

眼界大开 声临其境丨胡宜峰:视频深度伪造检测技术在内容安全领域的探索与实践
导读:「眼界大开 声临其境」技术系列课第三期。网易易盾资深计算机视觉算法工程师胡宜峰带来了主题为《视频深度伪造检测技术在内容安全领域的探索与实践》技术分享。
讲师简介:胡宜峰,网易易盾资深计算机视觉算法工程师,主要负责图像和视频 AI 算法在内容安全领域的研发、落地和优化。在违禁、涉政、暴恐内容识别、logo 识别、图像检索、视频深度鉴伪等多个领域有丰富的研发和项目落地经验。

AI 技术应用的「双刃剑」效应
AI 是近些年热度颇高的词汇,并实实在在地渗入了生活的方方面面,如:AI+安全、AI+交通、AI+医疗、AI+零售等。在诸多 AI 技术的成熟应用中,人脸技术又是其中最为广泛应用的技术之一,常见于智能安防、金融交易、公共交通等领域,相信许多人都有过刷脸支付、刷脸入园的经历。

随着 AI 技术的蓬勃发展,AI 自动生成内容的水平取得了显著的提高。依托文本、语音、图像、视频等载体,AI 自动生成技术被广泛地用于模仿和伪造人类的想法、行为和特征。这在一定程度上降低了人力等成本的消耗,为我们的生活带来了便利和精神享受,AI 自动生成技术所带来的仿真数据和虚拟化内容一定程度上可以为一些垂直领域带来新的应用场景或者直接推动该领域的技术进步。
然而事物具有两面性,科技发展也存在着“双刃剑”效应。人们在享受人脸技术带来便利体验的同时,也不可避免地受到人脸技术滥用所带来的风险和隐患。随着 AI 换脸、自动美颜、智能 P 图等技术和应用的流行,由 AI 自动生成技术引发的安全风险和“黑灰产”问题也与日俱增,尤其是人脸相关技术,作为 AI 技术落地最为广泛的场景之一,所面临的安全、伦理和道德的挑战愈发严重。AI 自动生成技术和人脸技术在视频载体上的结合,也就是我们熟知的“视频深度伪造”,已经成为 AI 技术被滥用的“重灾区”。
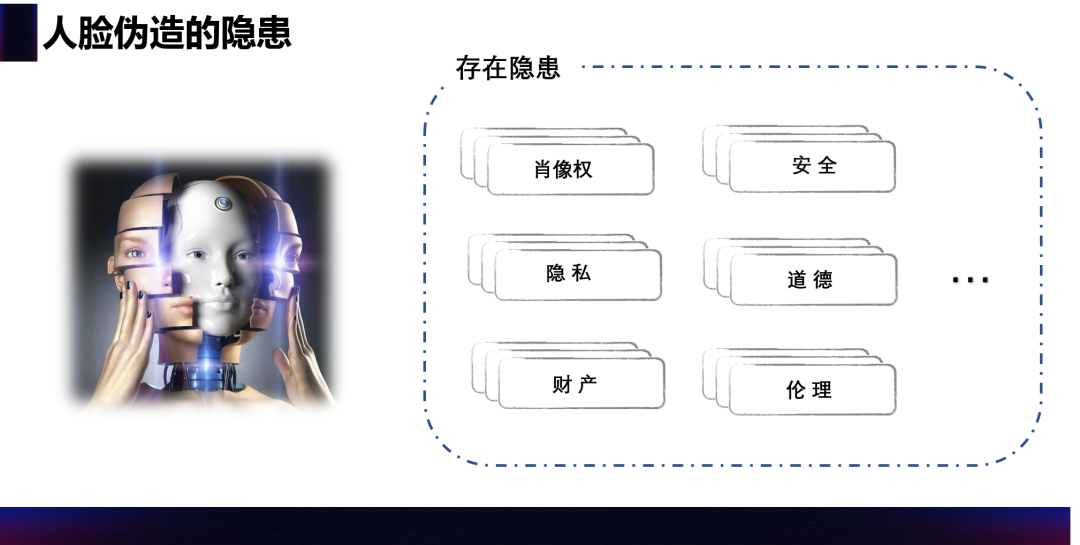
视频深度伪造技术
视频深度伪造技术,从技术方向上看,伪造方法主要分为 4 种。其一是全人脸的生成,这种一般是用 GAN 相关的算法生成现实生活中本不存在的虚拟人脸,常见于游戏等一些虚拟场景。其二是 AI 换脸,将生活中实际存在的人脸进行互相替换,这类应用由于针对性强、娱乐效果好,常常能广泛破圈传播,因此在学术界和工业界都是重点的核心研究对象。换脸是目前应用最广泛,也是潜在的隐患最大的视频深度伪造方法。其三是人脸属性的编程,主要包含发型、发色、眼睛、肤色等重要属性的编辑,常存在于一些自拍美颜美肤的 App 中。其四是表情改变,赋予人脸喜怒哀乐等不同表情,或是将 A 的表情体现在 B 脸上。
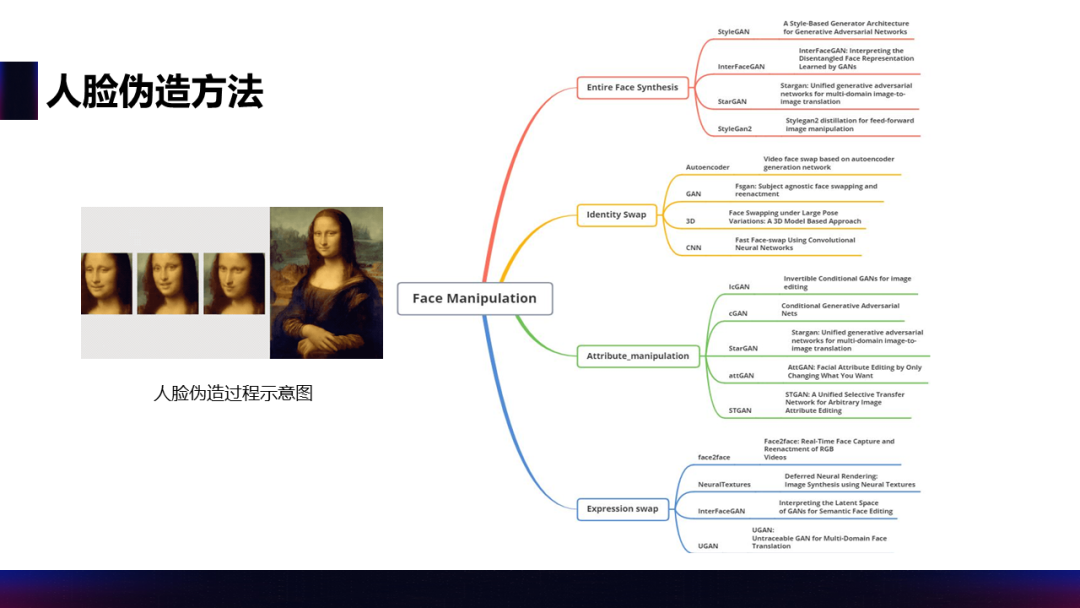
从具体算法上看,主要是通过 GAN、自编码器、风格迁移等方法来完成的,这里面也会涉及一些比如关键点定位、对齐、分割、融合等操作。
除了技术方向多、算法多,现在人脸伪造公开的数据集也比较多。这在一定程度上为视频深度鉴伪算法的创新和迭代提供了数据支撑,促进了视频深度鉴伪算法的发展。然而,视频深度鉴伪是一个持续对抗的开集问题,仅通过公开数据上训练的模型,想要很好地解决这个问题其实不太现实。为了更好地解决此问题,需要更加系统和全面的方案设计,这也是深度伪造检测这项业务的重点和难点。
视频深度伪造识别方法与难点
作为对视频深度伪造的对抗,视频深度鉴伪的方法主要有以下几种:人工特征、CNN、CNN+人工特征、CRNN、transformer 等等,这些方法囊括了人脸伪造识别最主要的方向,也描述了人脸伪造识别的整体历程。
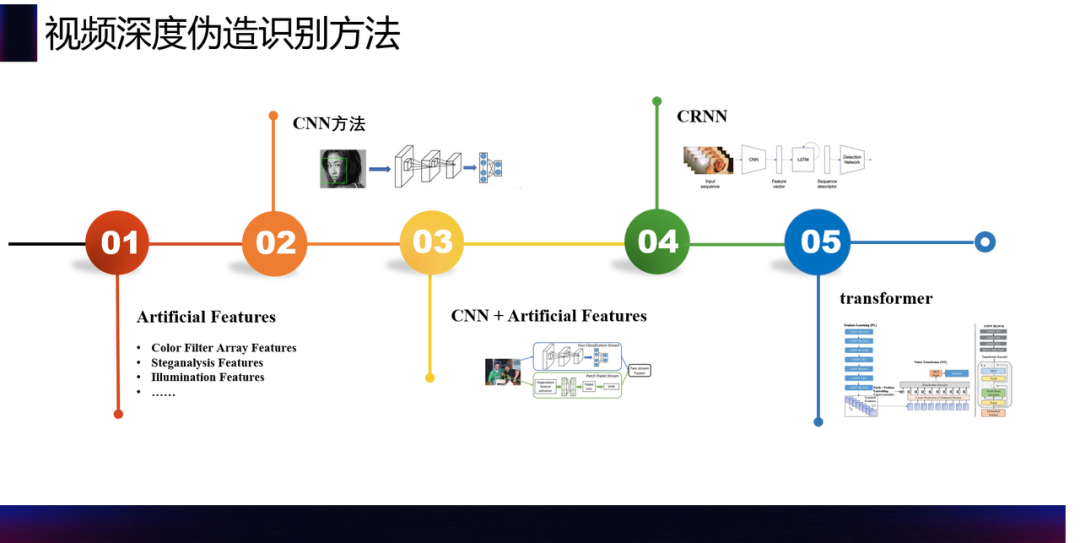
首先是人工特征,比如 eye blinking、head pose 等等,与真实人脸相比,人脸伪造或换脸必然会存在一定的不一致,也就是我们说的“伪造的痕迹”。基于这些统计层面上的痕迹去发掘人工特征,是比较传统和有效的方法。传统特征往往针对性比较强,但是泛化能力不足,尤其是在攻击的视频做过比较多后处理之后,传统特征的效果会大打折扣。所以现在一些研究工作从传统特征+CNN 特征入手,围绕特征和分类器层面的融合角度开展,把人工特征作为 deep learning 特征的补充。当然这里所说的人工特征,是指通过统计层面的观察加入先验知识,非端到端学习的方式。
当然,随着 deep learning 的发展,直接用 deep learning 进行端到端的人脸伪造识别也是现在研究的热点。基于 deep learning 的方法大多数是把人脸伪造识别转换成一个“人脸检测+分类”的问题,通过人脸检测先检测到人脸的位置,做适当的 expand 再进行 crop,送到后续进行是否为人脸的二分类。这种方式比较直接,流程相对简单,同时因为人脸检测现在比较成熟,一般不会是这个任务的难点所在,所以整个任务就转换成了一个人脸 patch 的分类问题。转换为分类问题后就可以更直接地衔接一些成熟方法来解决人脸伪造识别的问题,比如半监督学习、迁移学习等等。
随着 deepfake 的流行以及现在短视频的日益火爆,人脸伪造和换脸的主战场已经迁移到了视频领域,所以对人脸伪造的研究很自然地会加入视频序列信息,利用 RNN、LSTM 对序列特征进行编码,从而解决识别问题。这部分工作也是现在研究的热点。
通过对伪造和鉴伪的介绍,不难发现,伪造和鉴伪是一个对抗的过程,很多鉴伪方法也是针对某些伪造方法而定制设计的。这个对抗过程也反映了现在学术界的一个难点,鉴伪方法没有很好的泛化性。相同的鉴伪方法在不同的数据上,可能会出现巨大的表现差异。而且,这个学术界难题,迁移到工业界会被进一步放大,因为我们面对的并不是一种或者几种方法,也不是数据集,而是一个开集问题,面对的是海量的伪造方法和未知的互联网数据。所以说,未知方法多、对抗多等特点,给视频深度鉴伪的实践落地,带来了巨大困难。
当然,伪造方法多不仅仅体现在具体的伪造算法上。我们发现,其实伪造后处理也是对识别效果的巨大挑战之一。很多伪造方法,为了掩盖伪造痕迹,会做很强的后处理来进行对抗。现在比较流行的一些美白、美肤等工具,也客观起到了后处理的作用。这些后处理极大程度上会掩盖伪造的痕迹,给识别带来巨大难度。
除此之外,数据分布广泛是个更普遍的问题,在人脸识别里也会遇到。
网易易盾视频深度伪造检测解决方案
针对以上的难点,我们整体的解决方案如下图所示,采取了“人脸检测+分类”的整体思路。分类就是“是否为伪造人脸”的二分类。之所以选择这个主体方案,是因为这是目前在学术界效果最好、应用最广泛的方法,同时人脸检测也已经是业界非常成熟的技术,可以让我们的精力聚焦到后置的分类问题上,将识别问题转换为分类问题,这也更方便我们紧密结合业界的先进技术,达到事半功倍的效果。
那么针对上述伪造方法多、后处理方式多、数据分布广泛的问题。从数据层面,我们紧密结合了当前火热的半监督技术,挖掘难例样本、提高挖掘数据的精确度、降低标注开销、提升带噪学习的能力。同时,我们也会直接从伪造和后处理的角度,为识别提供对抗的素材。这两种方式,其实是数据层面的融合。算法层面,常见有效的方法和特征我们的方案都会涉及到,并进行特征层面选择及融合。当然,最终决策层面的融合也是非常重要的方式。
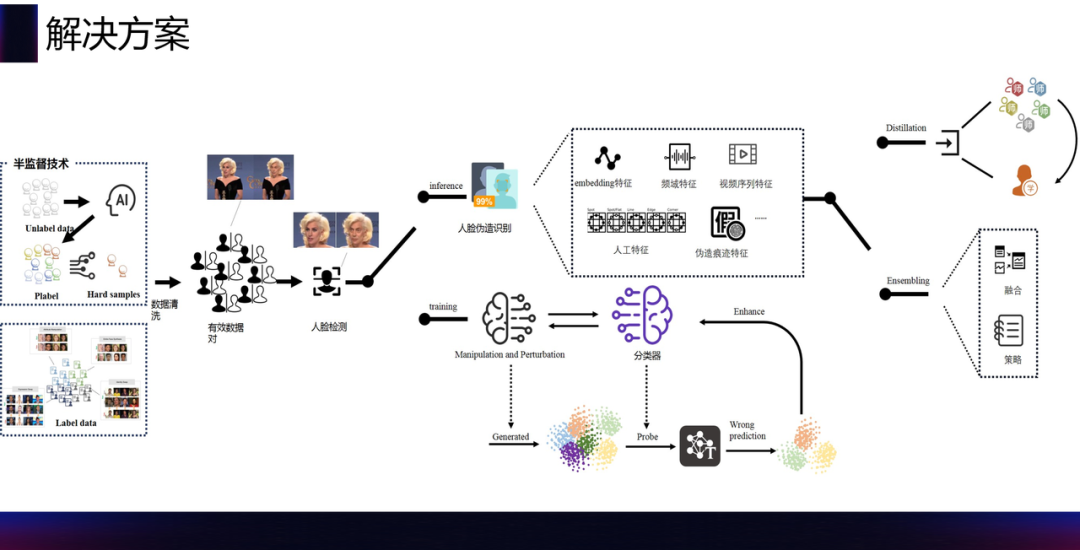
半监督的方法大家可能都比较熟悉,这里需要指出的是,半监督方法和视频深度鉴伪问题存在比较好的契合性。所谓契合性,可以从半监督的方法和我们之前讨论难点的直接关系来看。以下列举了主要的半监督的方法:generative methods、consistency regulation、Plabel、hybrid methods。
首先是生成式的方法,前面也有提到,deepfake 的数据,很多是 GAN 生成的,这里可以和 generative 的半监督方法做一个比较自然的衔接,对应的是我们提到的生成方式多样的难点。其次是 consistency regulation 的方法,我们知道 consistency regulation 的方法核心思想是输入做了不同变换的 pair 对,输出应该保持一致。这其实是为了提升模型的泛化能力以及提升模型的变换鲁棒性。这个点可以对应于前面提到的后处理方法多样的难点,通过利用无标签数据,提升模型变换的鲁棒性。基于 Plabel 的方法,核心是通过伪标签的方式,扩充训练数据的分布,从而提升模型的性能。这对应于我们前面说的伪造方法多、数据分布广泛的问题。
所以,在 deepfake detection 这个问题上应用半监督方法,能较好地对应解决相关难点。
除了半监督,因为 deepfake 是一个攻守对抗问题,生成训练数据并有监督地训练初始模型,也是最直接有效的方法。当然,这里也要考虑生成方法多样、后处理方法多等问题。
现在学术界对 deepfake detection 的研究很多。前面也有提到,这些研究大多数是从特征网络结构设计、loss设计等层面,发掘和融合出更具鲁棒的特征进行识别,包括常规的 embedding 特征、频域特征、序列特征、人工定义特征、伪造痕迹特征等。这些方法的融合,一部分是特征层面的融合,一部分是决策层面的融合。需要指出的一点是,从训练数据到算法,deepfake detection 都是一个针对性很强的任务,要想在开集问题上取得较好的泛化效果,除了在单个算法上寻求突破外,多种方法的融合和选择,也是最核心、最有效的方法之一。
所以,在决策层面的融合是必不可少的内容。模型融合,是最直接有效能提升模型效果和泛化性的方法。这个思路在其他 AI 问题上是通用的,但是有个特殊的点需要指出,一般模型融合的共识是在测试集上表现有差异但指标相似的模型,融合会有效果提升,而 deepfake detection 由于跨伪造方法的泛化能力不强,往往会出现两个模型在同一批数据上表现差异很大的情况。针对这个问题,需要更加细致地考虑融合的策略,增加更多选择的策略。
当然,多个模型速度会受到一定的限制,在非离线的速度要求较高的场景,会进一步进行模型的蒸馏,让小模型集成多个大模型的能力。
网易易盾视频深度伪造检测的成果
正如其它的涉政、暴恐、违禁相关的业务一样,视频深度伪造检测也被定位为一个开集的不断迭代优化的问题。网易易盾从解决思路、数据、模型等角度,设计了完整的解决方案。成果方面,在第二届中国人工智能大赛视频深度伪造检测赛道,网易易盾从188家企业、高校、研究单位中脱颖而出,以TOP1的成绩获得了最高级A级别证书。

今天的分享从背景、伪造、识别、技术方案的角度,给大家介绍了伪造和识别相关的内容。希望对 AI、伪造识别相关领域感兴趣的同学能从本文获得一些帮助。
扫码关注公众号,了解更多~~

