数据结构与算法(八),查找
前面介绍了基本的排序算法,排序通常是查找的前奏操作。这篇介绍基本的查找算法。
1、符号表
符号表(Symbol Table)是一种存储键值对的数据结构,它可以将键和值关联起来。支持两种操作:插入,将一组新的键值对插入到表中;查找,根据给定的键得到响应的值。
符号表,有时又称索引,是为了加快查找速度而设计。它将关键字Key和记录Value相关联,通过关键字Key来查找记录Value。在现实生活中,我们经常会遇到各种需要根据key来查找value的情况,比如DNS根据域名查找IP地址,图书馆根据索引号查找图书等等:
符号表的特征:
- 表中不能有重复的键
- 键和值不能为空
符号表的抽象数据类型:
public interface ST<K, V> {
//将键值对存入表中
void put(K key, V value);
//获取key对应的值
V get(K key);
}
2、顺序查找
顺序查找(Sequential Search)又称线性查找,是最基本的查找技术。从表中第一个记录开始,逐个进行查找,若记录的关键字和给定值相等,则查找成功。若直到最后,没有关键字和给定值相等,则查找失败。
代码:
public class SequentialST<K, V> implements ST<K, V>{
private Node head;
private class Node {
K key;
V value;
Node next;
public Node(K key, V value, Node next) {
super();
this.key = key;
this.value = value;
this.next = next;
}
}
@Override
public void put(K key, V value) {
Node temp = sequentialSearch(key);
if(temp != null) {
temp.value = value;
}else {
head = new Node(key, value, head);
}
}
//顺序查找,【关键】
private Node sequentialSearch(K key) {
for(Node cur= head; cur != null; cur=cur.next) {
if(key.equals(cur.key)) {
return cur;
}
}
return null;
}
@Override
public V get(K key) {
Node temp = sequentialSearch(key);
if(temp != null) {
return temp.value;
}
return null;
}
public static void main(String[] args) {
SequentialST<String, Integer> st = new SequentialST<>();
st.put("AA", 2);
st.put("BB", 2);
System.out.println(st.get("BB"));
}
}
很显然顺序查找的时间复杂度为O(N),效率非常低。
3、二分查找
二分查找(Binary Search),又称折半查找。二分查找的前提是符号表中的记录必须有序。在符号表中取中间记录作为比较对象,若中间值和给定值相等,则查找成功;若给定值小于中间值,则在左半区继续查找,否则在右半区进行查找;不断重复直到成功或失败。
代码:
/**
*基于二分查找的符号表
*/
public class BinarySearchST<K extends Comparable<K>, V>
implements ST<K, V> {
private K[] keys;
private V[] values;
private int size;
public BinarySearchST(int capacity) {
keys = (K[]) new Comparable[capacity];
values = (V[]) new Object[capacity];
}
@Override
public void put(K key, V value) {
int i = binarySearch(key, 0, size-1);
//查找到给定的键,则更新对应的值, size=0时,i=0
if(i < size && keys[i].compareTo(key) == 0) {
values[i] = value;
return;
}
for(int j=size; j>i; j--) {
keys[j] = keys[j-1];
values[j] = values[j-1];
}
keys[i] = key;
values[i] = value;
size++;
}
@Override
public V get(K key) {
int i = binarySearch(key, 0, size-1);
if(keys[i].compareTo(key) == 0) {
return values[i];
}
return null;
}
//二分查找,【关键】
private int binarySearch(K key, int down, int up) {
while(down <= up) {
int mid = down + (up-down)/2;
int temp = keys[mid].compareTo(key);
if(temp > 0) {
up = mid-1;
}else if(temp < 0) {
down = mid + 1;
} else {
return mid;
}
}
return down;
}
public static void main(String[] args) {
BinarySearchST<String, Integer> st = new BinarySearchST<>(10);
st.put("AA", 2);
st.put("BB", 2);
System.out.println(st.get("BB"));
}
}
二分查找的时间复杂度为O(logN)
4、插值查找
插值查找(Interpolation Search)是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法。其前提条件是符号表有序。
插值查找的关键是将二分查找中

代码:
private int binarySearch(K key, int down, int up) {
while(down <= up) {
int mid = down + (key-keys[down])/(keys[up]-keys[down])*(up-down);
int temp = keys[mid].compareTo(key);
if(temp > 0) {
up = mid-1;
}else if(temp < 0) {
down = mid + 1;
} else {
return mid;
}
}
return down;
}
对于表长较大,且关键字分布比较均匀的符号表,插值查找的性能比二分查找要好的多。
5、二叉查找树
二叉查找树(Binary Search Tree),又称二叉排序树。它是一棵二叉树,其中每个结点的键都大于其左子树中任意结点的键而小于其右子树中任意结点的键。
代码:
//二叉查找树
public class BST <K extends Comparable<K>, V>
implements ST<K, V> {
private Node root; //二叉树的根结点
private class Node {
K key; //键
V value; //值
Node left, right; //左右子树
int N; //以该结点为根的结点总数
public Node(K key, V value, int n) {
this.key = key;
this.value = value;
N = n;
}
}
@Override
public void put(K key, V value) {
root = put(root, key, value);
}
//插入操作
private Node put(Node node, K key, V value) {
if(node == null)
return new Node(key,value,1);
int cmp = key.compareTo(node.key);
if(cmp < 0) {
node.left = put(node.left, key, value);
}else if(cmp > 0) {
node.right = put(node.right, key, value);
} else {
node.value = value;
}
node.N = node.left.N + node.right.N + 1; //递归返回时更新N
return node;
}
@Override
public V get(K key) {
return get(root, key);
}
//查找操作
private V get(Node node, K key) {
if(node == null)
return null;
int cmp = key.compareTo(node.key);
if(cmp < 0) {
return get(node.left, key);
}else if(cmp > 0) {
return get(node.right, key);
} else {
return node.value;
}
}
}
插入过程:

在插入操作中,若树为空,就返回一个含有该键值对的新结点,若查找的键小于根结点,则在左子树中插入该键,否则在右子树中插入该键。这样通过递归的方法就能构造出一个二叉查找树。
查找过程:
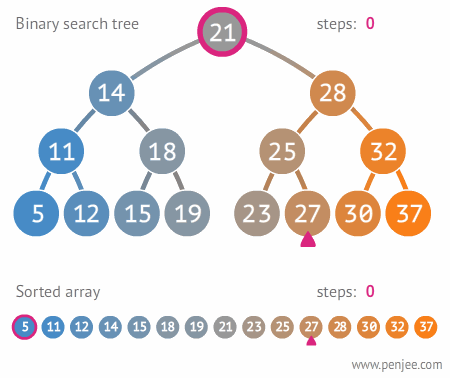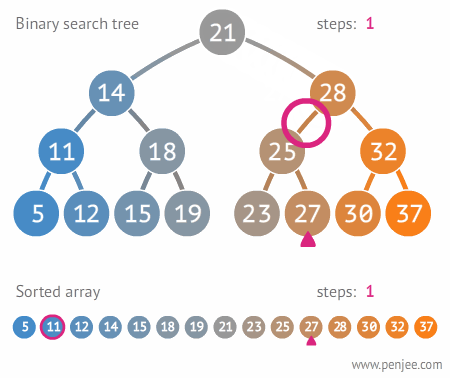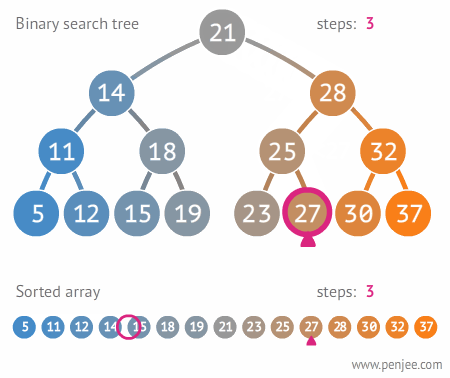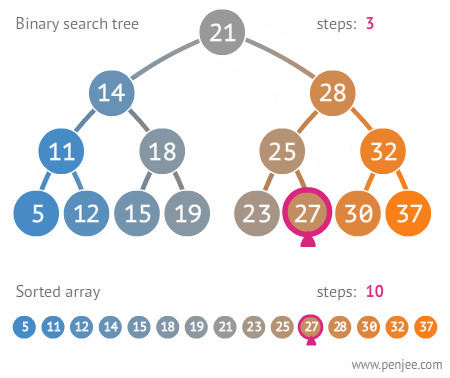
对于查找操作可以使用非递归的方法来提高性能。其代码为:
@Override
public V get(K key) {
Node node = root;
while(node != null) {
int cmp = key.compareTo(node.key);
if(cmp == 0) {
return node.value;
}else if(cmp > 0) {
node = node.right;
}else {
node = node.left;
}
}
return null;
}
删除操作
若要删除的结点是二叉树中的叶子结点,删除它们对整棵树无影响,直接删除即可。若删除的结点是只有左子树或右子树,将它的左子树或右子树整个移动到删除结点的位置即可。如删除二叉树中最小结点的过程:
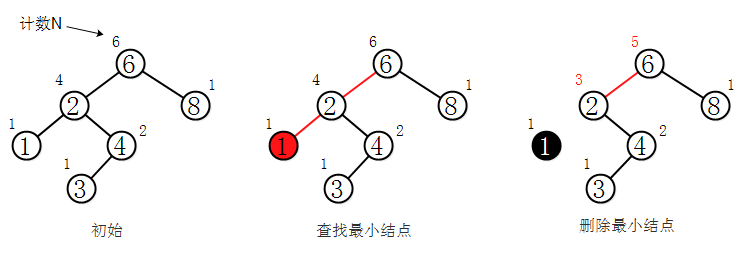
若要删除的的结点 既有左子树又有右子树,只需找到要删除结点的直接前驱或直接后继(即左上树的最大结点或右子树的最小结点)S,用S来替换它 ,然后删除结点S即可。如删除带左右子树的结点2的过程:
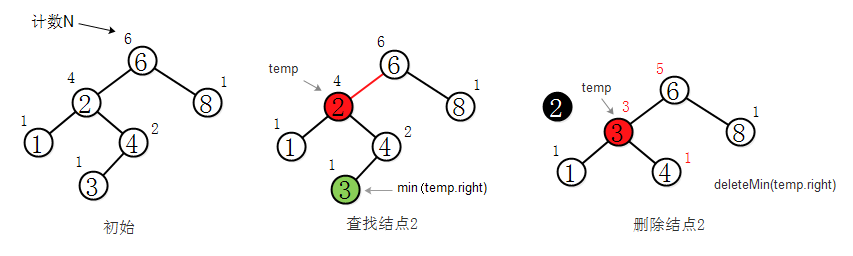
代码如下:
//删除键key及其对应的值
public void delete(K key) {
root = delete(root, key);
}
private Node delete(Node node, K key) {
if(node == null)
return null;
int cmp = key.compareTo(node.key);
if(cmp < 0) {
node.left = delete(node.left, key);
}else if(cmp > 0) {
node.right = delete(node.right, key);
} else {
if(node.left == null) {
return node.right;
}
if(node.right == null) {
return node.left;
}
Node temp = node;
node = min(temp.right);
node.right = deleteMin(temp.right);
node.left = temp.left;
}
node.N = node.left.N + node.right.N + 1; //从栈返回时更新N
return node;
}
//删除一个子树的最小结点
private Node deleteMin(Node node) {
if(node.left == null) { //删除结点node
return node.right;
}
node.left = deleteMin(node.left);
node.N = node.left.N + node.right.N + 1; //更新子树的计数N
return node;
}
//查找一个子树的最小结点
private Node min(Node node) {
if(node.left == null) {
return node;
}
return min(node.left);
}
二叉查找树的性能:
二叉查找树的性能取决于树的形状,而树的形状取决于键被插入的顺序。最好情况下,二叉树是完全平衡的,此时查找和插入的时间复杂度都为O(logN)。最坏情况下,二叉树呈线型,此时查找和插入的时间复杂度都为O(N)。平均情况下,时间复杂度为O(logN)。
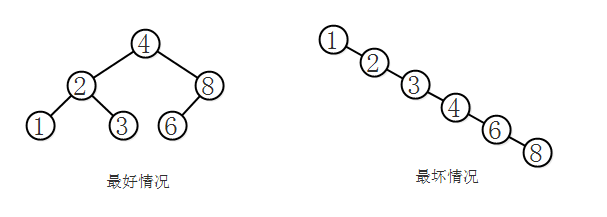
6、平衡查找树
虽然二叉查找树能够很好的用于许多应用中,但它在最坏情况下的性能很糟糕。而平衡查找树的所有操作都能够在对数时间完成。
1、平衡二叉树(AVL树)
平衡二叉树(Self-Balancing Binary Search Tree),是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1。将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF(Balance Factor)。平衡二叉树的BF值只能为-1,0,1。
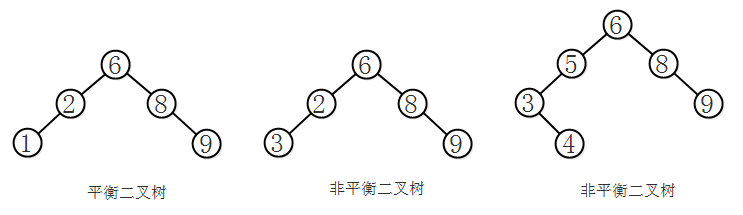
第一幅图是平衡二叉树。在第二幅图中结点2的左结点比结点2大,所以它不是二叉排序树,而平衡二叉树的前提是一个二叉排序树。在第三幅图中结点5的左子树的高度为2,右子树高度为0,BF值为2,不符合平衡二叉树的定义。
平衡二叉树的构建思想:在构建二叉查找树的过程中,每当插入一个结点时,先检查是否因插入而破坏了树的平衡性,若是,则找出最小不平衡子树,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
对不平衡子树的操作有左旋和右旋。
左旋:
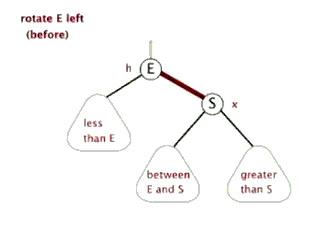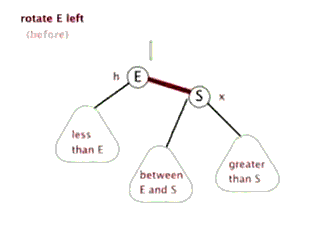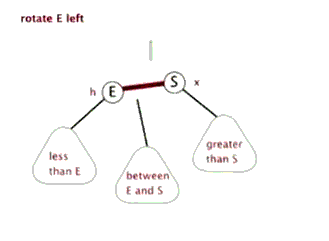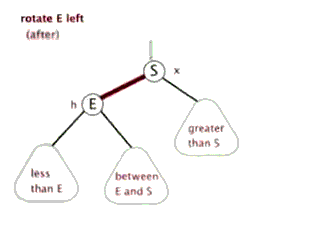
代码:
private Node rotateLeft(Node h) {
Node x = h.right;
h.right = x.left;
x.left = h;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
右旋:
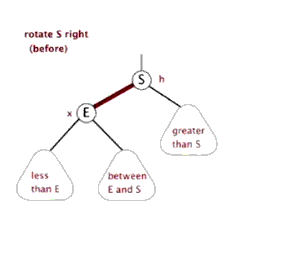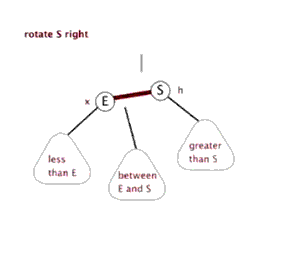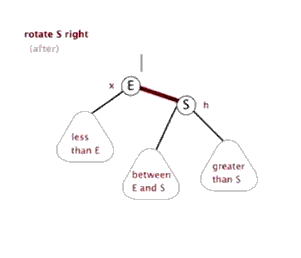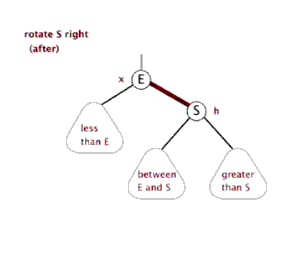
代码:
private Node rotateRight(Node h) {
Node x = h.left;
h.left = x.right;
x.right = h;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
向一棵AVL树中插入一个结点的四种情况:
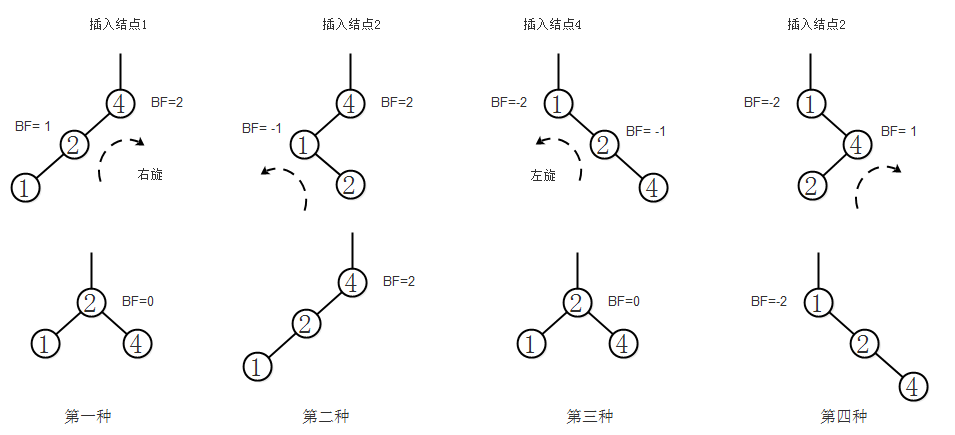
- 第一种:当一个结点的BF值大于等于2,并且它的子结点的BF值为正,则右旋
- 第二种:当一个结点的BF值大于等于2,但它的子结点的BF值为负,对子结点进行左旋操作,变为第一种情况,然后再进行处理。
- 第三种:当一个结点的BF值小于等于-2,并且它的子结点的BF值为负,则左旋
- 第四种:当一个结点的BF值小于等于-2,但它的子结点的BF值为正,对子结点进行右旋操作,变为第三种情况,然后再进行处理。
AVL的实现:
//平衡二叉树(AVL树)的实现
public class AVL<K extends Comparable<K>, V> implements ST<K, V> {
private Node root; // 二叉树的根结点
private class Node {
K key; // 键
V value; // 值
Node left, right; // 左右子树
int N; // 以该结点为根的结点总数
public Node(K key, V value, int n) {
this.key = key;
this.value = value;
N = n;
}
}
// 左旋
private Node rotateLeft(Node h) {
Node x = h.right;
h.right = x.left;
x.left = h;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
// 右旋
private Node rotateRight(Node h) {
Node x = h.left;
h.left = x.right;
x.right = h;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
@Override
public void put(K key, V value) {
root = put(root, key, value);
}
// 插入操作
private Node put(Node node, K key, V value) {
if (node == null)
return new Node(key, value, 1);
int cmp = key.compareTo(node.key);
if (cmp < 0) {
node.left = put(node.left, key, value);
} else if (cmp > 0) {
node.right = put(node.right, key, value);
} else {
node.value = value;
}
if (BF(node) <= -2) {
if (BF(node.right) > 0) {
rotateRight(node.right);
}
rotateLeft(node);
}
if (BF(node) >= 2) {
if (BF(node.left) < 0) {
rotateLeft(node);
}
rotateRight(node);
}
node.N = node.left.N + node.right.N + 1; // 从栈返回时更新N
return node;
}
// 平衡因子BF的值
private int BF(Node node) {
return depth(node.left) - depth(node.right);
}
// 求子树的深度
private int depth(Node node) {
if (node == null)
return 0;
return Math.max(depth(node.right), depth(node.left)) + 1;
}
// 查找操作,和二叉查找树相同
@Override
public V get(K key) {
Node node = root;
while (node != null) {
int cmp = key.compareTo(node.key);
if (cmp == 0) {
return node.value;
} else if (cmp > 0) {
node = node.right;
} else {
node = node.left;
}
}
return null;
}
}
2、2-3查找树
一棵2-3查找树,或为一棵空树,或由以下结点组成:
- 2-结点:含有一个键和两个链接,左链接指向键小于该结点的子树,右链接指向键大于该结点的子树。
- 3-结点:含有两个键和三个链接,左链接指向键都小于该结点的子树,中链接指向键位于该结点两个键之间的子树,右链接指向键大于该结点的子树。
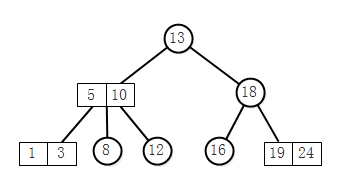
查找:
2-3树的查找操作和平衡二叉树一样,从根结点开始,根据比较结果,到相应的子树中去继续查找,直到命中或查找失败。
插入:
向一棵2-3树中插入一个结点可能的情况
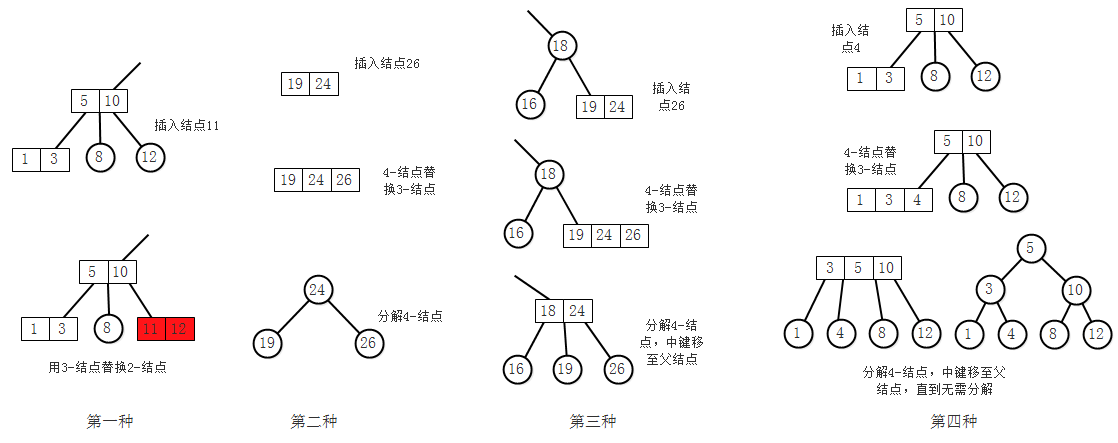
- 第一种:向2-结点中插入新键,只需用一个3-结点替换2-结点即可。
- 第二种:向3-结点中插入新键,这个3-结点没有父结点,此时可将其分解为一个含有3个结点的二叉查找树。
- 第三种:向一个父结点为2-结点的3-结点中插入新键,先将其分解为一个含有3个结点的二叉查找树,然后将中键移到父结点,父结点由2-结点变为3-结点。
- 第四种:向一个父结点为3-结点的3-结点中插入新键,和第三种情况一样,一直向上分解临时的4-结点,直到遇到一个2-结点将它替换为3-结点,或到达3-结点的根,然后直接分解成一个含有3个结点的二叉查找树。如图,此时2-3树依然平衡。
性能:
2-3查找树的插入和查找操作的时间复杂度不超过 O(logN)。
2-3查找树需要维护两种不同的结点,实现起来比较复杂,并且在结点的转换过程中需要大量的复制操作,这些都将产生额外的开销,使的算法的性能可能比二叉查找树要慢。
3、红黑树
红黑树是对2-3查找树的一种改进,它使用标准的二叉查找树和一些额外的信息来表示2-3树。使用两个2-结点和『红链接』来表示一个3-结点。由于每个结点都只有一个指向自己的链接,所以可以在结点中使用boolean值来表示红链接。
红黑树,是满足下列条件的二叉树:
- 红链接均为左链接,即红色结点必须为左结点。
- 没有任何结点同时和两个红链接相连,即不存在左右子结点都为红的结点。
- 任何空链接到根节点的路径上的黑链接(黑结点)数量相同。
- 根结点总是黑色的。
2-3查找树与红黑树的对应关系

红黑树的左旋和右旋操作,与平衡二叉树(AVL树)的基本相同,只需注意旋转后的结点颜色的变化即可。其代码等下会给出。
向一个2-结点中插入结点的情况:
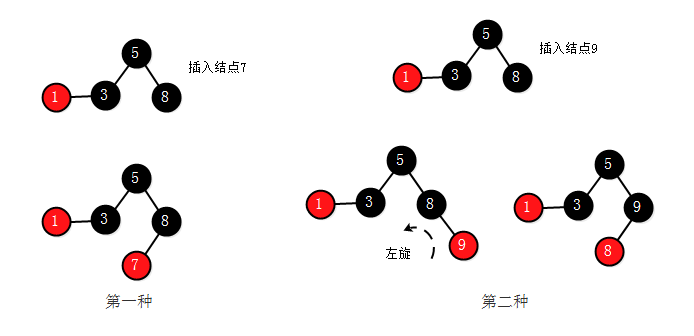
向一个2-结点中插入结点比较简单,和平衡二叉树基本相同,这里需要注意,第二种情况,由于红黑树的红色结点必须为左结点,所以这里需要一个左旋操作,将右结点变为左结点。
向一个3-结点中插入结点的情况:
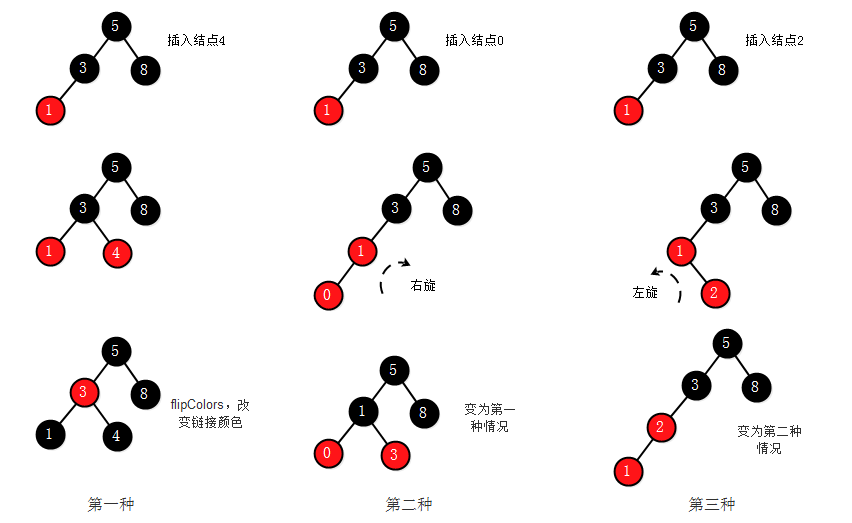
向一个3-结点中插入结点,由红黑树的定义,结点不能和两个红色结点相连并且红色结点必须为左结点,所以需要做相应的旋转操作。这里需要注意第一种情况中,对左右结点均为红色时的颜色转换,处理后红色向上传递,这可能会使上层结点的左右结点均为红色,这时需要对上层继续进行颜色转换,直到根结点或不出现左右结点均为红的情况。
代码实现:
//红黑树的实现
public class RedBlackBST <K extends Comparable<K>, V> implements ST<K, V> {
private static final boolean RED = true;
private static final boolean BLACK = false;
private Node root; // 二叉树的根结点
private class Node {
K key; // 键
V value; // 值
Node left, right; // 左右子树
int N; // 以该结点为根的结点总数
//由于每个结点都只有一个指向自己的链接,所以可以在结点中使用boolean值来表示红链接。
boolean color;
public Node(K key, V value, int n, boolean color) {
this.key = key;
this.value = value;
N = n;
this.color = color;
}
}
private boolean isRed(Node node) {
if(node == null)
return false;
return node.color == RED;
}
// 左旋
private Node rotateLeft(Node h) {
Node x = h.right;
h.right = x.left;
x.left = h;
x.color = h.color;
h.color = RED;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
// 右旋
private Node rotateRight(Node h) {
Node x = h.left;
h.left = x.right;
x.right = h;
x.color = h.color;
h.color = RED;
x.N = h.N;
h.N = h.left.N + h.right.N + 1;
return x;
}
@Override
public void put(K key, V value) {
root = put(root, key, value);
root.color = BLACK; //根节点总是黑色的,因为它没有父链接
}
// 插入操作
private Node put(Node node, K key, V value) {
if (node == null)
return new Node(key, value, 1,RED);
int cmp = key.compareTo(node.key);
if (cmp < 0) {
node.left = put(node.left, key, value);
} else if (cmp > 0) {
node.right = put(node.right, key, value);
} else {
node.value = value;
}
if(isRed(node.right) && !isRed(node.left)) {
node = rotateLeft(node);
}
if(isRed(node.left) && isRed(node.left.left)) {
node = rotateRight(node);
}
if(isRed(node.left) && isRed(node.right)) {
flipColors(node);
}
node.N = node.left.N + node.right.N + 1; // 从栈返回时更新N
return node;
}
//颜色转换
private void flipColors(Node node) {
node.color = RED;
node.left.color = BLACK;
node.right.color = BLACK;
}
// 查找操作,和二叉查找树一样
@Override
public V get(K key) {
Node node = root;
while (node != null) {
int cmp = key.compareTo(node.key);
if (cmp == 0) {
return node.value;
} else if (cmp > 0) {
node = node.right;
} else {
node = node.left;
}
}
return null;
}
}
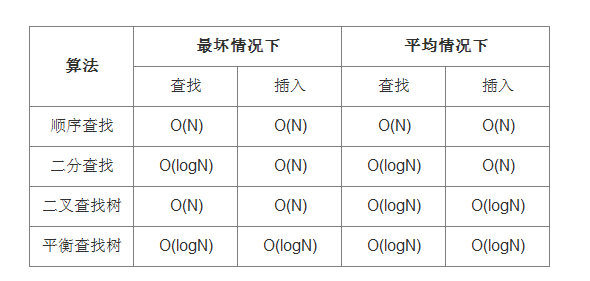
7、性能比较
性能如下图:
关于红黑树的删除,今天看了好久,也没完全弄明白,这里就不写出来误人子弟了,感兴趣的可以看下这篇博客。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号