shell脚本编程学习笔记
前言
最近在学shell脚本。这玩意我觉得不好学,语法奇葩,命令繁多,而且不够严谨。
比如四则运算表达式,$(()),$[],expr a + b ,let xxx,有这四种,expr 后的运算符号两边得有空格;
再比如if条件判断中的条件,可以写成 test xxx,或者[ xxx ],或者[[ xxx ]],或者类c风格 ((2<3)),你说你搞这么多形式干嘛呢,这不是增加学习成本吗?
再比如:
root@aliyun:~# test 1 -eq 1 -a 2 -eq 2;echo $?
0
root@aliyun:~# test 1 -eq 1 -a test 2 -eq 2;echo $?
-bash: test: too many arguments
2
root@aliyun:~# test 1 -eq 1 && 2 -eq 2;echo $?
2: command not found
127
root@aliyun:~# test 1 -eq 1 && test 2 -eq 2;echo $?
0
用-a后面不能再跟test,用&&后面还必须要加上test,这不是扯犊子么?
唉,先学点基础的吧,以后复杂的直接用python来代替。
Vim文本编辑器
1、插入文本操作
| 快捷键 | 功能描述 |
|---|---|
| i | 在当前光标所在位置插入随后输入的文本,光标后的文本相应向右移动 |
| I | 在光标所在行的行首插入随后输入的文本,行首是该行的第一个非空白字符,相当于光标移动到行首执行 i 命令 |
| o | 在光标所在行的下面插入新的一行。光标停在空行首,等待输入文本 |
| O(大写) | 在光标所在行的上面插入新的一行。光标停在空行的行首,等待输入文本 |
| a | 在当前光标所在位置之后插入随后输入的文本 |
| A | 在光标所在行的行尾插入随后输入的文本,相当于光标移动到行尾再执行 a 命令 |
2、查找文本
| 快捷键 | 功能描述 |
|---|---|
| /abc | 从光标所在位置向前查找字符串 abc |
| /^abc | 查找以 abc 为行首的行 |
| /abc$ | 查找以 abc 为行尾的行 |
| ?abc | 从光标所在位置向后查找字符串 abc |
| n | 向同一方向重复上次的查找指令 |
| N | 向相反方向重复上次的查找指定 |
注意:如果在字符串中出现特殊符号,则需要加上转义字符 "\"。常见的特殊符号有 \、*、?、$ 等。如果出现这些字符,例如,要查找字符串 "10$",则需要在命令模式中输入 "/10\$"。
3、文本替换
| 快捷键 | 功能描述 |
|---|---|
| r | 替换光标所在位置的字符 |
| R | 从光标所在位置开始替换字符,其输入内容会覆盖掉后面等长的文本内容,按“Esc”可以结束 |
| :s/a1/a2/g | 将当前光标所在行中的所有 a1 用 a2 替换 |
| :n1,n2s/a1/a2/g | 将文件中 n1 到 n2 行中所有 a1 都用 a2 替换 |
|
:%s/a1/a2/g 或者:1,$s/a1/a2/g |
将文件中所有的 a1 都用 a2 替换 |
4、删除文本
| 快捷键 | 功能描述 |
|---|---|
| x | 删除光标所在位置的字符 |
| dd | 删除光标所在行 |
| ndd | 删除当前行(包括此行)后 n 行文本 |
| dG | 删除光标所在行一直到文件末尾的所有内容 |
| D | 删除光标位置到行尾的内容 |
| :a1,a2d | 函数从 a1 行到 a2 行的文本内容 |
5、复制文本
| 快捷键 | 功能描述 |
|---|---|
| p | 将剪贴板中的内容粘贴到光标后 |
| P(大写) | 将剪贴板中的内容粘贴到光标前 |
| v | 上下移动光标选中文本后按y复制到剪切板,再p粘贴 |
| yy | 将光标所在行复制到剪贴板,此命令前可以加数字 n,可复制多行 |
| Y | 复制光标所在行 |
6、保存文本
| 命令 | 功能描述 |
|---|---|
| :wq | 保存并退出 Vim 编辑器 |
| :wq! | 保存并强制退出 Vim 编辑器 |
| :q | 不保存就退出 Vim 编辑器 |
| :q! | 不保存,且强制退出 Vim 编辑器 |
| :w | 保存但是不退出 Vim 编辑器 |
| :w! | 强制保存文本 |
| :w filename | 另存到 filename 文件 |
| x! | 保存文本,并退出 Vim 编辑器,更通用的一个 vim 命令 |
| ZZ | 直接退出 Vim 编辑器 |
注意:"w!" 和 "wq!" 等类似的指令,通常用于对文件没有写权限的时候(显示 readonly,如图 12 所示),但如果你是文件的所有者或者 root 用户,就可以强制执行。
7、其他快捷键
J:将当前行与下一行用空格合并连接成一行
u:撤销操作
关于用户
创建用户:useradd -r -m -s /bin/bash username 创建系统用户并生成家目录
删除用户:userdel -r username -r 选项表示在删除用户的同时删除用户的家目录。
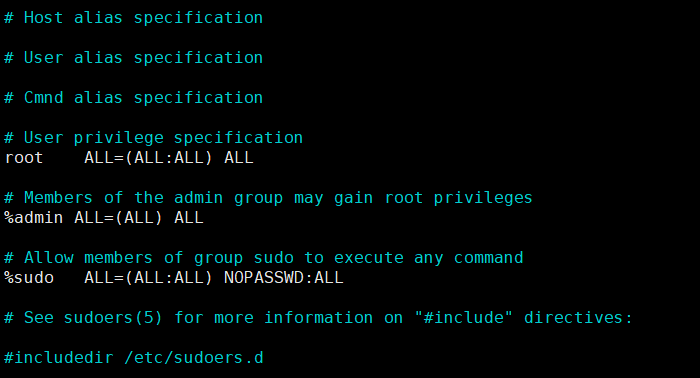
给普通用户wangyi添加root权限:usermod -a -G sudo wangyi
直接给wangyi添加附加组sudo,sudo组的权限通过visudo可以看到,如下,跟root用户一样。不想每次sudo都输入密码可以在sudo那里最后一个ALL前面加上NOPASSWD:
注意:这个visudo默认用nano编辑器打开,保存用ctrl+o,然后回车,再ctrl+x
用户组
查看用户组:/etc/group
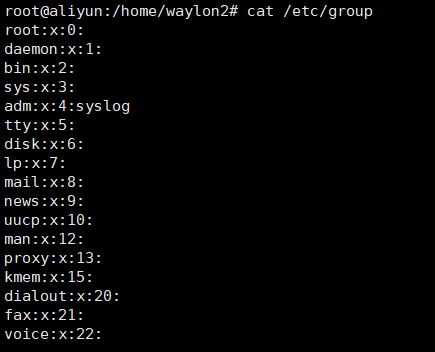
用:隔成4个字段,每个字段的含义为:
1、组名
也就是是用户组的名称,由字母或数字构成。同 /etc/passwd 中的用户名一样,组名也不能重复。
2、组密码
和 /etc/passwd 文件一样,这里的 "x" 仅仅是密码标识,真正加密后的组密码默认保存在 /etc/gshadow 文件中。
不过,用户设置密码是为了验证用户的身份,那用户组设置密码是用来做什么的呢?用户组密码主要是用来指定组管理员的,由于系统中的账号可能会非常多,root 用户可能没有时间进行用户的组调整,这时可以给用户组指定组管理员,如果有用户需要加入或退出某用户组,可以由该组的组管理员替代 root 进行管理。但是这项功能目前很少使用,我们也很少设置组密码。如果需要赋予某用户调整某个用户组的权限,则可以使用 sudo 命令代替。
3、组ID (GID)
就是群组的 ID 号,Linux 系统就是通过 GID 来区分用户组的,同用户名一样,组名也只是为了便于管理员记忆。
这里的组 GID 与 /etc/passwd 文件中第 4 个字段的 GID 相对应,实际上,/etc/passwd 文件中使用 GID 对应的群组名,就是通过此文件对应得到的。
4、组中的用户
此字段列出每个群组包含的所有用户。需要注意的是,如果该用户组是这个用户的初始组,则该用户不会写入这个字段,可以这么理解,该字段显示的用户都是这个用户组的附加用户。
举个例子,lamp 组的组信息为 "lamp:x:502:",可以看到,第四个字段没有写入 lamp 用户,因为 lamp 组是 lamp 用户的初始组。如果要查询这些用户的初始组,则需要先到 /etc/passwd 文件中查看 GID(第四个字段),然后到 /etc/group 文件中比对组名。
每个用户都可以加入多个附加组,但是只能属于一个初始组。所以我们在实际工作中,如果需要把用户加入其他组,则需要以附加组的形式添加。例如,我们想让 lamp 也加入 root 这个群组,那么只需要在第一行的最后一个字段加入 lamp,即 root:x:0:lamp 就可以了。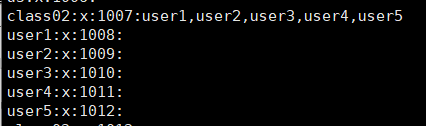
一般情况下,用户的初始组就是在建立用户的同时建立的和用户名相同的组。
对于/etc/passwd、/etc/shadow、/etc/group,它们之间的关系可以这样理解,即先在 /etc/group 文件中查询用户组的 GID 和组名;然后在 /etc/passwd 文件中查找该 GID 是哪个用户的初始组,同时提取这个用户的用户名和 UID;最后通过 UID 到 /etc/shadow 文件中提取和这个用户相匹配的密码。
运算符
注意:(( )) 只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。bc 命令可以用于小数运算。
和双小括号 (( )) 一样,let 命令也只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。
注意:(( )) 只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。后续讲到的 bc 命令可以用于小数运算。
root@aliyun:~/shell/while# a=2
root@aliyun:~/shell/while# let a+=1
root@aliyun:~/shell/while# echo $a
3
oot@aliyun:~/shell/while# let a+=1
root@aliyun:~/shell/while# echo $a
3
循环控制语句
案例1:
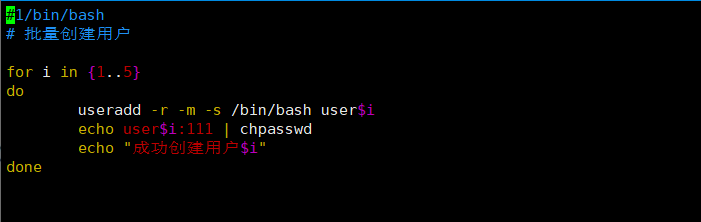
案例2:
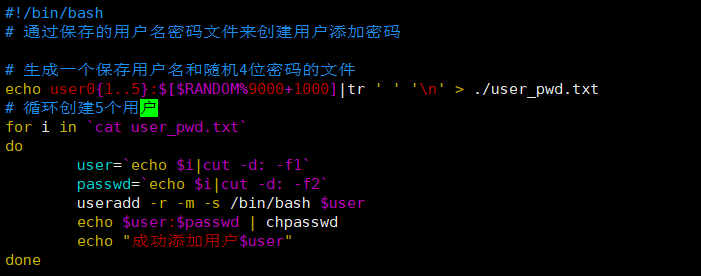
案例3:

案例4:
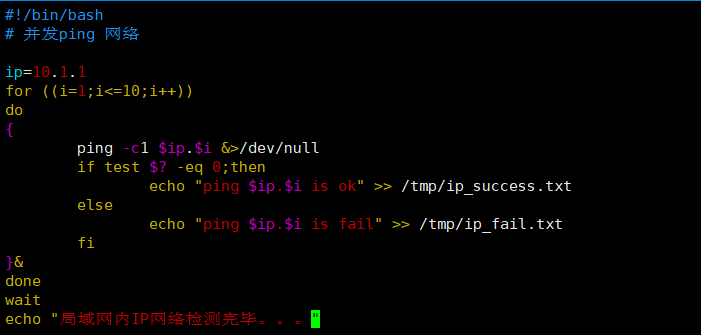
案例5:

案例5:

案例6:
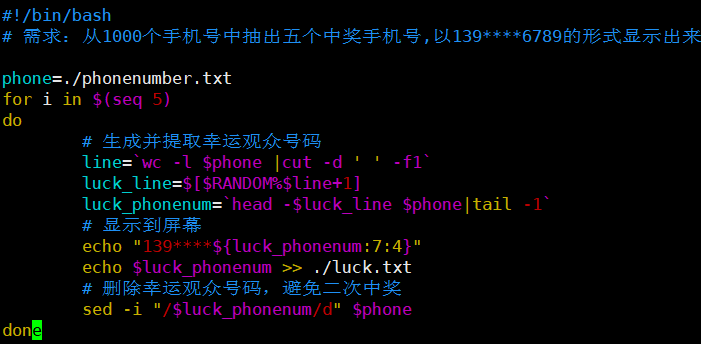
案例7:
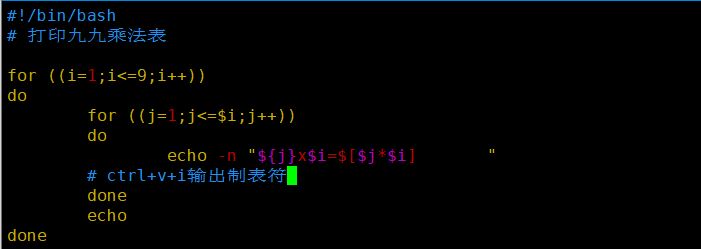
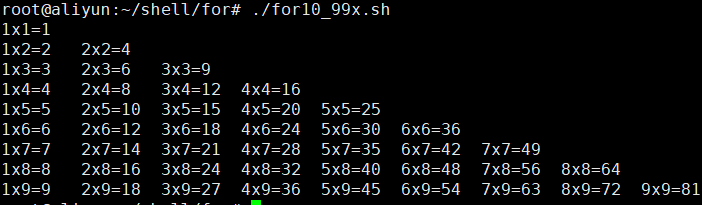
案例8:
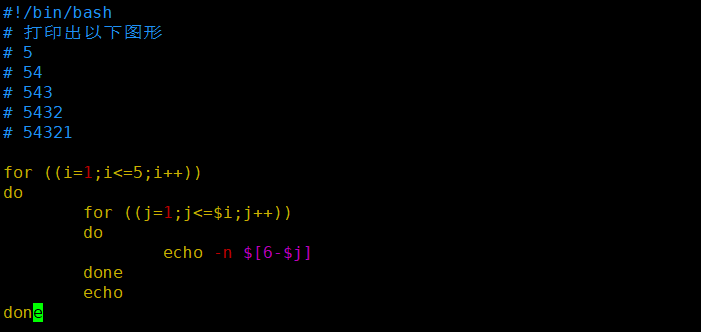
案例9:

执行:

案例10:
数组
shell中没有限制数组大小。
定义数组:
array=(1 2 3 "hehe")
arr[1]=1
arr=(`ls`)
arr=($(cat file)) 将文件中的每一行或者空格隔开的内容作为数组的元素
a=1;arr[$a]=11 数组下标也可以是变量的值,若arr[1]之前存在,则直接修改arr[1]
获取数组:
echo ${arr[1]} 获取数组的第二个元素
echo ${arr[@]} 获取数组所有元素,@等价于*
echo ${#arr[@]} 获取数组元素的个数
echo ${arr[*]:1:3} 从第二个元素开始获取3个数组元素
echo ${!arr[@]} 获取所有元素的索引下标
declare -a 获取普通数组信息
关联数组:
下标可以为字符串:(当然也可以是整数)
定义前要声明:declare -A 关联数组名

也可以:asso_arr=([name]=wangyi [age]=18)
获取:
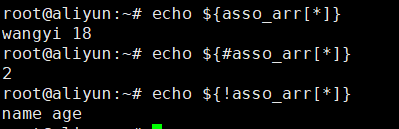
类似于python中的字典。
Linux的小命令
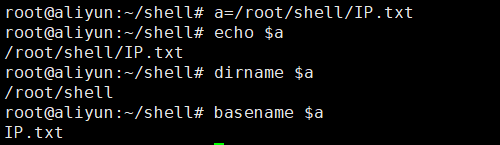
1、dirname 获取目录
2、basename 取出文件
3、去除变量的部分内容
#从左去除,%从右,##去除所有匹配到的,%%一样。

4、未得其名,却得其实
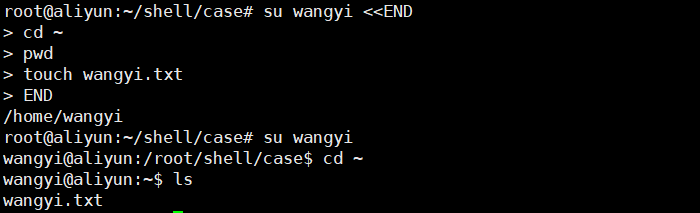
直接在root账户下,在用户wangyi的家目录下创建文件
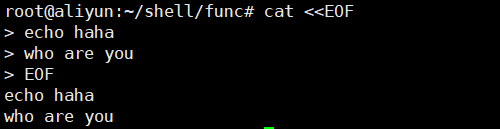
5、cat <<EOF 展示输出
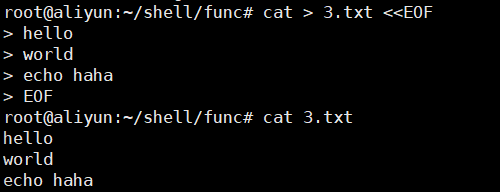
cat > 3.txt <<EOF 输出重定向,向3.txt文件覆盖写入数据 >>3.txt 是追加写
或者直接用这种方式创建文件并写入数据:
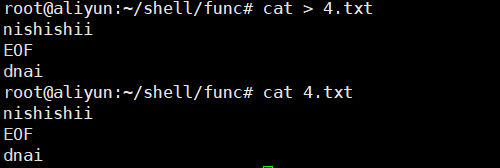
注意,在脚本中,要用<<-EOF消除EOF命令前的制表符,不然会报错

函数
1、环境变量
将函数添加到用户家目录下的.bashrc中,这样其他用户不可调用

若要全局生效,则在etc/bashrc里面定义函数。
2、用例
简单的登录判断:
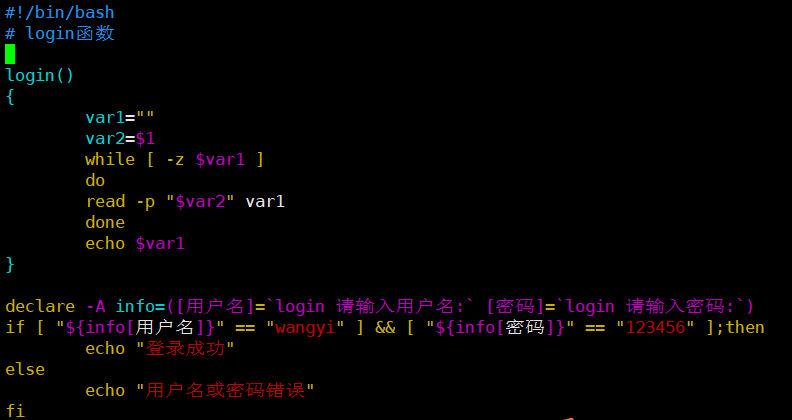
login函数也可换成这样:

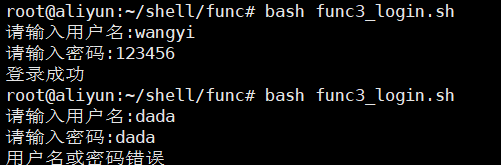
注意:字符串判断==两边留空格并用引号引起来。
正则表达式
元字符:在正则中,具有特殊意义的专用字符,如: 星号(*)、加号(+)等
前导字符:元字符前面的字符叫前导字符
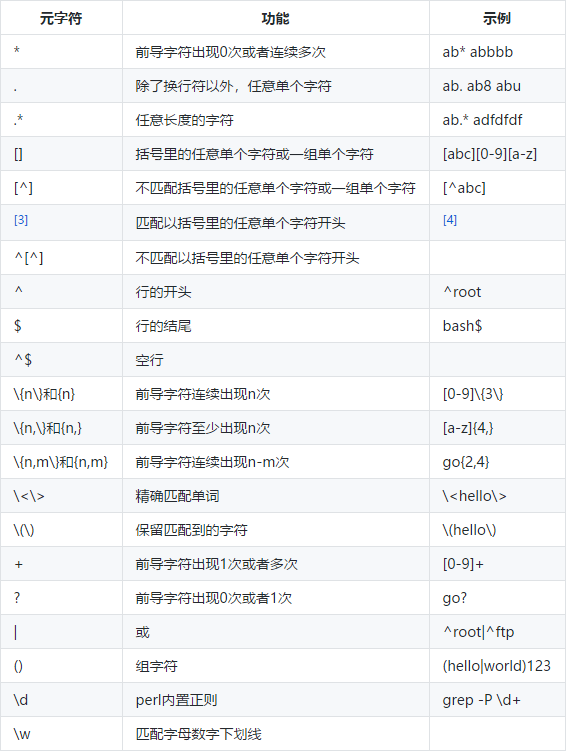
注意: 其中 + ? | ()这几个扩展字符用grep时要加-E。
Liunx文本处理三剑客
1、grep (global regular expressions print)
常用选项:
-i: 不区分大小写
-v: 查找不包含指定内容的行,反向选择
-w: 按单词搜索
-o: 打印匹配关键字
-c: 统计匹配到的行数
-n: 显示行号
-r: 逐层遍历目录查找
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l:只列出匹配的文件名
-L:列出不匹配的文件名
-e: 使用正则匹配
-E:使用扩展正则匹配
^key:以关键字开头
key$:以关键字结尾
^$:匹配空行
--color=auto :可以将找到的关键词部分加上颜色的显示
举例:
# grep -i root passwd 忽略大小写匹配包含root的行
# grep -w ftp passwd 精确匹配ftp单词
# grep -w hello passwd 精确匹配hello单词;自己添加包含hello的行到文件
# grep -wo ftp passwd 打印匹配到的关键字ftp
# grep -n root passwd 打印匹配到root关键字的行好
# grep -ni root passwd 忽略大小写匹配统计包含关键字root的行
# grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数
# grep -i ^root passwd 忽略大小写匹配以root开头的行
# grep bash$ passwd 匹配以bash结尾的行
# grep -n ^$ passwd 匹配空行并打印行号
# grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行
# grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行
# grep -A 5 mail passwd 匹配包含mail关键字及其后5行
# grep -B 5 mail passwd 匹配包含mail关键字及其前5行
# grep -C 5 mail passwd 匹配包含mail关键字及其前后5行2、sed
未完待续。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号