正则表达式
python正则简介
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。
正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
# a=re.findall('hello','wangyaohellowangxiao')
# print(a) 完全匹配
元字符 .
ret = re.findall('w..l','helloworld') #通配符
print(ret)默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
['worl']
^
print(re.findall('^h..l','heolloword'))#开头匹配
>>['heol']
$
print(re.findall('h..l$','wangyaohall'))#结尾匹配
>>['hall']
*
*重复前面字符匹配[0,多次]
print(re.findall('h.*l','wangyaohwangyaohawl')
>> ['hawl']
+
# +匹配前面字符多次[1,无穷]
print(re.findall('ab+','fdhgdgabbbdfsfab'))
>>['abbb','ab']
?
[0,1]个a
print(re.findall('a?b','aaaabfdsdabdfb'))
>>['ab','ab','b']
{m} :匹配前一个字符m次{n,m}匹配前一个字符n到m次
#{0,5}0 到5 个a 若{5}只能是最多5个a 贪婪匹配
print(re.findall('a{0,5}b','b'))
结论: *等价于{0,无穷} +等价于{1,无穷} ?等价于{0,1}
|管道符
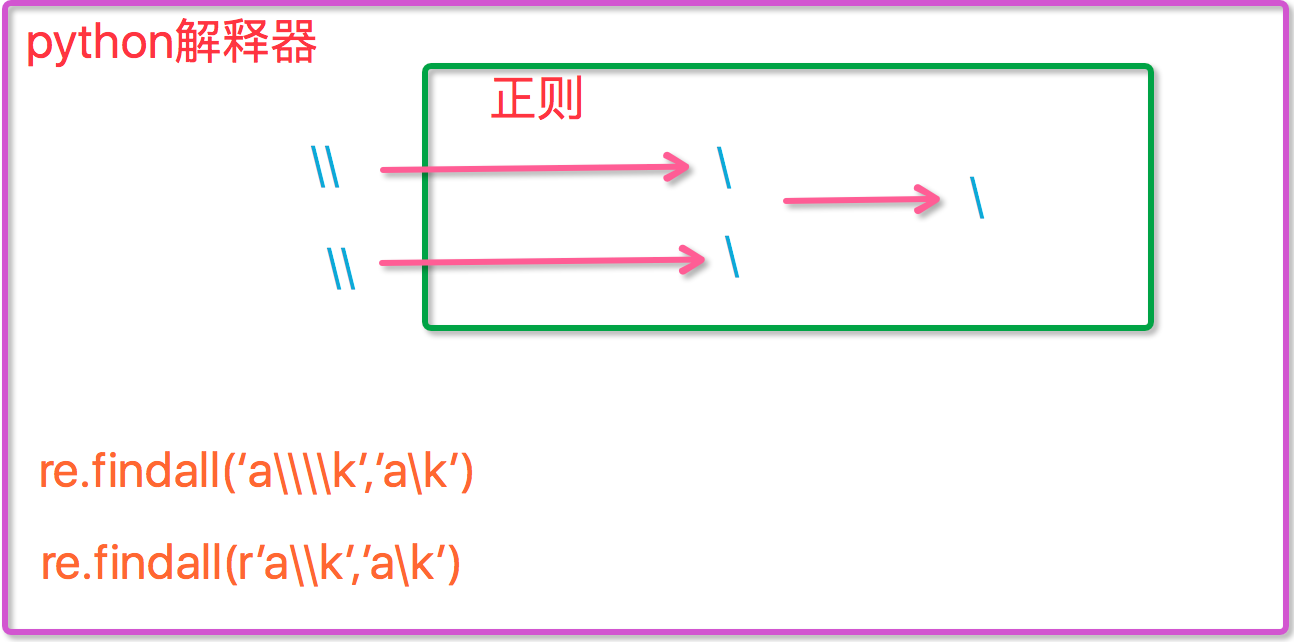
\斜杠 后面跟元字符去除特殊功能 跟普通字符实现特殊功能
正则表达式方法findall()所有的的都返回
search()方法:返回一个对象。对象可以调用group()返回结果匹配到第一个对象
match()方法:只在字符串开始匹配也只返回一个对象调用group方法返回一个结果|匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
(...)分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456cm = re.findall(r'(ad)+', 'add')
print(m)ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')print(ret.group())#23/comprint(ret.group('id'))#23 []
字符集[]里面的元素是或的,[a-z] a到z的1任意一个字符。取消元字符的特殊功能[w,*] *在里面就是一个普通字符
#三个例外(\ ^ -) ^放在[] 表示取反 是里面所有的非 比如[^4,5]匹配'fdhjs45j'除了4和5都匹配
ret=re.findall('a[bc]d','acd')print(ret)#['acd']ret=re.findall('[a-z]','acd')print(ret)#['a', 'c', 'd']ret=re.findall('[.*+]','a.cd+')print(ret)#['.', '+']#在字符集里有功能的符号: - ^ \ret=re.findall('[1-9]','45dha3')print(ret)#['4', '5', '3']ret=re.findall('[^ab]','45bdha3')print(ret)#['4', '5', 'd', 'h', '3']ret=re.findall('[\d]','45bdha3')print(ret)#['4', '5', '3']
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
import reret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')print(ret)#['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')print(ret)#['www.oldboy.com']更多模块:http://www.cnblogs.com/yuanchenqi/articles/5732581.html

