实现int的时候有个小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被GC回收 每创建一个-5到256之间的整数,都是直接从这个池里直接拿走一个值,例如 >>> y=4 >>> id(y) 4297641184 >>> >>> x=3 >>> x+=1 >>> id(x) 4297641184 #2、在pycharm中 但在pycharm中运行python程序,pycharm出于对性能的考虑,会扩大小整数池的范围,其他的字符串等不可变类型也都包含在内一便采用相同的方式处理了,我们只需要记住这是一种优化机制,至于范围到底多大,无需细究
常量:在程序运行过程中,值不能被改变的量
python中没有严格的常量语法。
python中所有的量在运行过程中其实都能发生改变,只有自我保证不去改变全大写定义的变量值
PI = 3.1415926
2.6 格式化输出
2.6.1 % 格式化
这是Python中较旧的字符串格式化方法,它使用
%运算符来插入变量。name = "wangyong" age = 30 print("My name is %s and I am %d years old." % (name, age))
2.6.2 string.format() 方法
这是Python 2.6及以后版本中引入的一种新的字符串格式化方法。它使用
{}作为占位符,并通过format()方法来填充这些占位符。name = "wangyong" age = 25 print("My name is {} and I am {} years old.".format(name, age))print("My name is {name} and I am {age} years old.".format(name="Charlie", age=22))
2.6.3 f-string(Python 3.6+)
从Python 3.6开始,你可以使用f-string(格式化字符串字面量)来进行字符串格式化。这种方法允许你在字符串中直接嵌入表达式,只需在字符串前加上
f,并在字符串内部使用{}来包含变量或表达式。name = "wangyiong" age = 28 print(f"My name is {name} and I am {age} years old.")
三、基本数据类型
3.1 数字类型
>>> x = 11111 >>> type(x) <class 'int'># py3 所有整型都用int存储:数据量过大,采用字符串存储处理,如果需要运算,则可以直接拿来运算 # py2下:数据过长的用long类型存储,数据量小的整型的用int存储,只有py2采具有 long类型
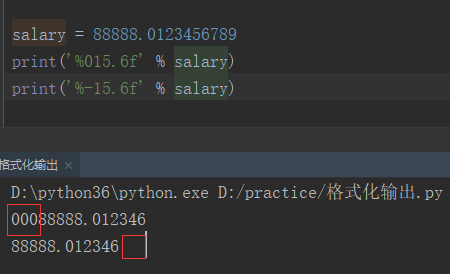
# float: 用来存放小数 >>> salary = 88888.0123456789 >>> print('%.6f' % salary) 88888.012346 # %.6f % salary # 1) %f对浮点型数据进行占位 # 2).后的数字表示小数精度 # 3).前的数据是输出的长度,小于等于要输出的数据长度不起作用,超出就采用规定的最大长度salary = 88888.0123456789 print('%015.6f' % salary) print('%-15.6f' % salary) # %015.6f:右对齐,左侧不足用0填充,%-15.6f:左对齐输出
#长整形 在python2中(python3中没有长整形的概念): >>> num=2L >>> type(num) <type 'long'> #复数 >>> x=1-2j >>> x.real 1.0 >>> x.imag -2.0
# bool类型:就是两个值 True、False result = False print(result)
3.3 字符串(str)
用'',"",'''''',""""""包含的字符,可以有多种引号嵌套
可以通过引号的嵌套,使内部不同的引号在不转义的情况下直接输出
# 1.字符串的索引取值: 字符串[index] (正向取值从0编号,反向取值从-1编号) s1 = '123qwe234' print(s1[2],s1[-1]) # 3 4 # 2.字符串拼接 s1 = '123qwe234' s2 = 'qwe432' print(s1 + s2) # 123qwe234qwe432 # 3.字符串长度 s1 = '123qwe234' print(len(s1)) # 9 # 4.字符串切片:取子字符串 [ : : ] [start_index:end_index:step] s1 = '123qwe234' print(s1[::]) # 123qwe234 print(s1[2:8:2]) # 3w2 print(s1[-2:-5:-1]) # 32e # 5.成员运算:判断某子字符串是否在该字符串中 s1 = '123qwe234' s2 = '123' print(s2 in s1) # True # 6.字符串循环(遍历) s1 = '123qwe234' for k in s1: print(k) # 7.索引(目标字符串的索引位置) s1 = '123qwe234' print(s1.index('q')) # 3 # 8.去留白 s1 = '123qwe234 ' print(s1.strip()) # 123qwe234 # 9.计算子字符串个数 s1 = 'haha123 wer' print(s1.count('ha')) #2 # 10.判断字符串是否为数字:只能判断正整数 s1 = '123qwe234' print(s1.isdigit()) # False # 11.大小写转换 s1 = 'abc' s2 = 'ABC' print(s1.upper()) # ABC print(s2.lower()) # abc # 12.以某某开头或者结尾 s1 = '123qwe234' print(s1.startswith('123')) # True print(s1.endswith('234')) # True # 13.替换 s1 = '123 qwe 234' print(s1.replace('123','234')) # 234 qwe 234 # 14.格式化 print('name:{0},age:{1}'.format('wangyong',25)) #name:wangyong,age:25 print('name:{1},age:{1}'.format('wangyong',25)) #name:25,age:25 # 15.拆分 s1 = "123,4567" res = s1.split(',') # 默认按照空格拆分 print(res) # ['123', '4567']
""" 1. find | rfind:查找子字符串索引,无结果返回-1 2. lstrip:去左留白 3. rstrip:去右留白 4. center | ljust | rjust | zfill:按位填充 语法:center(所占位数, '填充符号') 5. expandtabs:规定\t所占空格数 6. captialize | title | swapcase:首字母大写 | 单词首字母大写 | 大小写反转 7. isdigit | isdecimal | isnumeric:数字判断 8. isalnum | isalpha:是否由字母数字组成 | 由字母组成 9. isidentifier:是否是合法标识符 10. islower | isupper:是否全小 | 大写 11. isspace:是否是空白字符 12. istitle:是否为单词首字母大写格式 """
# 1.索引取值:列表名[index] ls = [3,2,1] print(ls[2]) # 1 # 2.列表运算:得到的是新的list ls = [3,2,1] ls1 = [2,1,3] print(ls + ls1) # [3, 2, 1, 2, 1, 3] # 3.list的长度 ls = [3,2,1] print(len(ls)) # 3 # 4.切片 ls = ['2','3','e','a'] print(ls[1:3]) # ['3', 'e'] # 5.成员运算 in ls = ['2','3','e','a'] print('3' in ls) # True # 6.循环 ls = ['2','3','e','a'] for k in ls: print(k) # 7. 增 ls = [1, 2, 3] ls.append(0) print(ls) # 末尾增 [1, 2, 3, 0] ls.insert(1, 666) print(ls) # 任意index前增 [1, 666, 2, 3, 0] ls.insert(len(ls), 888) print(ls) # insert实行末尾增 [1, 666, 2, 3, 0, 888] # 8.删 ls.remove(888) print(ls) # [1, 666, 2, 3, 0] res = ls.pop() print(res) # 默认从末尾删,并返还删除的值 0 res = ls.pop(1) print(res, ls) # 从指定索引删除,并返还删除的值 666 [1, 2, 3] # 9.排序: 针对于同类型 ls = [1,3,4,2] ls.sort() print(ls) # [1, 2, 3, 4] ls.sort(reverse=True) print(ls) # [4, 3, 2, 1] # 10.翻转 ls = [1,3,4,2] ls.reverse() print(ls) # [2, 4, 3, 1] # 11.计算值的个数 ls = [1,3,4,2,3,3] print(ls.count(3)) # 3 # 12.整体增加,添加到末尾 ls = [1,3,4,2,3,3] ls.extend('123') print(ls) # [1, 3, 4, 2, 3, 3, '1', '2', '3'] # 13.目标的索引位置,可以规定查找区间 ls = [1,3,4,2,3,3] print(ls.index(3)) # 1 # 找对象2,在索引3开始往后找到索引5之前,返回第一个被找到的值的索引位置 print(ls.index(2,3,5)) # 3
元组:可以理解为不可变的列表
1.值可以为任意类型
2.可以存放多个值 - 可以进行成员运算
3.可以存放重复的值 - 可以计算成员出现的次数
4.有序存储 - 可以通过索引取值,可以切片
# 1.索引取值 t = ('1','2','3','a') print(t[0]) # 1 # 2. 运算(拼接) t1 = ('1','2','3','a') t2 = (1,2,3) print(t1 + t2) # ('1', '2', '3', 'a', 1, 2, 3) # 3.长度 t1 = ('1','2','3','a') print(len(t1)) # 4 # 4.切片 t1 = ('1','2','3','a') print(t1[::-1]) # ('a', '3', '2', '1') # 5.成员运算 t1 = ('1','2','3','a') print('c' in t1) # False # 6.for循环 t1 = ('1','2','3','a') for k in t1: print(k)
3.6 字典(dict)
1. 字典存放数据 成对出现,dict存放数据采用 key-value键值对方式
2. 字典中的key可以为什么类型:key必须为不可变类型
key是取value的唯一依据,key一旦被确定,就需要唯一确定(不能被改变)
3. 字典中的value可以为什么类型:value可以为任意类型
value是用来存放世间所有存在的数据4. key要确保唯一性,不能重复,值可以重复,并且可以被改变 => 字典为可变类型
# 1.增 dic = {'a':1,'b':2,'c':3} dic['d'] = 4 print(dic) # {'a': 1, 'b': 2, 'c': 3, 'd': 4} # 2.改 dic = {'a':1,'b':2,'c':3} dic['b'] = '4' print(dic) # {'a': 1, 'b': '4', 'c': 3} # 3.查 dic = {'a':1,'b':2,'c':3} print(dic['c']) # 3 # 4.删 dic = {'a':1,'b':2,'c':3} print(dic.pop('a')) # 1 print(dic) # {'b': 2, 'c': 3} # 5.更新: dic = {'a':1,'b':2,'c':3} d = {'a':5,'d':10} dic.update(d) print(dic) # {'a': 5, 'b': 2, 'c': 3, 'd': 10} # 6.带默认值的新增: 新增key,key已有,啥事不干,没有添加key,值就是第二个参数 dic = {'a':1,'b':2,'c':3} dic.setdefault('x') print(dic) # {'a': 1, 'b': 2, 'c': 3, 'x': None} dic.setdefault('y',100) print(dic) # {'a': 1, 'b': 2, 'c': 3, 'x': None, 'y': 100} # 7.直接循环,就是循环得到key dic = {'a':1,'b':2,'c':3} for k in dic: print(k,end=' ') # a b c # 8.循环keys dic = {'a':1,'b':2,'c':3} for k in dic.keys(): print(k,end=' ') # a b c # 9.循环values dic = {'a':1,'b':2,'c':3} print(dic.values()) # dict_values([1, 2, 3]) for k in dic.values(): print(k,end=' ') # 1 2 3 # 10.同时循环key和value (key, value) dic = {'a':1,'b':2,'c':3} print(dic.items()) # dict_items([('a', 1), ('b', 2), ('c', 3)]) a, b = (1, 2) print(a, b) # 1 2 for res in dic.items(): print(res,end=' ') # ('a', 1) ('b', 2) ('c', 3) for k,v in dic.items(): print(k,v) # a 1 b 2 c 3
3.7 集合(set)
3.7.1 集合介绍
1.set为可变类型 - 可增可删
2.set为去重存储 - set中不能存放重复数据
3.set为无序存储 - 不能索引取值
4.set为单列容器 - 没有取值的key
总结:set不能取值
# 1.增 s = {'1','2','3','a','b','c'} s.add('d') s.add('1') print(s) # {'b', '3', '2', 'c', 'd', '1', 'a'} s = {'1','2','3','a','b','c'} s.update({'q','w','e'})print(s) # {'a', '2', 'q', '1', '3', 'c', 'w', 'e', 'b'} # 2.删 s = {'1','2','3','a','b','c'} s.remove('1') print(s) # {'3', '2', 'a', 'b', 'c'} s.clear() print(s) # set() # 3.集合的运算 # 交集:两个都有 & s1 = {'1','2','3','a'} s2 = {'a','b','c','1','2'} print(s1 & s2) # {'a', '1', '2'} print(s1.intersection(s2)) # {'a', '2', '1'} # 合集:两个的合体 | s1 = {'1','2','3','a'} s2 = {'a','b','c','1','2'} print(s1 | s2) # {'1', '2', 'b', 'a', 'c', '3'} print(s1.union(s2)) # {'1', '2', 'b', 'a', 'c', '3'} # 对称交集:抛出共有的办法的合体 ^ s1 = {'1','2','3','a'} s2 = {'a','b','c','1','2'} print(s1 ^ s2) # {'c', '3', 'b'} print(s1.symmetric_difference(s2)) # {'c', '3', 'b'} # 差集:独有的 s1 = {'1','2','3','a'} s2 = {'a','b','c','1','2'} print(s1 - s2) # {'3'} print(s1.difference(s2)) # {'3'} # 比较:前提一定是包含关系 s1 = {'1','2','3','a'} s2 = {'a','b','c','1','2'} s3 = {'1','2'} print(s1 > s2) # False print(s1 > s3) # True
3.8 深浅拷贝
可变类型:值改变的情况下,id不变 如:列表,字典,集合
不可变类型:值改变的情况下,id也跟着改变 如:数字,字符串,元组
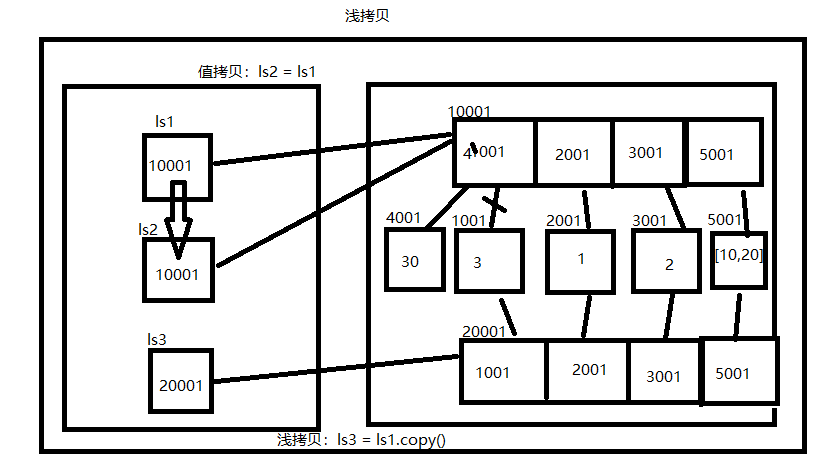
# s1直接将ls中存放的地址拿过来 # s1内部的值发生任何变化,s2都会随之变化 s1 = ['1','2','3','a'] s2 = s1 print(id(s1),id(s2)) # 1986703930376 1986703930376 s1[2] = 'b' print(id(s1),id(s2)) # 1986703930376 1986703930376
# 新开辟列表空间,但列表中的地址都是直接从ls列表中拿来 # s1内部的可变类型值发生改变,ls2会随之变化 s1 = ['1','2','3','a',['1','2']] s2 = s1.copy() s1[4][0] = 4 print(s1,id(s1)) # ['1', '2', '3', 'a', [4, '2']] 2143274411208 print(s2,id(s2)) # ['1', '2', '3', 'a', [4, '2']] 2143275228424
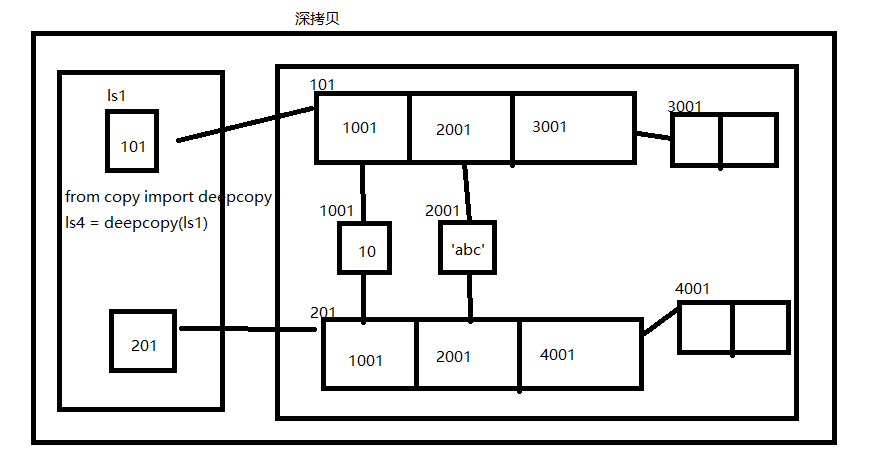
# 新开辟列表空间,s1列表中的不可变类型的地址直接拿过来,但是可变类型的地址一定重新开辟空间 from copy import deepcopy s1 = ['1','2','3','a',['1','2']] s2 = deepcopy(s1) s1[4][0] = 4 print(s1) # ['1', '2', '3', 'a', [4, '2']] print(s2) # ['1', '2', '3', 'a', ['1', '2']]
3.9 数据类型转换
3.9.1 字符串转换成数字类型
res = int('10') print(res) res = int('-3') print(res) res = float('.15') print(res) res = float('-.15') print(res) res = float('-3.15') print(res)
3.9.2 数字转换为字符串
s = 'abc123呵呵' print(list(s)) # ['a', 'b', 'c', '1', '2', '3', '呵', '呵'] 没有对应的 str(ls) ls = ['a', 'b', 'c', '1', '2', '3', '呵', '呵'] n_s = ''.join(ls) print(n_s) # 'abc123呵呵' # s1 = 'a b c 1 2 3 呵 呵' # res = s1.split() # 默认按空格拆 s1 = 'a b c 1 2 3 呵 呵' res = s1.split() print(res)
# 1.需求:"ie=UTF-8&wd=你好帅" => [('ie', 'UTF-8'), ('wd', '你好帅')] res = [] s4 = "ie=UTF-8&wd=你好帅" ls4 = s4.split('&') # ['ie=UTF-8', 'wd=你好帅'] for ele in ls4: # v = ie=UTF-8 | wd=你好帅 k, v = ele.split('=') # k: ie v: UTF-8 res.append((k, v)) print(res) # 2.需求:"ie=UTF-8&wd=你好帅" => {'ie': 'UTF-8', 'wd': '你好帅'} res = {} s5 = "ie=UTF-8&wd=你好帅" ls5 = s5.split('&') # ['ie=UTF-8', 'wd=你好帅'] for ele in ls5: # v = ie=UTF-8 | wd=你好帅 k, v = ele.split('=') # k: ie v: UTF-8 res[k] = v print(res) # 3.list与tuple、set直接相互转化 - 直接 类型()
3.10 运算符
# + | - | * | / | // | ** | % # 1.字符串和list可以做 + 和 * # 2./非整除,// 为整除 # 3.**求幂:5 ** 2 => 25 # 4.任意数 % n => [0, n-1] # 5.有负数参与的取余:符号跟着 % 后面那个数
# > | < | == | != | >= | <= # 1.运算结果为bool类型 print(3 > 5) # 2.可以连比 num = 10 print(1 < num < 20)
# += | -= | *= | /= | %= | **= | //= | = num = 10 num += 1 # num = num + 1 => 11 # 1.链式赋值 a = b = num # 2.交叉赋值 x = 10 y = 20 x, y = y, x # 3.解压赋值 ls = [3, 1, 2] a, b, c = ls # _是合法的变量名,会接受值,但我们认为_代表该解压位不用接收,用_来接收表示 _, _, g = ls # g才存放2,其他标示不接受
# and | or | not # 1.and: 左右都成立才成立,有不成立的就不成立 # 2.or: 左右都不成立才不成立,有成立的就成立 # 3.ont: 成立则不成立,不成立则成立 res = 0 and 20 # and前为假,整个式子就可以确定为假了,and后就不需要执行(短路) print(res) # 0 res = 10 or 20 # or前为真,整个式子就可以确定为真了,or后就不需要执行(短路) print(res) # 10
1.宏观一定是自上而下(逻辑上方代码一定比逻辑下方代码先执行):顺序结构
2.遇到需要条件判断选择不同执行路线的执行方式:分支结构
3.有些事情需要重复不断的去执行(当满足某种条件或不满足某种条件结束重复动作):循环结构
4.1 if分支结构
''' if 条件: 同缩进的代码块 ''' if age > 18: print("") if age > 30: print("") elif age > 18: print("") # 1.所有分支都可以根据需求决定是否有else结构,else结构就是条件(所有条件)不满足才去执行的分支 # 2.elif可以根据需求出现多次(代码层次方面要考虑条件的先后顺序)
# if嵌套 # 内部条件判断与否决定于外层条件 if 条件: if 条件: pass elif 条件: pass ... else: pass elif 条件: ... # 在任何结构(缩进下,需要条件判断)就可以出现if分支结构
4.2 while循环结构
''' 语法: while 条件: 循环体 # 1.当条件满足时,会执行循环体,然后再去判断条件成功与否 # 2.如果还满足,重复1,2的过程 # 3.如果不满足,结束循环体 # 注:如果需要结束循环,一定需要让条件在某种情况下不满足 '''
# break的意思是终止当层的循环,执行其他代码。 示例1: while True: print('1') print('2') break print('3') # 上面仅仅是演示break用法,实际不可能像我们这样去写,循环结束应该取决于条件 示例2: user_db = 'wangyong' pwd_db = '123' while True: inp_user = input('username: ') inp_pwd = input('password: ') if inp_user == user_db and pwd_db == inp_pwd: print('login successful') break else: print('username or password error') print('退出了while循环')
# continue的意思是终止本次循环,直接进入下一次循环 n = 1 while n < 10: if n == 6: n += 1 # 如果注释这一行,则会进入死循环 continue print(n, end="") # 12345789 n += 1
# 基础版 user_db = 'wangyong' pwd_db = '123' while True: inp_user = input('username: ') inp_pwd = input('password: ') if inp_user == user_db and pwd_db == inp_pwd: print('login successful') while True: cmd = input('请输入你需要的命令:') if cmd == 'q': break print('%s功能执行'%cmd) break else: print('username or password error') print('退出了while循环')# 上述方法有点low,有多个while循环就要写多个break,有没有一种方法能够帮我解决,只要我退出一层循环其余的各层全都跟着结束>>>:定义标志位 user_db = 'wangyong' pwd_db = '123' flag = True while flag: inp_user = input('username: ') inp_pwd = input('password: ') if inp_user == user_db and pwd_db == inp_pwd: print('login successful') while flag: cmd = input('请输入你需要的命令:') if cmd == 'q': flag = False break print('%s功能执行'%cmd) else: print('username or password error') print('退出了while循环')
# while+else:else会在while没有被break时才会执行else中的代码。 n = 1 while n < 3: if n == 2:break # 不会走else print(n) n += 1 else: print('else会在while没有被break时才会执行else中的代码')
4.3 for 循环
for 循环得到的结果 in 被循环的容器: 循环体 # 1.第一次循环,循环得到的结果 就是 被循环的容器 中第一个值 # 2.再次循环,循环得到的结果 会被重新赋值为 被循环的容器 中第二个值,以此类推 # 注:每一次循环 循环得到的结果 不使用,下一次循环就会被覆盖,无法找回 # 3.当 被循环的容器 中的值被 循环得到的结果 全部赋值一遍后,循环自动结束 ''' # range() # 1. range(结束不被包含) # 2. range(开始被包含, 结束不被包含) # 3. range(开始被包含, 结束不被包含, 步长) # 4. range(10, 5, -1) # [10, 9, 8, 7, 6]
# 1.循环列表 name_list = ['wang', 'yong', 'wangyong', 'wang_yong'] for name in name_list: print(name) # 对比与while更加简便 # 2.再来看for循环字典会得到什么 info = {'name': 'wangyong', 'age': 25} for item in info: print(item) # 拿到字典所有的key print(info[item]) # for可以不依赖于索引取指,是一种通用的循环取指方式 # for的循环次数是由被循环对象包含值的个数决定的,而while的循环次数是由条件决定的 # 3.打印 九九乘法表 for i in range(1,10): for j in range(1,i+1): # if j <= i: print('%s * %s = %s '%(j,i,i*j),end=' ') print() '''' 运行结构 1 * 1 = 1 1 * 2 = 2 2 * 2 = 4 1 * 3 = 3 2 * 3 = 6 3 * 3 = 9 1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16 1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25 1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36 1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49 1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64 1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81 '''
# break的意思是终止当层的循环,执行其他代码。 name_list = ['wang', 'yong', 'wangyong'] for name in name_list: if name == 'yong': break print(name) # wang
# continue的意思是终止本次循环,直接进入下一次循环 name_list = ['wang', 'yong', 'wangyong'] for name in name_list: if name == 'yong': continue print(name, end=" ") # wang wangyong
4.4 三目运算符
# 三目运算符:用于简化 if...else...的语法结构 # 1. 只能解决if...else...结构,其他if分支结构都不管 # 2. 一个分支提供一个结果: 如果一个分支提供了多个结果, 将多个结果通过元组返回 a = int(input('a:')) # 10 b = int(input('b:')) # 20 if a > b: print(a) else: print(b) # 20 res = a if a > b else b print(res) # 20
4.5 列表推导式
能被列表推导式推导的数据源必须在循环取值时可以得到一个值
可以应用于生成多个数据的场景,推导式也可以拥有见到的逻辑
ls = [] for i in range(1,6): ls.append(i) print(ls) # [1, 2, 3, 4, 5] ls = [v for v in range(1,6)] # [1, 2, 3, 4, 5] print(ls) ls = ['奇数' if v % 2 != 0 else '偶数' for v in range(1,6)] print(ls) # ['奇数', '偶数', '奇数', '偶数', '奇数']
4.6 字典推导式
能被推导式推导的数据源必须在循环取值时可以被解压赋值为两个值
ls = [('a',1),['b',2]] print(dict(ls)) # {'a': 1, 'b': 2} res = {k:v for k,v in ls} print(res) # {'a': 1, 'b': 2} res = {k.upper():v for k,v in ls} print(res) # {'A': 1, 'B': 2}
五、文件处理
print(u'abc') # 用于显示 #2.二进制字符串:b'' 二进制字符串以字节作为输出单位 print(b'abc') # 用于传输 #3.原义字符串:r'以字符作为输出单位,所有在普通字符串中能被转义的符号在这都原样输出' print(u'a\tb\nc') print(r'a\tb\nc') # 取消转义 """ abc b'abc' a b c a\tb\nc """
# 1.开文件:硬盘空间被操作系统持有,文件对象被应用程序持有 # 2.操作文件 # 3.释放文件:释放操作系统对硬盘空间的持有 f = open('a.txt','r',encoding='utf-8') date = f.read() print(date) f.close()
# 基础的读操作 f = open('source.txt', 'r', encoding='utf-8') f.read() # 将所有内容一次性读完 f.read(10) # 读取指定字符数 f.readline() # 一次读取一行(文件的换行标识就是结束本次读取的依据) f.readlines() # 将所有内容读存,按换行标识作为读取一次的依据,存放为列表 f.close() # 基础的写操作 wf = open('target.txt', 'w', encoding='utf-8') wf.write('123\n') # 一次写一条,行必须用\n标识 wf.write('456\n') wf.flush() # 向操作系统发送一条将内存中写入的数据刷新到硬盘 wf.write('789\n') wf.writelines(['abc\n', 'def\n', 'xyz\n']) # 一次写多行,行必须用\n标识 wf.close() # 1.将内存中写入的数据刷新到硬盘 2.释放硬盘空间
# 优化整合了文件资源的打开与释放 # -- 在with的缩进内可以操作文件对象,一旦取消缩进,资源就被释放了 # 打开一个文件方式: # as起别名,rf持有文件资源的变量 with open('target.txt', 'r', encoding='utf-8') as rf: print(rf.read()) # 文件操作的具体代码 # 缩进一旦取消缩进,资源就被释放了 # 打开两个文件方式: # 方式一:一长行 with open('target.txt', 'r', encoding='utf-8') as rf1, open('target1.txt', 'r', encoding='utf-8') as rf2: print(rf1.read()) print(rf2.read()) # print(rf1.read()) # 报错 # print(rf2.read()) # 报错 # 方式二:换行 with open('target.txt', 'r', encoding='utf-8') as rf1: with open('target1.txt', 'r', encoding='utf-8') as rf2: print(rf1.read()) print(rf2.read()) # print(rf1.read()) # 可以操作 # print(rf2.read()) # 不可以操作
主模式:r | w | a | x -- 主模式只能选取一个,规定着主要的操作方式 从模式:t | b | + -- 从模式也必须出现,但个数不一定是一个,为主模式额外添加功能 r: 读,必须有 w: 清空写,可有可无 a: 追加写,可有可无 x:创建写,必须无 t:默认,按字符操作 b:按字节操作 +:可读可写 # rt: 文件必须提前存在,不存在报错,文件操作采用字符形式 - 简写为 r # wt: 文件可以存在,也可以不存在,存在则清空后写入,不存在新建后写入,文件操作采用字符形式 - 简写为 w # at: 文件可以存在,也可以不存在,存在在之前内容的末尾追加写入,不存在新建后写入,文件操作采用字符形式 - 简写为 a # rb: 文件必须提前存在,不存在报错,文件操作采用字节形式 # wb: 文件可以存在,也可以不存在,存在则清空后写入,不存在新建后写入,文件操作采用字节形式 # ab: 文件可以存在,也可以不存在,存在在之前内容的末尾追加写入,不存在新建后写入,文件操作采用字节形式 # r+t:文件必须存在的可读可写,默认从头开始替换写,按字符操作 # w+t:文件存在清空不存在创建的可读可写,按字符操作 # a+t:文件存在追加不存在创建的可读可写,按字符操作 # r+b:文件必须存在的可读可写,默认从头开始替换写,按字节操作 # w+b:文件存在清空不存在创建的可读可写,按字节操作 # a+b:文件存在追加不存在创建的可读可写,按字节操作
5.6 文件操作的编码问题
''' t模式下:原文件采用什么编码,你就选取什么编码操作,如果不选取,默认跟操作系统保持一致 -- t模式下一定要指定编码 b模式下:硬盘的数据就是二进制,且能根据内容识别出编码,写入时的数据也是通过某种编码提前处理好的,所有在操作时,没有必要再去规定编码 '''
5.7 文件的复制
# 文本文件的复制:可以t也可以b with open('target.txt', 'r', encoding='utf-8') as rf: with open('target2.txt', 'w', encoding='utf-8') as wf: for line in rf: wf.write(line) with open('target.txt', 'rb') as rf: with open('target3.txt', 'wb') as wf: for line in rf: wf.write(line) # 非文本文件只能采用b模式操作,不需要指定编码 - 因为根本不涉及编码解码过程 with open('001.mp4', 'rb') as rf: with open('002.mp4', 'wb') as wf: for line in rf: wf.write(line)
5.8 游标操作
1.游标操作的是字节,所有只能在b模式下进行操作 2.游标操作可以改变操作位置,r模式下可以改变位置进行操作,所有主模式选择r模式 3.seek(offset, type): offset为整数就是往后偏移多少个字节,负数就是往前偏移多少个字节 type:0代表将游标置为开头,1代表从当前位置,2代表将游标置为末尾 with open('a.txt','rb') as f: # hahhah123sdhhs date = f.read(6) print(date.decode('utf-8')) # hahhah f.seek(3,0) # 将游标从头开始往后偏移3个字节 date = f.read(6) print(date.decode('utf-8')) # hah123 f.seek(-3,1) date = f.read(3) print(date.decode('utf-8')) # 123 f.seek(-3,2) date = f.read(3) print(date.decode('utf-8')) # hhs
六、内存管理与垃圾回收机制
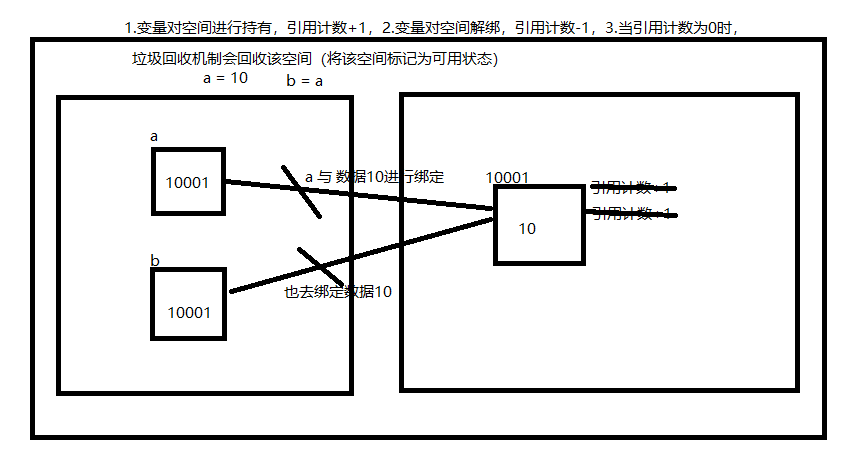
# 1.变量的值被引用,该值的引用计数 +1 # 2.变量的值被解绑,该值的引用计数 -1 # 3.引用计数为0时就会被垃圾回收机制回收
# 1.两个变量引用其值,值之间又相互引用 # 2.变量与值进行解绑,但是值之间还存在相互引用,导致值得引用计数永远 >0 # 3.引用计数>0的值永远无法被引用计数机制回收,导致内存泄露
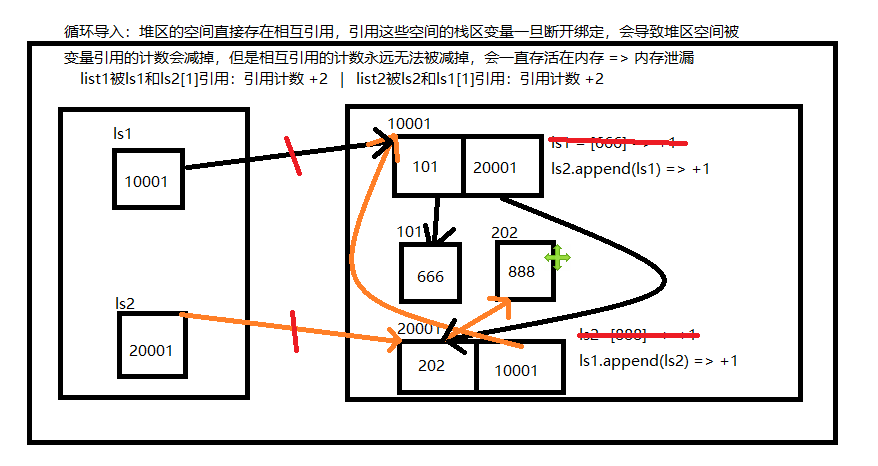
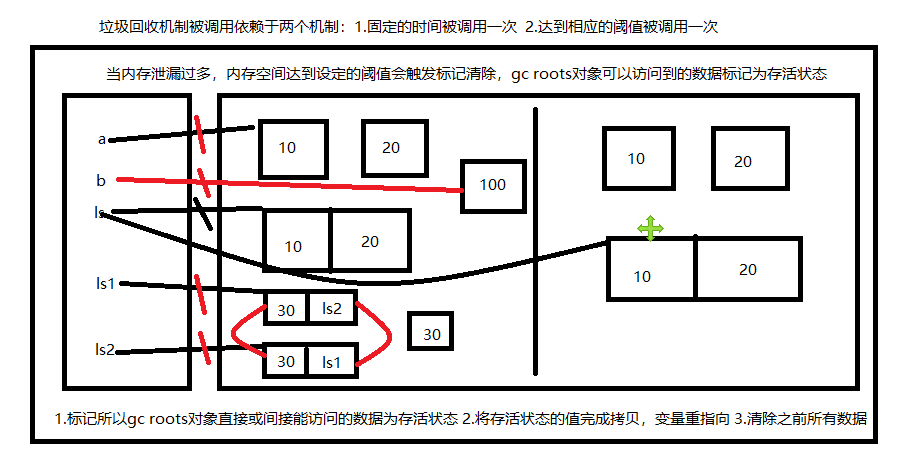
# 所有线程能访问到的栈区变量,称之为 gc roots对象 # 1.所有gc roots对象可以直接或间接访问到的变量值,都会被 标记机制 标记为存活状态 # 2.将所有存活状态的值形成新的拷贝,变量完成重新引用 # 3.清除机制 会将之前所有产生的值都进行回收
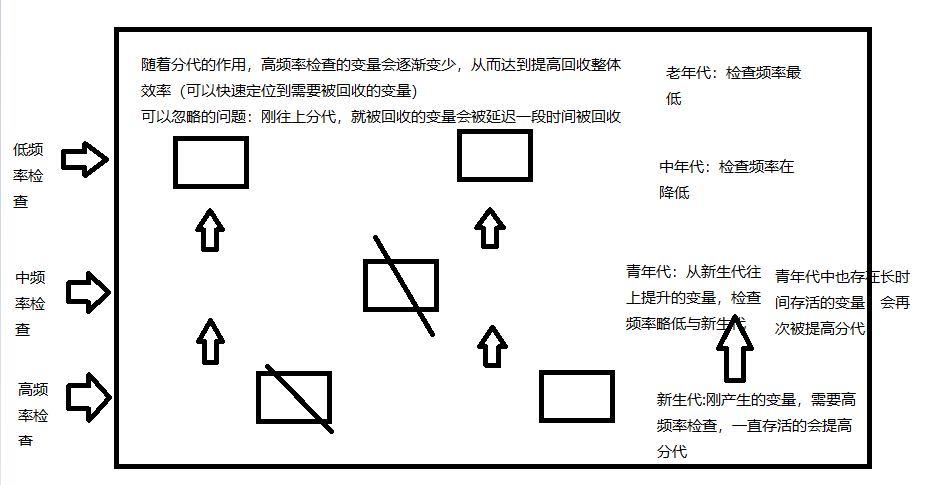
# 1.刚产生的变量值放在新生代中高频率检查,如果引用计数为0,就是采用引用计数机制回收,长期存活的变量值经过多次检查后会提高分代 # 2.分带又高,检查频率越低,且还能继续提高一直存活的变量值的分带,从而来提高整体垃圾回收的效率



【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 后端思维之高并发处理方案
· 理解Rust引用及其生命周期标识(下)
· 从二进制到误差:逐行拆解C语言浮点运算中的4008175468544之谜
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· 后端思维之高并发处理方案
· 千万级大表的优化技巧
· 在 VS Code 中,一键安装 MCP Server!
· 10年+ .NET Coder 心语 ── 继承的思维:从思维模式到架构设计的深度解析
· 上周热点回顾(3.24-3.30)