

requests接口测试
pip install requests
r = requests.get('http://www.baidu.com')

payload = {'key1': 'value1', 'key2': 'value2', 'key3': None}
r = requests.get('http://www.baidu.com ', params=payload)
代码
import requests class UseRequestClass(): #get传参的第一种方式 def XWTTMethod(self): r = requests.get("http://v.juhe.cn/toutiao/index?type=guonei&key=4b72107de3a197b3bafd9adacf685790") print(r.text) #get传参的第二种方式 def XWTTMethod(self): params = {"type":"guonei","key":"4b72107de3a197b3bafd9adacf685790"} r = requests.get("http://v.juhe.cn/toutiao/index",params=params) print(r.text)
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
代码
import requests class UseRequestClass(): def XWTTPostMethod(self): params = {"type":"guonei","key":"4b72107de3a197b3bafd9adacf685790"} r = requests.post("http://v.juhe.cn/toutiao/index",params=params) #print(r.status_code) return r.status_code
r.status_code 响应状态码
r.heards 响应头
r.cookies 响应cookies
r.text 响应文本
r. encoding 当前编码
r. content 以字节形式(二进制)返回
最常用的是根据响应状态码判断接口是否连通,经常用于做接口中断言判断
1:添加等待时间 requests.get(url,timeout=1) #超过等待时间则报错 2:添加请求头信息 requests.get(url,headers=headers) #设置请求头 3:添加文件 requests.post(url, files=files) #添加文件
文件传输
url = 'http://httpbin.org/post' files = {'file': open('report.xls', 'rb')} r = requests.post(url, files=files)
读取文件中的数据
requests拿到数据请求接口返回状态码
通过断言验证返回状态码和200对比
生成allure的测试报告
dataDemo(存放数据)>> readDemo(读取数据)
useRequests(发送请求)>>testDemo(生成报告)



代码展示
import csv class ReadCsv(): def readCsv(self): item = [] rr = csv.reader(open("../dataDemo/123.csv")) for csv_i in rr: item.append(csv_i) item = item[1:] return item
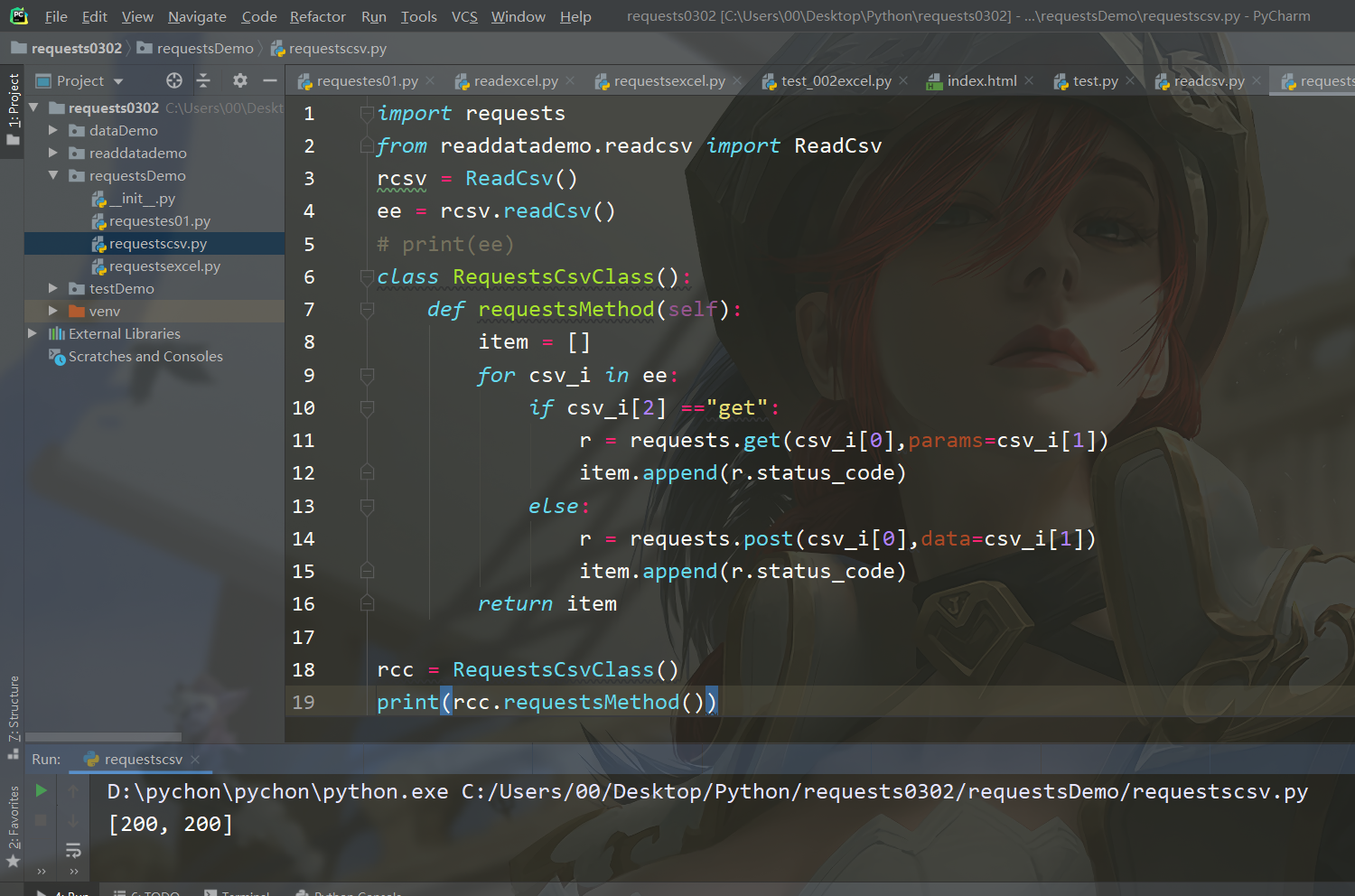
代码
import requests from readdatademo.readcsv import ReadCsv rcsv = ReadCsv() ee = rcsv.readCsv() # print(ee) class RequestsCsvClass(): def requestsMethod(self): item = [] for csv_i in ee: if csv_i[2] =="get": r = requests.get(csv_i[0],params=csv_i[1]) item.append(r.status_code) else: r = requests.post(csv_i[0],data=csv_i[1]) item.append(r.status_code) return item rcc = RequestsCsvClass() print(rcc.requestsMethod())

代码展示
import pytest,allure,os from requestsDemo.requestscsv import RequestsCsvClass rcc = RequestsCsvClass() e = rcc.requestsMethod() class TestClass(): def test001(self): for csv_i in e: assert csv_i == 200 if __name__ == '__main__': pytest.main(['--alluredir', 'report/result', 'test_001csv.py']) split = 'allure ' + 'generate ' + './report/result ' + '-o ' + './report/html ' + '--clean' os.system(split)

网页打开


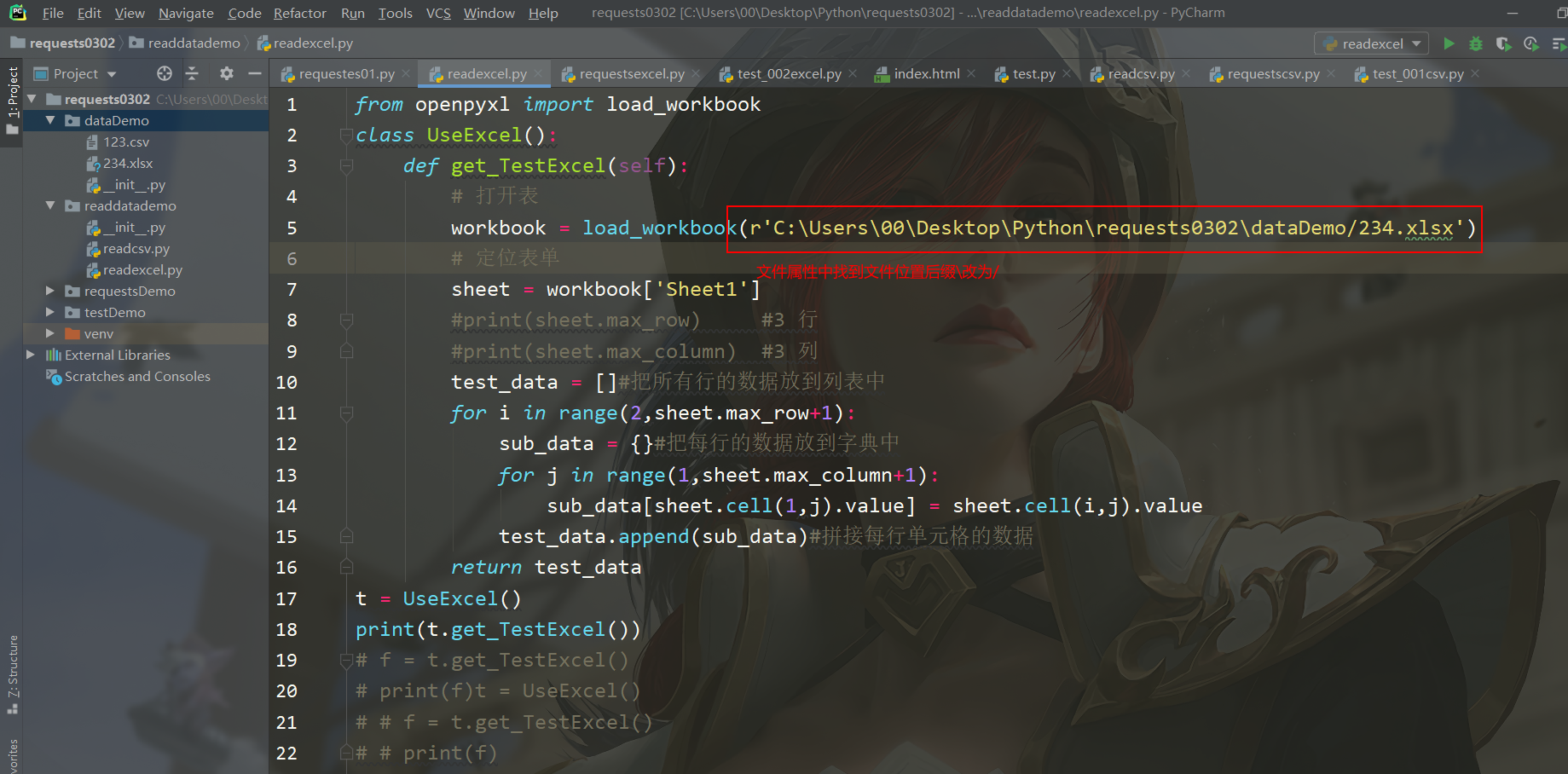
代码展示
from openpyxl import load_workbook class UseExcel(): def get_TestExcel(self): # 打开表 workbook = load_workbook(r'C:\Users\00\Desktop\Python\requests0302\dataDemo/234.xlsx') # 定位表单 sheet = workbook['Sheet1'] #print(sheet.max_row) #3 行 #print(sheet.max_column) #3 列 test_data = []#把所有行的数据放到列表中 for i in range(2,sheet.max_row+1): sub_data = {}#把每行的数据放到字典中 for j in range(1,sheet.max_column+1): sub_data[sheet.cell(1,j).value] = sheet.cell(i,j).value test_data.append(sub_data)#拼接每行单元格的数据 return test_data # t = UseExcel() # print(t.get_TestExcel()) # f = t.get_TestExcel() # print(f)t = UseExcel() # # f = t.get_TestExcel() # # print(f)

代码展示
from readdatademo.readexcel import UseExcel import requests ue = UseExcel() ee = ue.get_TestExcel() class RequestsClass(): def requestsMethod(self): item = [] for excel_i in ee: if excel_i["method"] =="get": r = requests.get(excel_i["url"],params=excel_i["params"]) item.append(r.status_code) else: r = requests.post(excel_i["url"],data=excel_i["params"]) item.append(r.status_code) return item qc = RequestsClass() print(qc.requestsMethod())

代码展示
import pytest,allure,os from requestsDemo.requestsexcel import RequestsClass qc = RequestsClass() ee = qc.requestsMethod() class TestExcelClass(): def test001(self): for excel_i in ee: assert excel_i == 200 if __name__ == '__main__': pytest.main(["-s", "-q", '--alluredir', 'report/result', 'test_002excel.py']) # 将测试报告转为html格式 split = 'allure ' + 'generate ' + './report/result ' + '-o ' + './report/html ' + '--clean' os.system(split)

