数据结构与算法(六),图
图是一种比线性表和树更复杂的数据结构,在图中,结点之间的关系是任意的,任意两个数据元素之间都可能相关。图是一种多对多的数据结构。
1、基本概念
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
注意:线性表中可以没有元素,称为空表。树中可以没有结点,叫做空树。但是在图中不允许没有顶点,可以没有边。
基本术语:
-
无向边:若顶点Vi和Vj之间的边没有方向,称这条边为无向边(Edge),用
(Vi,Vj)来表示。 -
无向图(Undirected graphs):图中任意两个顶点的边都是无向边。
-
有向边:若从顶点Vi到Vj的边有方向,称这条边为有向边,也称为弧(Arc),用
<Vi, Vj>来表示,其中Vi称为弧尾(Tail),Vj称为弧头(Head)。 -
有向图(Directed graphs):图中任意两个顶点的边都是有向边。
-
简单图:不存在自环(顶点到其自身的边)和重边(完全相同的边)的图
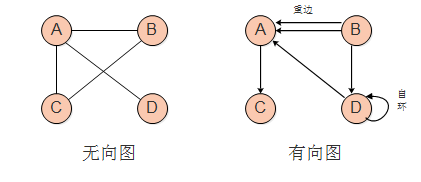
-
无向完全图:无向图中,任意两个顶点之间都存在边。
-
有向完全图:有向图中,任意两个顶点之间都存在方向相反的两条弧。
-
稀疏图;有很少条边或弧的图称为稀疏图,反之称为稠密图。
-
权(Weight):表示从图中一个顶点到另一个顶点的距离或耗费。
-
网:带有权重的图
-
度:与特定顶点相连接的边数;
-
出度、入度:有向图中的概念,出度表示以此顶点为起点的边的数目,入度表示以此顶点为终点的边的数目;
-
环:第一个顶点和最后一个顶点相同的路径;
-
简单环:除去第一个顶点和最后一个顶点后没有重复顶点的环;
-
连通图:任意两个顶点都相互连通的图;
-
极大连通子图:包含竟可能多的顶点(必须是连通的),即找不到另外一个顶点,使得此顶点能够连接到此极大连通子图的任意一个顶点;
-
连通分量:极大连通子图的数量;
-
强连通图:此为有向图的概念,表示任意两个顶点a,b,使得a能够连接到b,b也能连接到a 的图;
-
生成树:n个顶点,n-1条边,并且保证n个顶点相互连通(不存在环);
-
最小生成树:此生成树的边的权重之和是所有生成树中最小的;
-
AOV网(
Activity On Vertex Network ):在有向图中若以顶点表示活动,有向边表示活动之间的先后关系 -
AOE网(
Activity On Edge Network):在带权有向图中若以顶点表示事件,有向边表示活动,边上的权值表示该活动持续的时间
2、图的存储结构
由于图的结构比较复杂,任意两个顶点之间都可能存在关系,因此用简单的顺序存储来表示图是不可能,而若使用多重链表的方式(即一个数据域多个指针域的结点来表示),这将会出现严重的空间浪费或操作不便。这里总结一下常用的表示图的方法:
2.1、邻接矩阵
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称邻接矩阵)存储图中的边或弧的信息。
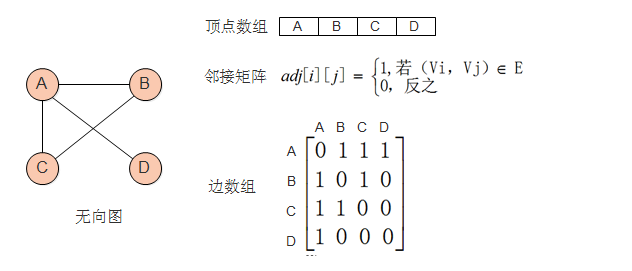
无向图由于边不区分方向,所以其邻接矩阵是一个对称矩阵。邻接矩阵中的0表示边不存在,主对角线全为0表示图中不存在自环。
带权有向图的邻接矩阵:

在带权有向图的邻接矩阵中,数字表示权值weight,「无穷」表示弧不存在。由于权值可能为0,所以不能像在无向图的邻接矩阵中那样使用0来表示弧不存在。
代码:
/**
* 有向图的邻接矩阵实现
*/
public class Digraph {
private int vertexsNum;
private int edgesNum;
private int[][] arc;
public Digraph(int[][] data, int vertexsNum) {
this.vertexsNum = vertexsNum;
this.edgesNum = data.length;
arc = new int[vertexsNum][vertexsNum];
for (int i = 0; i < vertexsNum; i++) {
for (int j = 0; j < vertexsNum; j++) {
arc[i][j] = Integer.MAX_VALUE;
}
}
for (int i = 0; i < data.length; i++) {
int tail = data[i][0];
int head = data[i][1];
arc[tail][head] = 1;
}
}
//用于测试,返回一个顶点的邻接点
public Iterable<Integer> adj(int vertex) {
Set<Integer> set = new HashSet<>();
for (int i = 0; i < vertexsNum; i++) {
if (arc[vertex][i] != Integer.MAX_VALUE)
set.add(i);
}
return set;
}
public static void main(String[] args) {
int[][] data = {
{0,3},
{1,0},
{1,2},
{2,0},
{2,1},
};
Digraph wd = new Digraph(data,4);
for(int i :wd.adj(1)) {
System.out.println(i);
}
}
}
优缺点:
- 优点:结构简单,操作方便
- 缺点:对于稀疏图,这种实现方式将浪费大量的空间。
2.2、邻接表
邻接表是一种将数组与链表相结合的存储方法。其具体实现为:将图中顶点用一个一维数组存储,每个顶点Vi的所有邻接点用一个单链表来存储。这种方式和树结构中孩子表示法一样。
对于有向图其邻接表结构如下:
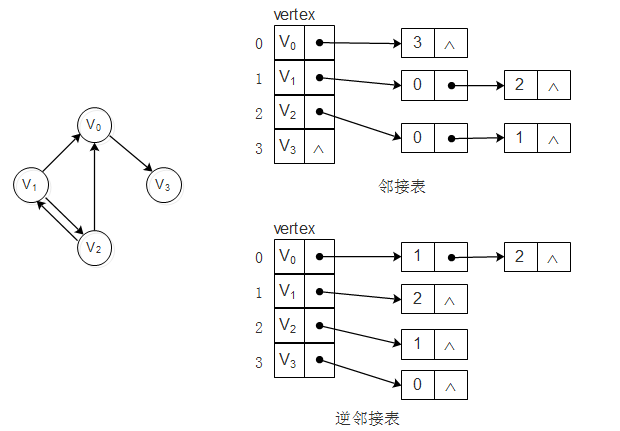
有向图的邻接表是以顶点为弧尾来存储边表的,这样很容易求一个顶点的出度(顶点对应单链表的长度),但若求一个顶点的入度,则需遍历整个图才行。这时可以建立一个有向图的逆邻接表即对每个顶点v都建立一个弧头尾v的单链表。如上图所示。
代码:
/**
* 有向图的邻接表实现
*
*/
public class AdjListDigraph {
private class EdgeNode {
int index;
EdgeNode next;
EdgeNode(int index, EdgeNode next){
this.index = index;
this.next = next;
}
}
private class VertexNode {
int id;
EdgeNode headNode;
}
private VertexNode[] vertexs;
private int vertexsNum;
private int edgesNum;
public AdjListDigraph(int[][] data, int vertexsNum) {
this.vertexsNum = vertexsNum;
this.edgesNum = data.length;
vertexs = new VertexNode[vertexsNum];
for (int i = 0; i < vertexs.length; i++) {
vertexs[i] = new VertexNode();
vertexs[i].id = i; //
}
for (int i = 0; i < data.length; i++) {
int index = data[i][1];
EdgeNode next = vertexs[data[i][0]].headNode;
EdgeNode eNode = new EdgeNode(index,next);
vertexs[data[i][0]].headNode = eNode; //头插法
}
}
//用于测试,返回一个顶点的邻接点
public Iterable<Integer> adj(int index) {
Set<Integer> set = new HashSet<>();
EdgeNode current = vertexs[index].headNode;
while(current != null) {
VertexNode node = vertexs[current.index];
set.add(node.id);
current = current.next;
}
return set;
}
public static void main(String[] args) {
int[][] data = {
{0,3},
{1,0},
{1,2},
{2,0},
{2,1},
};
AdjListDigraph ald = new AdjListDigraph(data,4);
for(int i :ald.adj(1)) {
System.out.println(i);
}
}
}
本算法的时间复杂度为 O(N + E),其中N、E分别为顶点数和边数,邻接表实现比较适合表示稀疏图。
2.3、十字链表
十字链表(Orthogonal List)是将邻接表和逆邻接表相结合的存储方法,它解决了邻接表(或逆邻接表)的缺陷,即求入度(或出度)时必须遍历整个图。
十字链表的结构如下:
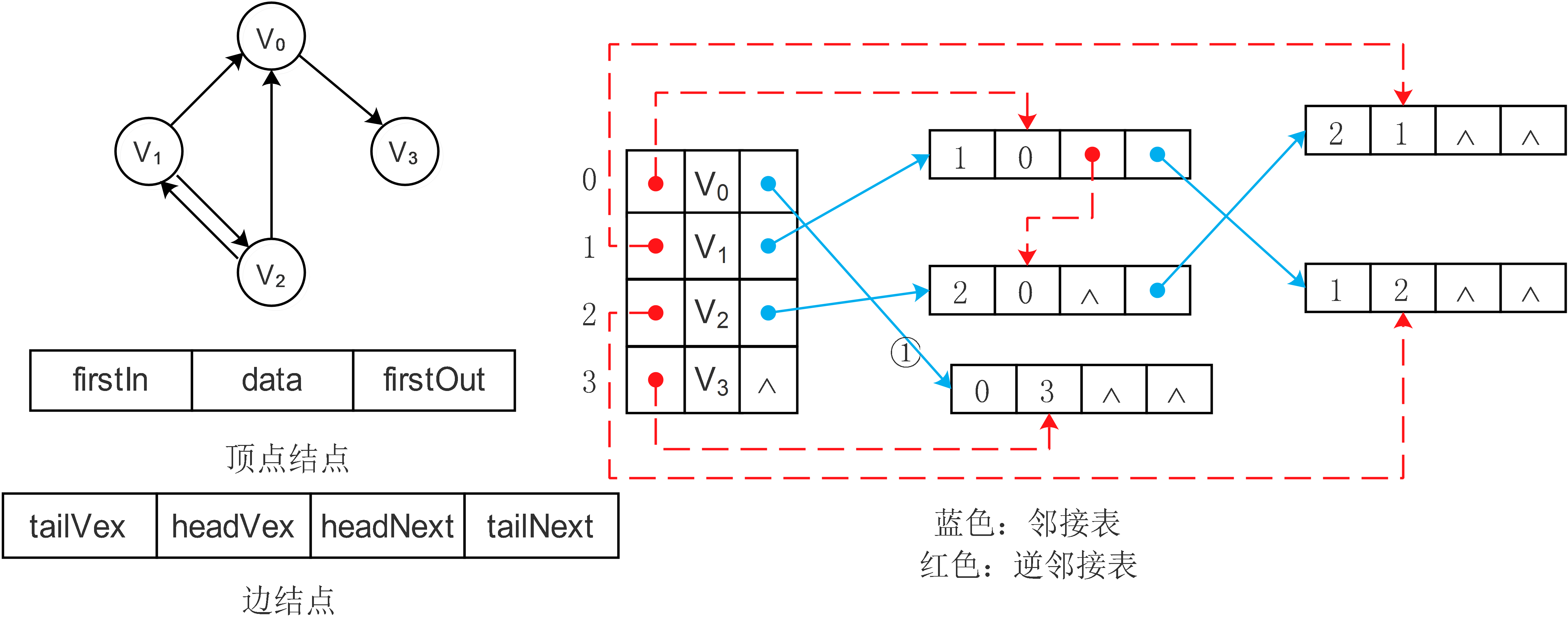
图中:
- firstIn表示入边表(即是逆邻接表中的单链表)头指针,firstOut表示出边表(即是邻接表中的单链表)头指针,data表示顶点数据。
- tailVex表示边的起点在顶点数组中的下标,tailNext值出边表指针域,指向起点相同的下一条边。
- headVex表示边的终点在顶点数组中的下标,headNext指入边表指针域,指向终点相同的下一条边。
代码实现:
/**
* 有向图的十字链表实现
*
*/
public class OrthogonalList {
private class EdgeNode {
int tailVex;
int headVex;
EdgeNode headNext;
EdgeNode tailNext;
public EdgeNode(int tailVex, int headVex, EdgeNode headNext, EdgeNode tailNext) {
super();
this.tailVex = tailVex;
this.headVex = headVex;
this.headNext = headNext;
this.tailNext = tailNext;
}
}
private class VertexNode {
int data;
EdgeNode firstIn;
EdgeNode firstOut;
}
private VertexNode[] vertexs;
private int vertexsNum;
private int edgesNum;
public OrthogonalList(int[][] data, int vertexsNum) {
this.vertexsNum = vertexsNum;
this.edgesNum = data.length;
vertexs = new VertexNode[vertexsNum];
for (int i = 0; i < vertexs.length; i++) {
vertexs[i] = new VertexNode();
vertexs[i].data = i; //
}
//关键
for (int i = 0; i < data.length; i++) {
int tail = data[i][0];
int head = data[i][1];
EdgeNode out = vertexs[tail].firstOut;
EdgeNode in = vertexs[head].firstIn;
EdgeNode eNode = new EdgeNode(tail,head,in,out);
vertexs[tail].firstOut = eNode;
vertexs[head].firstIn = eNode;
}
}
//返回一个顶点的出度
public int outDegree(int index) {
int result = 0;
EdgeNode current = vertexs[index].firstOut;
while(current != null) {
current = current.tailNext;
result++;
}
return result;
}
//返回一个顶点的入度
public int inDegree(int index) {
int result = 0;
EdgeNode current = vertexs[index].firstIn;
while(current != null) {
current = current.headNext;
result++;
}
return result;
}
public static void main(String[] args) {
int[][] data = {
{0,3},
{1,0},
{1,2},
{2,0},
{2,1},
};
OrthogonalList orth = new OrthogonalList(data,4);
System.out.println("顶点1的出度为" + orth.outDegree(1));
System.out.println("顶点1的入度为" + orth.inDegree(1));
}
}
十字链表创建图算法的时间复杂度和邻接表相同都为O(N + E)。在有图的应用中推荐使用。
3、图的遍历
从图的某个顶点出发,遍历图中其余顶点,且使每个顶点仅被访问一次,这个过程叫做图的遍历(Traversing Graph)。对于图的遍历通常有两种方法:深度优先遍历和广度优先遍历。
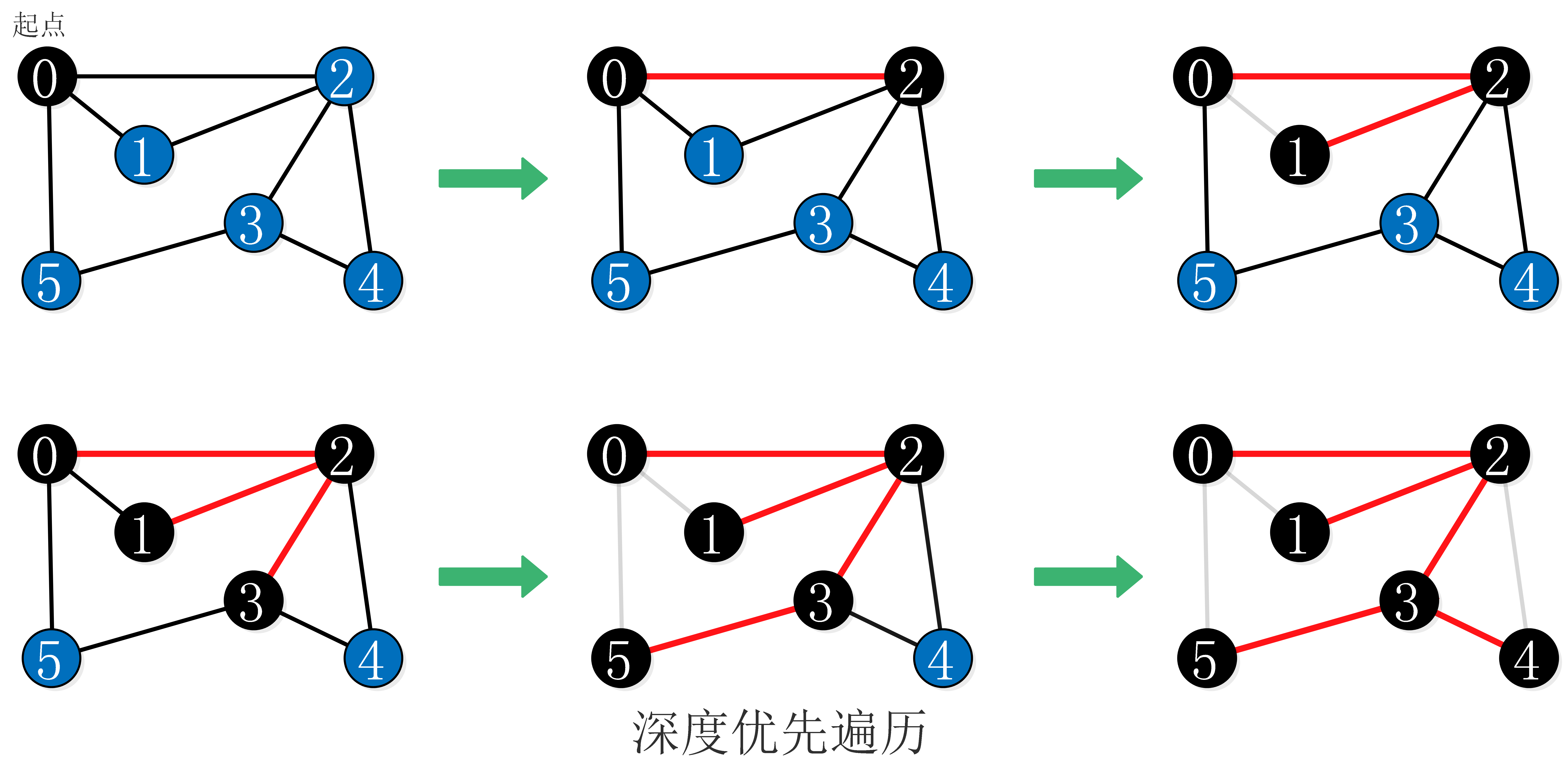
3.1、深度优先遍历
深度优先遍历(Depth First Search,简称DFS),也成为深度优先搜索。
遍历思想:基本思想:首先从图中某个顶点v0出发,访问此顶点,然后依次从v相邻的顶点出发深度优先遍历,直至图中所有与v路径相通的顶点都被访问了;若此时尚有顶点未被访问,则从中选一个顶点作为起始点,重复上述过程,直到所有的顶点都被访问。
深度优先遍历用递归实现比较简单,只需用一个递归方法来遍历所有顶点,在访问某一个顶点时:
- 将它标为已访问
- 递归的访问它的所有未被标记过的邻接点
深度优先遍历的过程:
代码如下:
public class DFSTraverse {
private boolean[] visited;
//从顶点index开始遍历
public DFSTraverse(Digraph graph, int index) {
visited = new boolean[graph.getVertexsNum()];
dfs(graph,index);
}
private void dfs(Digraph graph, int index) {
visited[index] = true;
for(int i : graph.adj(index)) {
if(!visited[i])
dfs(graph,i);
}
}
}
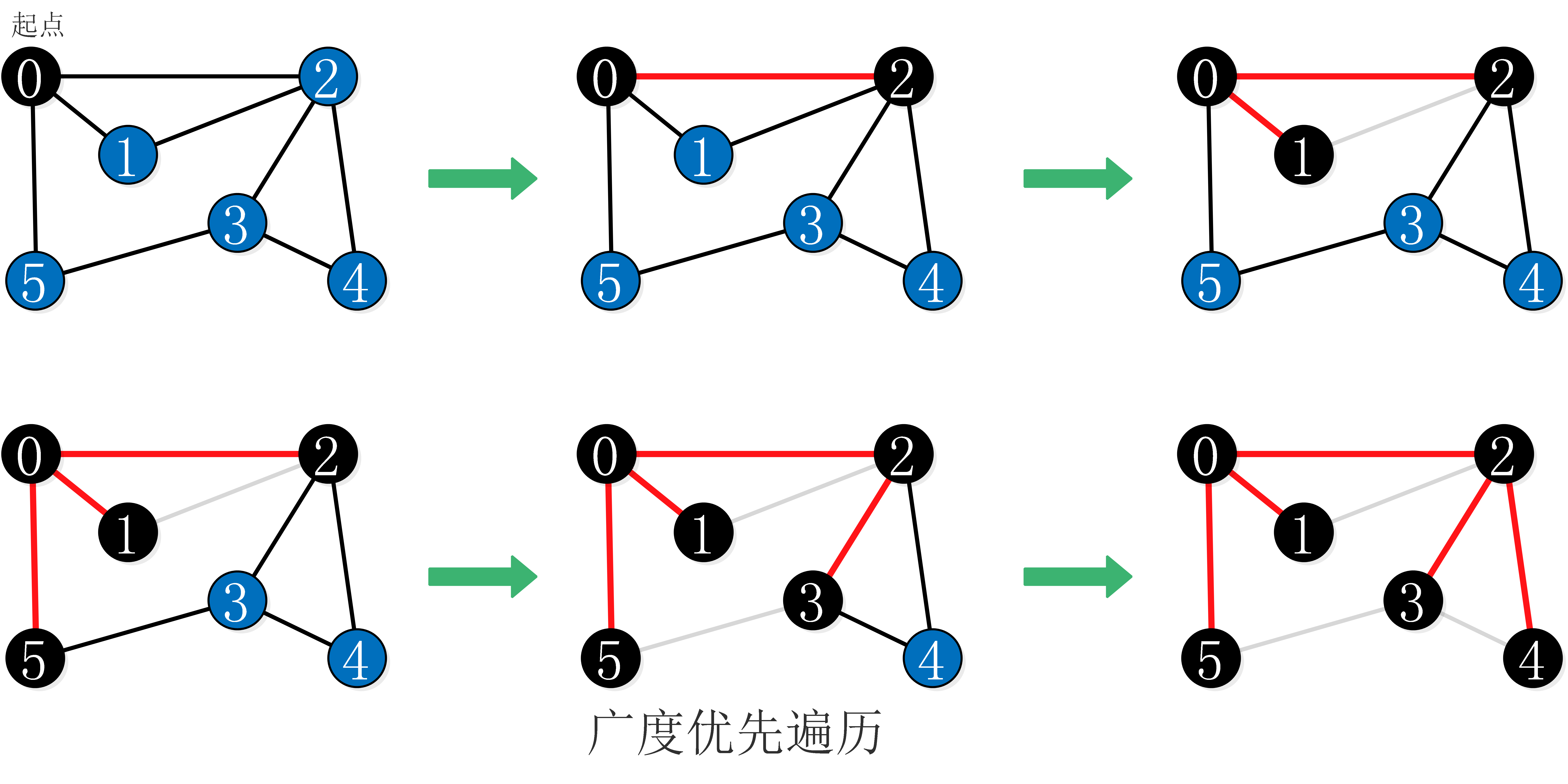
3.2、广度优先遍历
广度优先遍历(Breadth First Search,简称BFS),又称为广度优先搜索
遍历思想:首先,从图的某个顶点v0出发,访问了v0之后,依次访问与v0相邻的未被访问的顶点,然后分别从这些顶点出发,广度优先遍历,直至所有的顶点都被访问完。
广度优先遍历的过程:
代码:
public class BFSTraverse {
private boolean[] visited;
public BFSTraverse(AdjListDigraph graph, int index) {
visited = new boolean[graph.getVertexsNum()];
bfs(graph,index);
}
private void bfs(AdjListDigraph graph, int index) {
//在JSE中LinkedList实现了Queue接口
Queue<Integer> queue = new LinkedList<>();
visited[index] = true;
queue.add(index);
while(!queue.isEmpty()) {
int vertex = queue.poll();
for(int i : graph.adj(vertex)) {
if(!visited[i]) {
visited[i] = true;
queue.offer(i);
}
}
}
}
}
4、最小生成树
图的生成树是它的一棵含有所有顶点的无环连通子图。一棵加权图的最小生成树(MST)是它的一棵权值(所有边的权值之和)最小的生成树。
计算最小生成树可能遇到的情况:
- 非连通的无向图,不存在最小生成树
- 权重不一定和距离成正比
- 权重可能是0或负数
- 若存在相等的权重,那么最小生成树可能不唯一
图的切分是将图的所有顶点分为两个非空且不重叠的两个集合。横切边是一条连接两个属于不同集合的顶点的边。
切分定理:在一幅加权图中,给定任意的切分,它的横切边中的权重最小者必然属于图的最小生成树。
切分定理是解决最小生成树问题的所有算法的基础。这些算法都是贪心算法。

首先先构造一个带权的无向图,其代码如下:
//定义边
public class Edge implements Comparable<Edge>{
private final int ver1;
private final int ver2;
private final Integer weight;
public Edge(int ver1, int ver2, int weight) {
super();
this.ver1 = ver1;
this.ver2 = ver2;
this.weight = weight;
}
//返回一个顶点
public int either() {
return ver1;
}
//返回另一个顶点
public int other(int vertex) {
if (vertex == ver1)
return ver2;
else if(vertex == ver2)
return ver1;
else
throw new RuntimeException("边不一致");
}
@Override
public int compareTo(Edge e) {
return this.weight.compareTo(e.weight);
}
public Integer getWeight() {
return weight;
}
@Override
public String toString() {
return "Edge [" + ver1 + "," + ver2 +"]";
}
}
/**
* 带权无向图的实现
*/
public class WeightedGraph {
private final int vertexsNum;
private final int edgesNum;
private List<Edge>[] adj;
public WeightedGraph(int[][] data, int vertexsNum) {
this.vertexsNum = vertexsNum;
this.edgesNum = data.length;
adj = (List<Edge>[]) new ArrayList[vertexsNum];
for(int i=0; i<vertexsNum; i++) {
adj[i] = new ArrayList<>();
}
for (int i = 0; i < data.length; i++) {
Edge edge = new Edge(data[i][0],data[i][1],data[i][2]);
int v = edge.either();
adj[v].add(edge);
adj[edge.other(v)].add(edge);
}
}
public Iterable<Edge> adj(int vertex) {
return adj[vertex];
}
public int getVertexsNum() {
return vertexsNum;
}
public int getEdgesNum() {
return edgesNum;
}
public Iterable<Edge> getEdges() {
List<Edge> edges = new ArrayList<>();
for(int i=0; i<vertexsNum; i++) {
for(Edge e : adj[i]) {
if(i > e.other(i)) { //无向图,防止将一条边加入两次
edges.add(e);
}
}
}
return edges;
}
}
4.1、Prim算法
每次将权值最小的横切边加入生成树中
1)、Prim算法的延迟实现
实现过程如下图:
从顶点0开始,首先将顶点0加入到树中(标记),顶点0和其它点的横切边(这里即为顶点0的邻接边)加入优先队列,将权值最小的横切边出队,加入生成树中。此时相当于也向树中添加了一个顶点2,接着将集合(顶点1,2组成)和另一个集合(除1,2的顶点组成)间的横切边加入到优先队列中,如此这般,直到队列为空。
注意:若横切边中另一个顶点在树中,则此边失效。
代码如下:
public class LazyPrimMST {
private boolean[] visited; //标记顶点
private LinkedQueue<Edge> mst; //存储最小生成树的边
private MinPQ<Edge> pq; //优先队列,权值越最小优先级越高
public LazyPrimMST(WeightedGraph wg) {
visited = new boolean[wg.getVertexsNum()];
mst = new LinkedQueue<Edge>();
pq = new MinPQ<>(wg.getVertexsNum());
visit(wg, 0); //从0点开始
while(!pq.isEmpty()) {
Edge e = pq.deQueue();
int ver1 = e.either();
int ver2 = e.other(ver1);
if(visited[ver1] && visited[ver2]) {
continue; //边失效
}
mst.enQueue(e);
if(!visited[ver1])
visit(wg, ver1);
if(!visited[ver2])
visit(wg, ver2);
}
}
private void visit(WeightedGraph wg, int ver) {
visited[ver] = true; //标记顶点
for(Edge e : wg.adj(ver)) {
if(!visited[e.other(ver)])
pq.enQueue(e);
}
}
public Iterable<Edge> getMST() {
return mst;
}
public static void main(String[] args) {
int[][] data = {
{0, 2, 2},
{0, 1, 4},
{0, 5, 5},
{1, 2, 3},
{1, 5, 11},
{1, 3, 7},
{2, 3, 8},
{2, 4, 10},
{3, 5, 6},
{3, 4, 1},
{4, 5, 9}
};
WeightedGraph wg = new WeightedGraph(data,6);
LazyPrimMST lpm = new LazyPrimMST(wg);
for(Edge e : lpm.getMST()) {
System.out.println(e);
}
}
}
其中,LinkedQueue类的代码在《数据结构与算法(三),栈与队列》中;而MinPQ类的代码与《数据结构与算法(五),优先队列》中MaxPQ类的代码几乎一样,只需将方法less中的小于号改为大于号即可。这里就不在给出代码了
此方法的时间复杂度为 O(ElogE),空间复杂度为 O(E)。其中,V为顶点个数,E为边数
2)、Prim算法即时实现
基于Prim算法的延迟实现,我们可以在优先队列中只保存每个非树顶点V的一条边(即它与树中的顶点连接起来的权重最小的那条边),因为其他权重较大的边迟早都会失效。
实现过程如下图:
代码实现:
/**
* prim的即时实现
*/
public class PrimMST {
private Edge[] edgeTo; //点离生成树最近的边
private int[] distTo; //点到生成树的距离
private boolean[] visited;
private IndexMinPQ<Integer> pq; //索引优先队列,关联顶点与distTo
public PrimMST(WeightedGraph wg) {
//初始化
edgeTo = new Edge[wg.getVertexsNum()];
distTo = new int[wg.getVertexsNum()];
visited = new boolean[wg.getVertexsNum()];
for(int i=0; i<wg.getVertexsNum(); i++) {
distTo[i] = Integer.MAX_VALUE;
}
pq = new IndexMinPQ<>(wg.getVertexsNum());
distTo[0] = 0;
pq.insert(0, 0);
while(!pq.isEmpty()) {
visit(wg, pq.delMin());
}
}
private void visit(WeightedGraph wg, int ver) {
visited[ver] = true;
for(Edge e : wg.adj(ver)) {
int vertex = e.other(ver); //边的另一个点
if(visited[vertex])
continue;
if(e.getWeight() < distTo[vertex]) {
edgeTo[vertex] = e; //被覆盖的边失效
distTo[vertex] = e.getWeight();
if(pq.contains(vertex)) {
pq.change(vertex, distTo[vertex]);
}else {
pq.insert(vertex, distTo[vertex]);
}
}
}
}
public Iterable<Edge> getMST() {
return Arrays.asList(edgeTo);
}
}
此方法的时间复杂度为 O(ElogV),空间复杂度为 O(V)。其中,V为顶点个数,E为边数。
可以看出Prim算法的即时实现比延迟实现明显要快,特别是对于稠密矩阵(E>>>V)的情况。
4.2、Kruskal算法
Kruskal算法的思想是按照边的权重顺序来生成最小生成树,首先将图中所有边加入优先队列,将权重最小的边出队加入最小生成树,保证加入的边不与已经加入的边形成环,直到树中有V-1到边为止。
实现过程如下图:
/**
* Kruskal算法的实现
*/
public class KruskalMST {
private List<Edge> mst; //存储最小生成树的边
private MinPQ<Edge> pq; //优先队列
private int[] parent; //用来判断边与边是否形成回路
public KruskalMST(WeightedGraph wg) {
mst = new ArrayList<Edge>();
pq = new MinPQ<>(wg.getEdgesNum());
parent = new int[wg.getVertexsNum()];
for(Edge e : wg.getEdges()) {
pq.enQueue(e);
}
//最小生成树的边最多为V-1个
while(!pq.isEmpty() && mst.size() < wg.getVertexsNum() - 1) {
Edge e = pq.deQueue();
int v = e.either();
int n = find(parent, v);
int m = find(parent, e.other(v));
if(n != m) { //表示此边没有与生成树形成环路
parent[n] = m;
mst.add(e);
}
}
}
//查找连接树的尾部下标
private int find(int[] data, int v) {
while(parent[v] > 0) {
v = parent[v];
}
return v;
}
public Iterable<Edge> getMST() {
return mst;
}
}
Kruskal算法的时间复杂度最坏情况下为O(ElogE)。空间复杂度为O(E)。
对比Prim算法和Kruskal算法,Kruskal算法主要根据边来生成树,边数少时效率比较高,适合稀疏图;而Prim算法对边数多的稠密图效果更好一些。
5、最短路径
最短路径指两顶点之间经过的边上权值之和最少的路径,并且称路径上的第一个顶点为源点,最后一个顶点为终点。
为了操作方便,首先使用面向对象的方法,来实现一个加权的有向图,其代码如下:
/**
* 有向边
*/
public class Edge{
private final int from;
private final int to;
private final int weight;
public Edge(int from, int to, int weight) {
super();
this.from = from;
this.to = to;
this.weight = weight;
}
public int getFrom() {
return from;
}
public int getTo() {
return to;
}
public int getWeight() {
return weight;
}
}
//带权有向图的实现
public class WeightedDigraph {
private final int vertexsNum;
private final int edgesNum;
private List<Edge>[] adj; //邻接表
public WeightedDigraph(int[][] data, int vertexsNum) {
this.vertexsNum = vertexsNum;
this.edgesNum = data.length;
adj = (List<Edge>[]) new ArrayList[vertexsNum];
for(int i=0; i<vertexsNum; i++) {
adj[i] = new ArrayList<>();
}
for (int i = 0; i < data.length; i++) {
Edge edge = new Edge(data[i][0],data[i][1],data[i][2]);
int v = edge.getFrom();
adj[v].add(edge);
}
}
public Iterable<Edge> adj(int vertex) {
return adj[vertex];
}
public int getVertexsNum() {
return vertexsNum;
}
public int getEdgesNum() {
return edgesNum;
}
//有向图中所有的边
public Iterable<Edge> getEdges() {
List<Edge> edges = new ArrayList<>();
for(List<Edge> list : adj) {
for(Edge e : list) {
edges.add(e);
}
}
return edges;
}
}
顶点到源点s的最短路径,我们使用一个用顶点索引的Edge数组(edgeTo[])来存储,使用数组distTo[]来存储最短路径树(包含了源点S到所有可达顶点的最短路径)。
边的松弛操作:
边的松弛过程如下图:
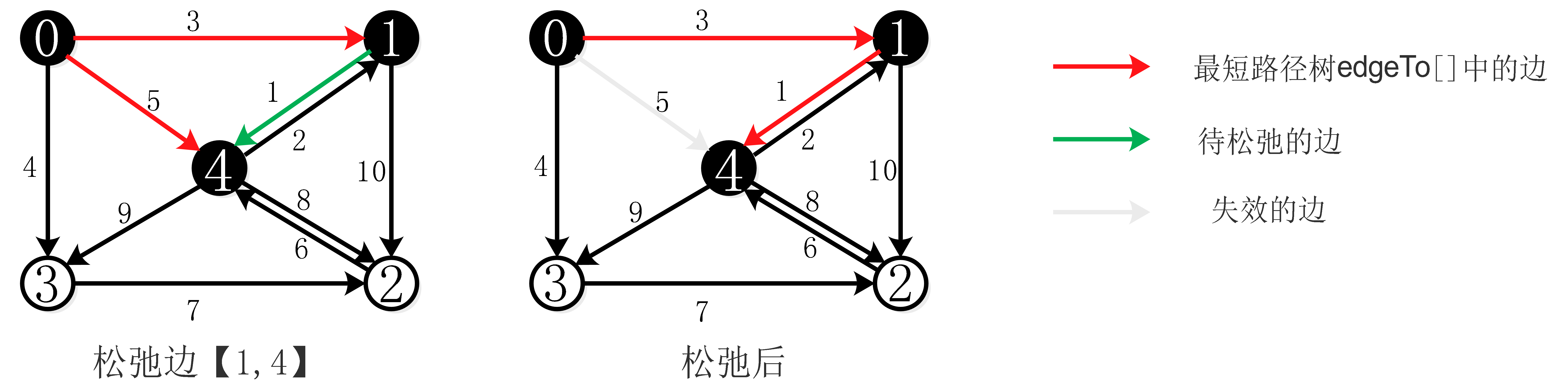
松弛边【1,4】就是检查顶点0到4的最短路径是否是先从顶点0到1,然后在由顶点1到4。如果是则【0,4】边失效,将【1,4】加入最短路径树。
代码:
private void relax(WeightedDigraph wd,Edge e) {
int v = e.getFrom();
int w = e.getTo();
if(distTo[w] > distTo[v] + e.getWeight()) {
distTo[w] = distTo[v] + e.getWeight();
edgeTo[w] = e;
}
}
顶点的松弛操作:
顶点的松弛就是松弛顶点的所有邻接边,这里就不给出过程了,实现代码在Dijkstra实现中。
5.1、Dijkstra算法
算的的实现过程:
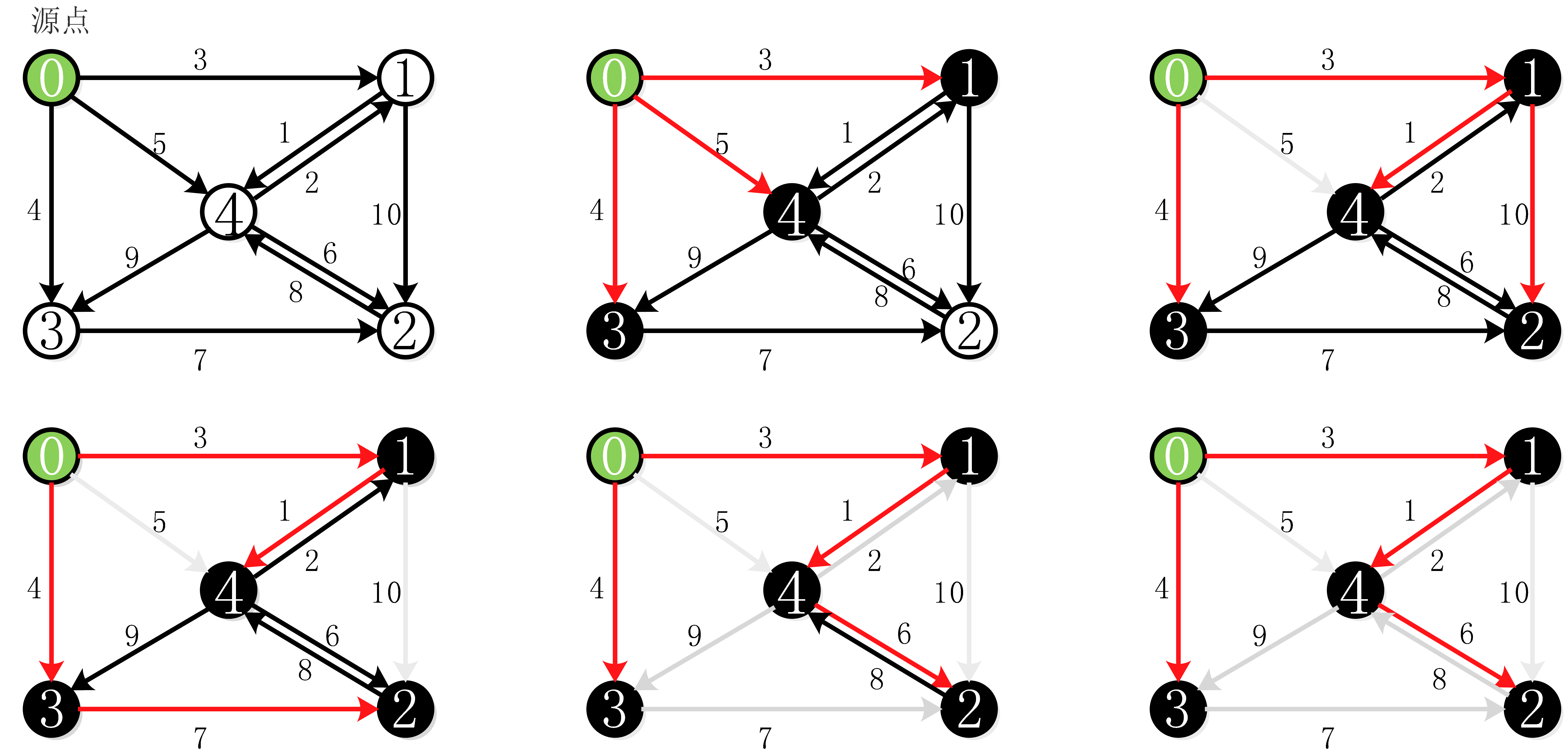
Dijkstra算法的代码实现:
//Dijkstra算法的实现
public class Dijkstra {
private Edge[] edgeTo; //最短路径树
private int[] distTo; //存储每个顶点到源点的距离
//索引优先队列,建立distTo和顶点索引,distTo越小,优先级越高
private IndexMinPQ<Integer> pq;
public Dijkstra(WeightedDigraph wd, int s) {
edgeTo = new Edge[wd.getVertexsNum()];
distTo = new int[wd.getVertexsNum()];
pq = new IndexMinPQ<>(wd.getVertexsNum());
for(int i=0; i<wd.getVertexsNum(); i++) {
distTo[i] = Integer.MAX_VALUE;
}
distTo[s] = 0; //源点s的distTo为0
pq.insert(s, 0);
while(pq.isEmpty()) {
relax(wd, pq.delMin());
}
}
//顶点的松弛
private void relax(WeightedDigraph wd, int ver) {
for(Edge e : wd.adj(ver)) {
int v = e.getTo();
if(distTo[v] > distTo[ver] + e.getWeight()) {
distTo[v] = distTo[ver] + e.getWeight();
edgeTo[v] = e;
if(pq.contains(v)) {
pq.change(v, distTo[v]);
}else {
pq.insert(v, distTo[v]);
}
}
}
}
}
Dijkstra算法的局限性:图中边的权重必须为正,但可以是有环图。时间复杂度为O(ElogV),空间复杂度O(V)。
这篇文章写了好久,陆陆续续差不多快10天了,至今还有以下内容没有总结:
- 图的邻接多重表
- 图的边集数组实现
- 最短路径的Floyd算法
- 拓扑排序
- union-find算法
- 无环加权有向图的最短路径算法
- 关键路径
- 计算无向图中连通分量的Kosaraju算法
- 有向图中含必经点的最短路径问题
- TSP问题
- 还有A*算法
图的知识实在是太多了,就先总结到这里吧,有时间在写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号