
Django+pdfkit+wkhtmltopdf生成PDF
需求:将txt文件中的数据转换成表格,并生成PDF文件,以供下载
依赖
- 安装
wkhtmltopdf, Mac安装方式如下:
brew install wkhtmltopdf
记录下wkhtmltopdf的安装路径,以供代码中使用,这里是:/usr/local/bin/wkhtmltopdf
- Django项目中,需要安装
pdfkit依赖,直接使用pip安装
pip install pdfkit
代码编写
第一步:数据转换
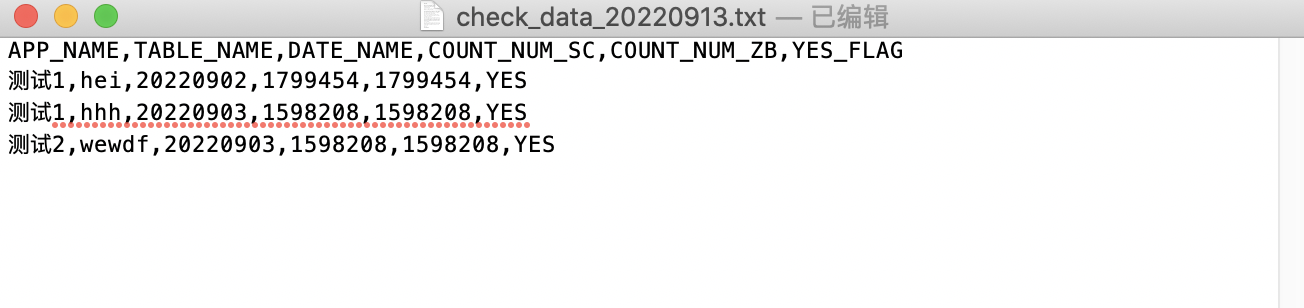
txt文件中的数据如下,需要将其取出,处理成list
代码如下:
读取文件内容
def get_file_content(file_dir, file_name):
"""
获取文件内容
file_dir: txt文件目录
file_name:txt文件文件名称
"""
file_path = file_dir + file_name
if not os.path.exists(file_path):
raise Exception('文件目录:%s不存在' % file_dir)
with open(file_path, "r", encoding='gbk') as f:
data = f.read()
return data
数据处理
def handle_file_data(data):
"""
对文件内容进行处理:str->list
"""
content = data.strip('\n')
if not content:
raise Exception('当前文件数据为空')
lines = content.split('\n')
key_str = lines.pop(0)
keys = key_str.split(',')
items = []
for line in lines:
valus = line.split(',')
# valus的长度不够,补齐
if len(keys) > len(valus):
n = len(keys) - len(valus)
for i in range(n):
valus.append('')
# 数据组装
item = {}
for index in range(len(keys)):
item[keys[index]] = valus[index]
items.append(item)
return items, keys
返回数据如下:
[
{
"APP_NAME": "测试1",
"TABLE_NAME": "hei",
"DATE_NAME": "20220902",
"COUNT_NUM_SC": "1799454",
"COUNT_NUM_ZB": "1799454",
"YES_FLAG": "YES"
},
{
"APP_NAME": "测试1",
"TABLE_NAME": "hhh",
"DATE_NAME": "20220903",
"COUNT_NUM_SC": "1598208",
"COUNT_NUM_ZB": "1598208",
"YES_FLAG": "YES"
},
{
"APP_NAME": "测试2",
"TABLE_NAME": "wewdf",
"DATE_NAME": "20220904",
"COUNT_NUM_SC": "1615662",
"COUNT_NUM_ZB": "1615662",
"YES_FLAG": "YES"
}
]
第二步:模版生成
这里使用的是Mako模版, 在项目的/templates目录下创建pdf.html文件,在里面写前端代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PDF</title>
<style>
th {
padding: 5px 5px;
}
td {
padding: 5px 5px;
max-width: 200px;
word-wrap: break-word;
white-space: normal;
word-break:break-all;
}
</style>
</head>
<body>
<div style="width: 900px;margin: 0 auto;">
<table border="1" cellpadding="0" cellspacing="0" width="100%">
<thead>
<tr>
% for name in tableHeaders:
<th>${name}</th>
% endfor
</tr>
</thead>
<tbody>
% for item in data:
<tr style="page-break-inside: avoid!important;">
%if mergeData["APP_NAME"][loop.index] > 0:
<td rowspan='${mergeData["APP_NAME"][loop.index]}'>${ item["APP_NAME"] }</td>
%endif
%if mergeData["TABLE_NAME"][loop.index] > 0:
<td rowspan='${mergeData["TABLE_NAME"][loop.index]}'>${ item["TABLE_NAME"] }</td>
%endif
<td>${ item["DATE_NAME"] }</td>
<td>${ item["COUNT_NUM_SC"] }</td>
<td>${ item["COUNT_NUM_ZB"] }</td>
<td>${ item["YES_FLAG"] }</td>
</tr>
% endfor
</tbody>
</table>
</div>
</body>
</html>
使用方法:
t = render_mako_context(request, 'pdf.html', {'data': data, 'mergeData': merge_data,
'tableHeaders': ch_headers})
content = t.content.decode(encoding="utf-8")
content为生成PDF提供数据
第三步:生成PDF
def pdf_create(wk_path, pdf_name, content, pdf_path):
"""
生成PDF文件
wk_path: wkhtmltopdf安装路径:`/usr/local/bin/wkhtmltopdf`
pdf_path: PDF存放路径
pdf_name: 生成的PDF文件名称
content:模版内容
"""
file_path = pdf_path + pdf_name + '.pdf'
try:
config = pdfkit.configuration(wkhtmltopdf=wk_path)
result = pdfkit.from_string(content, file_path, options={'encoding': "utf-8"},
configuration=config)
except Exception as e:
logger.error('生成PDF文件异常:%s' % e)
result = False
扩展:将url转换成PDF
config = pdfkit.configuration(wkhtmltopdf=wk_path)
url = 'http://www.baidu.com/'
pdfkit.from_url(url, file_path, options={'encoding': "utf-8"},
configuration=config)
第四步:下载PDF
def export_pdf(self, request, *args, **kwargs):
"""
file_path: 下载的PDf文件路径
"""
file = open(file_path, 'rb')
response = FileResponse(file)
response['Content-Type'] = 'application/octet-stream'
response['Content-Disposition'] = 'attachment;filename="{}.pdf"'.format(file_name)
return response
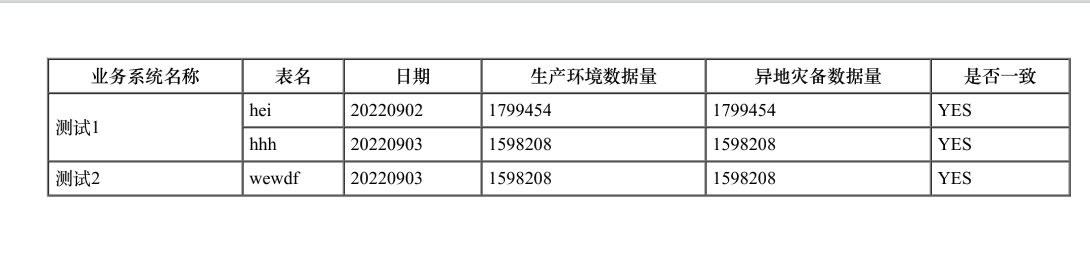
结果如果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号