Python开发【第四篇】:Python基础之函数
三元运算
三元运算(三目运算),是对简单的条件语句的缩写。
|
1
2
3
4
5
|
# 书写格式result = 值1 if 条件 else 值2# 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量 |
基本数据类型补充
set
set集合,是一个无序且不重复的元素集合


######set #把不同元素组成在一起,无序 #创建列表的方式 # a = [2,3,4] # b = list([3,4,5]) # print(a) # print(b) #创建列表 去重 # s = set('alex li') # s1 = ['alvin','ee','alvin'] # s2=set(s1) # print(s2,type(s2)) # print(list(s2)) # print(s) # li = [[1,2],3,'asdfwe'] #不可hash ,因为存在[1,2] # s = set(li) #TypeError: unhashable type: 'list' # print(s) # li = [2,3,'asdfwe'] #不可hash # s = set(li) # print(s) #dic = {s : '123'} #s不可做键值 # print (2 in s) # print (4 not in s) #集合更新 # s.add('u') # print(s) # s.add('uu') #添加一个元素 # print(s) # s.update('ops') #把ops按照序列增加到s集合中 # print(s) #{'p', 2, 3, 'o', 's', 'asdfwe'} # s.update([12,'abd'])#update里需要加可迭代对象 # print(s) # s.remove(2) # print(s) # s.pop() # print(s) # s.clear() # print(s) # del s # print(s) 报错 #集合比较 # print(set('alex') == set('alexxxeee')) # # print(set('alex') <set('alexkkkkk')) # # print(set('alex') and set('alexw')) #合起来 # # print(set('alex') or set('alexw')) #公有的 #关系测试 #交集 并集 差集 a = set([1,2,3,4,5]) b = set([4,5,6,7,8]) # #交集 # print(a.intersection(b)) #{4, 5} #print(a & b) # #union 并集 # print(a.union(b)) #{1, 2, 3, 4, 5, 6, 7, 8} #print(a | b) # # #差集 # print(a.difference(b)) #{1, 2, 3} in a but not in b #print(a - b) #对称差集 # print(a.symmetric_difference(b)) #{1, 2, 3, 6, 7, 8} #print(a ^ b) #父集 超集 # print(a.issuperset(b)) #a>b # # #子集 # print(a.issubset(b)) # a<b
字符串格式化
#字符串格式化 #msg='i am %s my hobby is alex' %'wyh' #msg='i am %s my hobby is %s' %('wyh','alext') #msg='i am %s my hobby is %s' %('wyh',[1,2]) # name='why' # age=19 # msg='i am %s my hobby is %d' %(name,age) # print(msg) #打印浮点数 #tpl = "percent %0.2f" % 99.9712 #打印百分比 #tpl = "percent %0.2f%%" % 99.9712 #键值传 #tpl = "i am %(name)s age %(age)d" % {"name":"alex","age":18} #msg='i am %(name)+20s my hobby is alex' % {"name":"wyh"} #加颜色 #msg='i am \033[43:1m%(name)+20s\033[0m my hobby is alex' % {"name":"wyh"} #拼接字串 #print('root', 'x', '0', '0',sep=':') #print(msg) #print('i am %s my hobby is alex' %'wyh')
format格式化
#format 格式化 #一一对应 #tpl = "i am {},age {}, {}".format("seven",18,"alex") #tpl = "i am {2},age {1}, {0}".format("seven",18,"alex") #元组形式 #tpl = "i am {2},age {1}".format("seven",18,"alex") #tpl = "i am {name},age {age}".format(name="alex",age=19) #tpl = "i am {name},age {age}".format(**{"name":"alex","age":19}) #tpl = "i am {:s},age {:d}".format(*["name",19]) tpl = "i am {:s},age {:d}".format("name",19) print(tpl)
练习:寻找差异
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 数据库中原有old_dict = { "#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }, "#2":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 } "#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }} # cmdb 新汇报的数据new_dict = { "#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 800 }, "#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 } "#4":{ 'hostname':c2, 'cpu_count': 2, 'mem_capicity': 80 }} |
需要删除:?需要新建:?需要更新:?
注意:无需考虑内部元素是否改变,只要原来存在,新汇报也存在,就是需要更新
深浅拷贝
一、数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import copy# ######### 数字、字符串 #########n1 = 123# n1 = "i am alex age 10"print(id(n1))# ## 赋值 ##n2 = n1print(id(n2))# ## 浅拷贝 ##n2 = copy.copy(n1)print(id(n2)) # ## 深拷贝 ##n3 = copy.deepcopy(n1)print(id(n3)) |
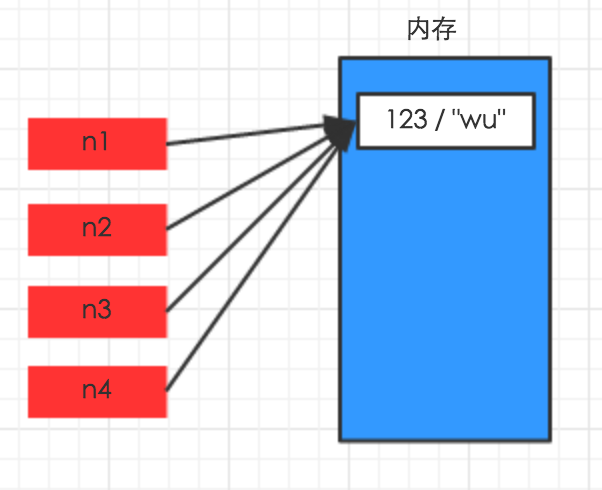
二、其他基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
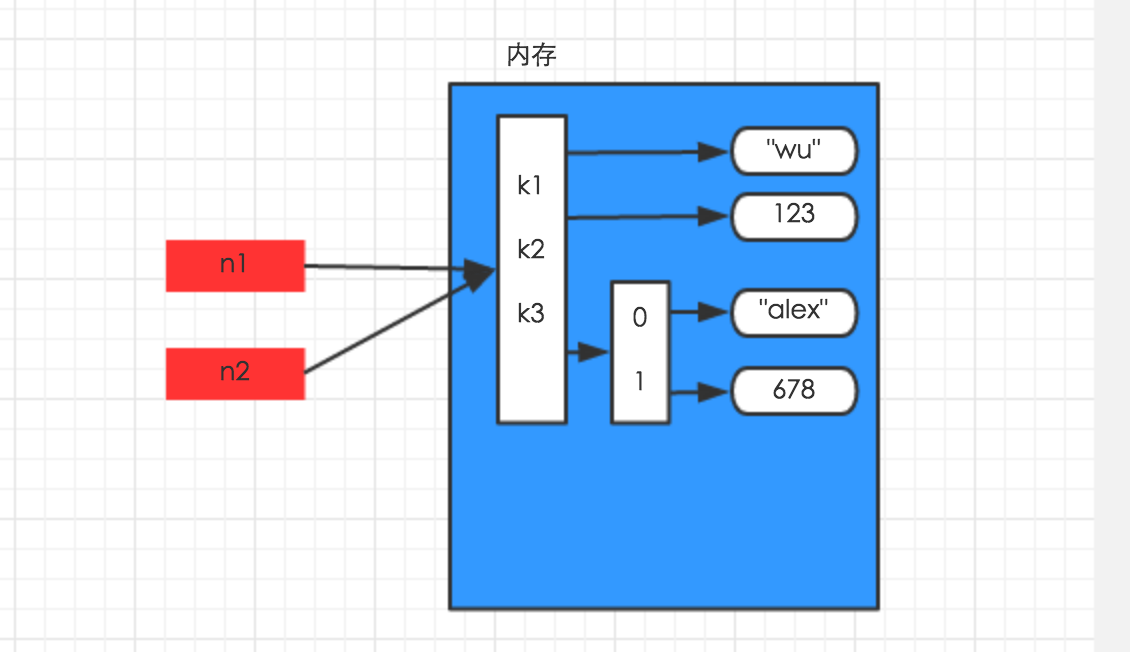
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
|
1
2
3
|
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n2 = n1 |
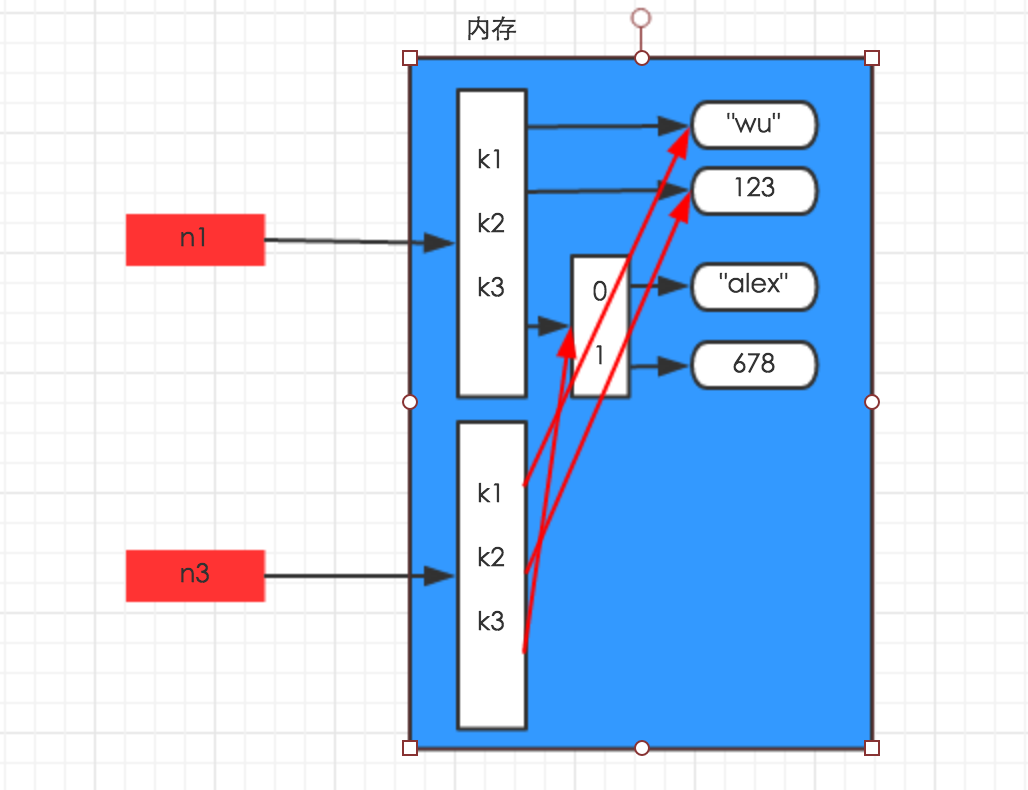
2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
|
1
2
3
4
5
|
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n3 = copy.copy(n1) |
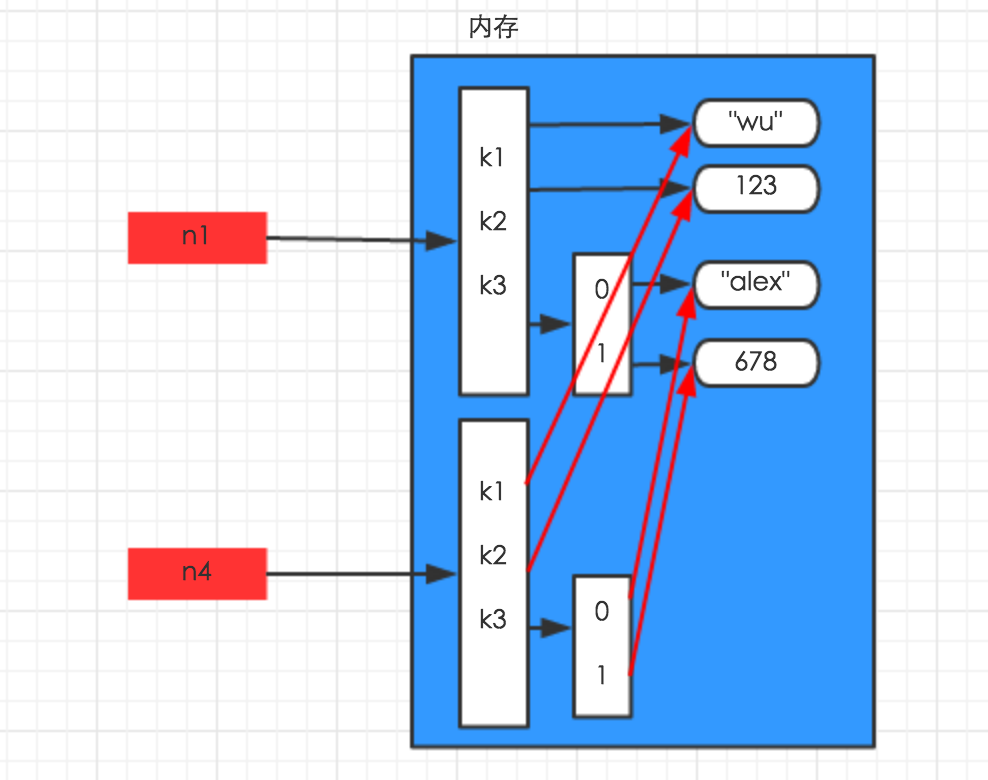
3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
|
1
2
3
4
5
|
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n4 = copy.deepcopy(n1) |
深浅拷贝
########函数 模块 #1.深浅拷贝 2.set #函数: # 1.概念 # 2.创建 # s = [1,'alxes','alvein'] # # s1 = [1,'alxes','alvein'] # s1[0] = 2 # print(s) # print(s1) # s = [1,'alxes','alvein'] # s2 = s.copy() # print(s2) #[1, 'alxes', 'alvein'] # # s2[0] = 3 # print(s) #[1, 'alxes', 'alvein'] # print(s2) #[3, 'alxes', 'alvein'] ########博客 alvin yuan 浅拷贝 只是复制第一层,不能复制深层次的 # s = [[1,2],'lsefs','alsdie'] # s3 = s.copy() # print(s3) # # # s3[1]='linux' # # print(s3) # # print(s) # s3[0][1]=3 # print(s3) # print(s) #深拷贝 完全克隆 # import copy # #s4 = copy.copy() ##浅拷贝 # s4 = copy.deepcopy() #
函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
腚眼一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件('CPU报警') if 硬盘使用空间 > 90%: 发送邮件('硬盘报警') if 内存占用 > 80%: |
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数式编程最重要的是增强代码的重用性和可读性
二、定义和使用
|
1
2
3
4
5
6
|
def 函数名(参数): ... 函数体 ... 返回值 |
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
以上要点中,比较重要有参数和返回值:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def 发送短信(): 发送短信的代码... if 发送成功: return True else: return False while True: # 每次执行发送短信函数,都会将返回值自动赋值给result # 之后,可以根据result来写日志,或重发等操作 result = 发送短信() if result == False: 记录日志,短信发送失败... |
2、参数
为什么要有参数?
无参数实例
def test(): """ :param x:整形数字 :return: 返回计算结果 """ x = 3 y = 2*x + 1 return y a = test() print(a)
有参数实例
# def test(x): # """ # # :param x:整形数字 # :return: 返回计算结果 # """ # y = 2*x + 1 # return y # a = test(2) # print(a)
# def test(): # """ # :param x:整形数字 # :return: 返回计算结果 # """ # x = 3 # y = 2*x
- 普通参数
- 默认参数
- 动态参数
普通参数 # def calc(x,y):-------形参 # res = x*y # return res # res = calc(2,3) -----实参 # print(res) # a = 10 # b = 10 # calc(a,b)
默认参数 def test(x,y,type='z'): print(x) print(y) print(type) test(1,2,3) 或 test(1,2)
动态参数 def test(x,*args,**kwargs): print(x) print(args) print(kwargs) #args 输出是一个元组 #print(args[0][0]) ##取出列表中的值 test(1,2,3,45,y=2,z=4) #一个参数不能传两个值
函数的全局变量,局部变量
# name = 'lhf' # # def change_name(): # name = 'shuaile--yibi' # print('change_name',name) # change_name() # print(name) #如果函数的内容无global关键字,优先读取局部变量,只能读取全局变量,无法对全局变量重新赋值,但是对于可变对象,可以对内部元素进行操作 #如果函数中有global关键字,变量本质上就是全局的那个变量,可读取可赋值 # name = 'lhf' # # def change_name(): # global name #强制全局变量 # name = "shuaide--yibi" # print('change_name',name) # change_name() # print(name) # name = ['ldf','gunide'] # # def change_name(): # name.append("shuaide--yibi") # print('change_name',name) # change_name() # print(name) # name = "gangni" # # def weihou(): # name = "chenzhuo" # def weiweihou(): # nonlocal name #指定上一级的变量 # name = "lengjing" # # weiweihou() # print(name) # # print(name) # weihou() # print(name)
前向引用
#前向引用 # def bar(): # print('from bar') # def foo(): # print('from foo') # bar() # # foo()
下面这种情况是错误的:
def foo():
print('from foo')
bar()
foo()
def bar():
print('from bar')
递归
# import time # def calc(n): # print(n) # if int(n/2) == 0: # return n # calc(int(n / 2)) # #res = calc(int(n / 2)) # #return res # # # calc(10) import time person_list = ['alex','wupeiqi','yuanhao','linhai','sxxx'] def ask_way(person_list): if len(person_list) == 0: return '根本没人知道' person = person_list.pop(0) if person == 'linhai': return '%s 说:下地铁就是' %person print('hi [%s]' %person) print('%s 回答到:%s知道..'%(person,person_list)) time.sleep(10) res = ask_way(person_list) print('%s 问的结果是'%person) return res res = ask_way(person_list) print(res)
函数作用域
# def test1(): # print('in the test1') # def test(): # print('in the test') # return test1 # # res = test() #print(res) #res 返回的是test1的内存地址 # print(res()) #作用域 # name = 'alex' # def foo(): # name = 'linhai' # def bar(): # name = 'wupei' # print(name) # return bar # a = foo() # print(a()) # name = 'alex' # def foo(): # name = 'linhai' # def bar(): # name = 'wupei' # def tt(): # print(name) # return tt # return bar # #a = foo() # #tt = a() # #print(tt()) # foo()()()
匿名函数
#匿名函数 #lamdba x:x+1 # def calc(x): # return x+1 # res = calc(10) # print(calc) # func = lambda x:x+1 # print(func(10)) # name = 'alex' #name='alex_sb' # def change_name(x): # return x+'_sb' # # res = change_name(name) # print(res) # # f = lambda x:x+'_sb' # print('匿名函数的结果',f(name)) f=lambda x:x.startswith('n') #print(f('nb')) print(f('bnb')) # f = lambda x,y,z:(x+1,y+2,z+3) # print(f(1,2,3))
高阶函数
#高阶函数 #1.把函数当作参数传给另一个函数 # def foo(n): # print(n) # # def bar(name): # print('my name is %s' %name) # # foo(bar(3)) #2.返回值中包含函数 # def bar(): # print('from bar') # def foo(): # print('from foo') # return bar # n = foo() # n() # def handle(): # print('from handle') # return handle # h = handle() # h()
map 函数的演变过程
####把列表中的每个元素做乘方 num_1 = [1,2,10,5,3,7] ####第一种方法 过程 # ret = [] # for i in num_1: # ret.append(i**2) # print(ret) ######第二种方法 函数 # def map_test(array): # ret = [] # for i in array: # ret.append(i**2) # return ret # ret = map_test(num_1) # print(ret) #######第三种方法 #####lambda x:x**2 # def cf(x): # return x**2 # # def map_test(cf,array): # ret = [] # for i in array: # ret.append(cf(i)) # return ret # #(1)第一种方法 # #ret = map_test(cf,num_1) # # #(2)第二种方法 # #ret = map_test(lambda x:x**2,num_1) # # print(ret) ######第四种方法 #print('map函数输出',list(map(lambda x:x**2,num_1)))
filter 函数演变过程
#filter函数演变 #找出下面列表中不是以db为结尾的元素 num_1 = ['aleds','baisx','zhongdb'] ###第一种方法 # ret = [] # for i in num_1: # if not i.endswith('db'): # ret.append(i) # # print(ret) ####第二种方法 # def filter_test(array): # ret = [] # for i in array: # if not i.endswith('db'): # ret.append(i) # return ret # ret = filter_test(num_1) # print(ret) ########第三种方法 def gl(x): return x.endswith('db') def filter_test(func,array): ret = [] for i in array: if not func(i): ret.append(i) return ret ret = filter_test(gl,num_1) print(ret) print(filter_test(lambda x: x.endswith('db'),num_1)) #######第四种方法 print(list(filter(lambda x:not x.endswith('db'),num_1)))
# people = [
# {'name':'aalex','age':1000},
# {'name':'lsdfinhai','age':18},
# ]
#
# print(list(filter(lambda p:p['age']<=18,people)))
reduce 函数演变
num_1 = [1,2,4,5] ###第一种方法 # ret = 0 # for i in num_1: # ret += i # # # print(ret) ####第二种方法 # def filter_test(array): # ret = 0 # for i in array: # ret += i # return ret # ret = filter_test(num_1) # print(ret) ########第三种方法 def gl(x,y): return x+y def filter_test(func,array): ret = 0 for i in array: ret = func(ret,i) return ret ret = filter_test(gl,num_1) print(ret) # print(filter_test(lambda x,y: x+y,num_1)) # # #######第四种方法 from functools import reduce print(reduce(lambda x,y: x+y,num_1))
内置函数

内置函数1
print(abs(-1)) #绝对值 print(all([1,2,'1',''])) #对iterable中的各个元素做bool,都不是空的时候是true print(all('hello')) #true print(all('')) #true 特殊情况,只有空的时候返回True print(any([0,''])) #对iterable中的各个元素做bool,有一个不为空就是true print(any([0,'',1])) #true print(bin(3)) #true print(bool(None)) #false 空,None,0的布尔值为False,其余都为True name = ' 你好' print(bytes(name,encoding='utf-8').decode('utf-8')) #解码 print(chr(45)) print(dir(dict)) #查看dict都有什么方法 print(divmod(10,3)) #(3, 1) 3是商,1是余数 dic={'name':'alex'} dic_str=str(dic) print(dic_str) d1 = eval(dic_str) #将字符串str当成有效的表达式来求值并返回计算结果 d1['name'] express = '1+2*(3/3-1)-2' print(eval(express)) 可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型 print(hash('12asdfwer')) name='alex' print(hash(name)) #一次执行都是一样的hash print(hash(name)) print(hash(name)) print(hash(name)) print(bin(10)) #0b1010 十进制-->二进制 print(hex(12)) #0xc 十进制-->十六进制 print(oct(12)) #0o14 十进制-->八进制 print(isinstance(1,int)) #True print(isinstance('abc',str)) name = "asdf" print(globals()) print(__file__)
内置函数2
l = [1,2,100] print(max(l)) #最大值 print(min(l)) #最小值 print(list(zip(('a','b','c','d'),(1,2,3)))) #[('a', 1), ('b', 2), ('c', 3)] 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。 p = {'name':'alex','age':18,'gender':'none'} print(list(zip(p.keys(),p.values()))) print(list(p.keys())) print(list(p.values())) print(list(zip('hello','12345'))) age_dic = {'age1':18,'age4':20,'age3':100,'age2':30} print(max(age_dic.values())) 默认比较的是字典的key print(max(age_dic)) for item in zip(age_dic.values(),age_dic.keys()): print(item) print(list(max(zip(age_dic.values(),age_dic.keys())))) l = [ (1,'b'), (3,'a'), (4,'c') ] ll = ['a10','b12','c10',100] #不同类型之间不能进行比较 print(list(max(l))) print('---->',max(ll)) 1.max 函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较,注意,不同类型之间不能进行比较 2.每个元素间进行比较,是从每个元素的第一个位置一次比较,如果这一个位置分出大小,后面的都不需要比较了,直接得出这俩元素的大小 people=[ {'name':'alex','age':1000}, {'name':'wupei','age':10000}, {'name':'yuan','age':9000}, ] print(max(people,key=lambda dic:dic['age'])) #max key参数的应用 ret = [] for item in people: ret.append(item['age']) print(ret) max(ret) print(ord('a')) print(pow(10,3)) #10**3 print(pow(10,3,2)) #10**3%2 l=[1,2,3,4] print(list(reversed(l))) print(l) print(round(3.5)) l = 'hello' s1=slice(3,5) s2=slice(1,4,2) #用法 slice print(l[s1]) print(l[3:5]) l = [3,2,4,6,9] print(sorted(l)) people=[ {'name':'alex','age':1000}, {'name':'wupei','age':10000}, {'name':'yuan','age':9000}, ] print(sorted(people,key=lambda dic:dic['age'])) name_dic= { 'abyuan':900, 'alex':200, 'wupei':300, } print(sorted(name_dic)) print(sorted(name_dic,key = lambda key:name_dic[key])) print(sorted(zip(name_dic.values(),name_dic.keys()))) print(str('1')) l = [2,3,4,1] print(sum(l)) print(sum(range(5))) #相加 print(type(1)) #查看对象是什么类型 #vars def test(): msg='asdfqwr哈哈水淀粉' print(locals()) #打印局部的变量关系 print(vars()) test() print(vars(int)) import------》sys---->__import__() import test #不能导入字符串 module_name='test' m = __import__(module_name)
函数总结
#####函数========== #计算机函数 === subroutine 子程序 ,procedures 过程 #作用 : 1.减少重复代码 2.方便修改,更易扩展 3.保持代码一致性 #define ##定义 #函数名的命名规则 #函数参数 # import time # # time_format = '%Y-%m-%d %X' # time_current = time.strftime(time_format) # print(time_current) # # def logger(n): # time_format = '%Y-%m-%d %X' # time_current= time.strftime(time_format) # # with open('test1','a') as f: # f.write('time is %s,end action%s\n'%(time_current,n)) # # def action1(n): # print('start action1.....') # logger(n) # # # def action2(n): # print('start action2.....') # logger(n) # # def action3(n): # print('start action3.....') # logger(n) # # action1(1) # action2(2) # action3(3) #位置参数 # def print_info(name,age): # print('Name : %s'%name) # print('Age :%d'%age) # # print_info('xiaoh',37) #1。位置参数调用 必须参数 # print_info(age=36,name='xiaodu') #2.关键字参数 # def print_info(name,age,sex='male'): #3.默认参数 # print('Name : %s'%name) # print('Age :%d'%age) # print('Sex :%s'%sex) # # print_info('xiaoh',40) # print_info('jinxi',42) # print_info('wuchao',12) # print_info('lichun',18,'female') ## 不定长参数 # def add(x,y): # print(x+y) # # add(1,2) # def add(*args): # print(args) # sum = 0 # for i in args: #args=(1, 2, 3, 4, 5) # sum += i # print(sum) # add(1,2,3,4,5) # def print_info(sex='male',*args,**kwargs): # print(sex) # print(args) # #print(kwargs) # # for i in kwargs: # print('%s : %s'%(i,kwargs[i])) # # print('Name : %s'%name) # # print('Age :%d'%age) # # print('Sex :%s'%sex) # # print_info(1,2,3,job='it',hobby='girls') #print_info('ALEX',18,'male',job='it',hobby='girls',height=188) #print_info(1,2,['ales','pp'],(1,2),job='it',hobby='girls',height=188) #关于不定长参数的位置:*args放在左边,**kwargs参数放在右边, #关键字参数,位置参数,不定长参数 #def func(name,age=22,*args,**kwargs) # #函数返回值 # def f(): # print('ok') # return 10 #作用:1结束函数,2 返回某个对象 # #返回什么内容,给谁呢? # # f() # 注意点:1.函数里如果没有return,会默认返回一个None # 2. 如果return多个对象,那么python会帮我们把多个对象封装成一个元组返回 # def foo(): # return 1,2,'234',[1,23] # print(foo()) ######函数作用域 LEGB # x = int(2.9) #int built-in # # g_count = 0 #global # # def outer(): # o_count = 1 #enclosing # i_count = 8 # def inner(): # i_count = 2 # local # print(i_count) # # inner() # outer() # count = 10 # def outer(): # global count # print(count) # count = 5 # print(count) # outer()
open函数,该函数用于文件处理
操作文件时,一般需要经历如下步骤:
- 打开文件
- 操作文件
一、打开文件
|
1
|
文件句柄 = open('文件路径', '模式') |
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
二、操作
f = open('test123','w',encoding='utf-8') #文件存在,清空关闭,如果文件不存在,重新建立文件 f.write('123123123\n') f.write('asdfasfasdf\n') #f.writable() #判断文件可写 #f.writelines(['555\n','6666\n']) #写的内容必须是字符串 f.close() 文件追加 f = open('test123','a',encoding='utf-8') f.write('wo shi haoren\n') f.close() #可读可写 src_f = open('test123','r',encoding='utf-8') # data = f.read() # f.write('1hahahahhahh') #f.write('只会来了') data = src_f.readlines() src_f.close() print(data) dst_f = open('test1','w',encoding='utf-8') dst_f.write(data[0]) dst_f.close() print(data) with open('test1','w') as f: f.write('1111\n') with open('test123','r',encoding='utf-8') as src_f,\ open('test1','w',encoding='utf-8') as dst_f: data= src_f.read() dst_f.write(data)
文件操作2
f = open('test2','w',encoding='utf-8') f.write('111111\n') f.write('111111\n') f.write('111111\n') f.close() f = open('test2','r+',encoding='utf-8') f.write('33333\n') f.write('33333\n') f.close() f = open('test1','rb',encoding='utf-8')#b的方式不能指定编码 这是错的 f = open('test1','rb') data= f.read() #'字符串'---------encode--------》bytes #bytes------------decode-------》'字符串' print(data) print(data.decode('utf-8')) f = open('test2','wb') #f.write(bytes('11111\n',encoding='utf-8')) f.write('wang会'.encode('utf-8')) f = open('test2','ab') #f.write(bytes('11111\n',encoding='utf-8')) f.write('wang会哈'.encode('utf-8')) f = open('test1','w',encoding='utf-8') f = open('test1','r+',encoding='latin-1') data=f.read() print(data) #print(f.closed) #print(f.encoding) f = open('test1','r+',encoding='utf-8',newline='') #读取文件中真正的换行符号 f.flush() #从内存刷新到硬盘上 print(f.tell()) #####光标所在位置 f.readline() print(f.tell()) #print(f.readlines()) #print(f.readlines()) f.seek(3) #用于移动文件读取指针到指定位置 print(f.tell()) print(f.readline()) data = f.read(3) #代表读取3个字符 print(data) f.truncate(15) ##截取15个字符 seek 三种模式,0是默认从开始,1代表相对位置,2代表从末尾 f = open('test1','rb') print(f.tell()) f.seek(10,0) print(f.tell()) f.seek(3,0) print(f.tell()) print(f.tell()) f.seek(-10,2) print(f.read()) print(f.tell()) f.seek(3,1) print(f.tell()) 读取最后一行 data=f.readlines() print(data[-1].decode('utf-8')) for i in f.readlines(): print(i) 循环文件的推荐方式 for i in f: print(i) for i in f: offs=-10 f.seek(-3,2) while True: f.seek(offs,2) data = f.readlines() if len(data) > 1 : print('文件最后一行是%s' %(data[-1].decode(encoding='utf-8'))) break offs*=2
三、管理上下文
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open('log','r') as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 及以后,with又支持同时对多个文件的上下文进行管理,即:
|
1
2
|
with open('log1') as obj1, open('log2') as obj2: pass |
lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
|
1
2
3
4
5
6
7
8
|
# 普通条件语句if 1 == 1: name = 'wupeiqi'else: name = 'alex' # 三元运算name = 'wupeiqi' if 1 == 1 else 'alex' |
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# ###################### 普通函数 ####################### 定义函数(普通方式)def func(arg): return arg + 1 # 执行函数result = func(123) # ###################### lambda ###################### # 定义函数(lambda表达式)my_lambda = lambda arg : arg + 1 # 执行函数result = my_lambda(123) |
递归
利用函数编写如下数列:
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368...
|
1
2
3
4
5
6
7
8
|
def func(arg1,arg2): if arg1 == 0: print arg1, arg2 arg3 = arg1 + arg2 print arg3 func(arg2, arg3) func(0,1) |
练习题
1、简述普通参数、指定参数、默认参数、动态参数的区别
2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
5、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
6、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
|
1
2
3
|
dic = {"k1": "v1v1", "k2": [11,22,33,44]}PS:字典中的value只能是字符串或列表 |
8、写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号