
Prometheus监控k8s(12)-PrometheusOperator服务自动发现-监控redis样例
PrometheusOperator服务自动发现-监控redis样例
如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
为解决上面的问题,Prometheus Operator 为我们提供了一个额外的抓取配置的来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。和前面自定义的方式一样,我们想要在 Prometheus Operator 当中去自动发现并监控具有prometheus.io/scrape=true这个 annotations 的 Service,之前我们定义的 Prometheus 的配置如下:
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
建议去查看下前面关于 Kubernetes常用资源对象监控章节的介绍,要想自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
参考
Prometheus监控k8s(4)-grafana监控k8s集群/node/资源对象
Prometheus监控k8s(8)-prometheus配置pod和svc的自动发现和监控
[root@k8s-master manifests]# kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
secret/additional-configs created
[root@k8s-master manifests]#
注意我们所有的操作都在 Prometheus Operator 源码contrib/kube-prometheus/manifests/目录下面。
创建完成后,会将上面配置信息进行 base64 编码后作为 prometheus-additional.yaml 这个 key 对应的值存在:
[root@k8s-master manifests]# kubectl get secret additional-configs -n monitoring -o yaml
apiVersion: v1
data:
prometheus-additional.yaml: LSBqb2JfbmFtZTogJ2t1YmVybmV0ZXMtc2VydmljZS1lbmRwb2ludHMnCiAga3ViZXJuZXRlc19zZF9jb25maWdzOgogIC0gcm9sZTogZW5kcG9pbnRzCiAgcmVsYWJlbF9jb25maWdzOgogIC0gc291cmNlX2xhYmVsczogW19fbWV0YV9rdWJlcm5ldGVzX3NlcnZpY2VfYW5ub3RhdGlvbl9wcm9tZXRoZXVzX2lvX3NjcmFwZV0KICAgIGFjdGlvbjoga2VlcAogICAgcmVnZXg6IHRydWUKICAtIHNvdXJjZV9sYWJlbHM6IFtfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19zY2hlbWVdCiAgICBhY3Rpb246IHJlcGxhY2UKICAgIHRhcmdldF9sYWJlbDogX19zY2hlbWVfXwogICAgcmVnZXg6IChodHRwcz8pCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9hbm5vdGF0aW9uX3Byb21ldGhldXNfaW9fcGF0aF0KICAgIGFjdGlvbjogcmVwbGFjZQogICAgdGFyZ2V0X2xhYmVsOiBfX21ldHJpY3NfcGF0aF9fCiAgICByZWdleDogKC4rKQogIC0gc291cmNlX2xhYmVsczogW19fYWRkcmVzc19fLCBfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19wb3J0XQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IF9fYWRkcmVzc19fCiAgICByZWdleDogKFteOl0rKSg/OjpcZCspPzsoXGQrKQogICAgcmVwbGFjZW1lbnQ6ICQxOiQyCiAgLSBhY3Rpb246IGxhYmVsbWFwCiAgICByZWdleDogX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9sYWJlbF8oLispCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfbmFtZXNwYWNlXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZXNwYWNlCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9uYW1lXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZQo=
kind: Secret
metadata:
creationTimestamp: "2019-10-08T06:00:33Z"
name: additional-configs
namespace: monitoring
resourceVersion: "5474824"
selfLink: /api/v1/namespaces/monitoring/secrets/additional-configs
uid: 26518a5a-e10a-4f6b-8f7c-ccab1f53d8c5
type: Opaque
[root@k8s-master manifests]#
然后我们只需要在声明 prometheus 的资源对象文件中添加上这个额外的配置:(prometheus-prometheus.yaml)
[root@k8s-master manifests]# cat prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
nodeSelector:
kubernetes.io/os: linux
podMonitorSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.11.0
添加完成后,直接更新 prometheus 这个 CRD 资源对象:
[root@k8s-master manifests]# kubectl apply -f prometheus-prometheus.yaml
prometheus.monitoring.coreos.com/k8s configured
隔一小会儿,可以前往 Prometheus 的 Dashboard 中查看配置是否生效:
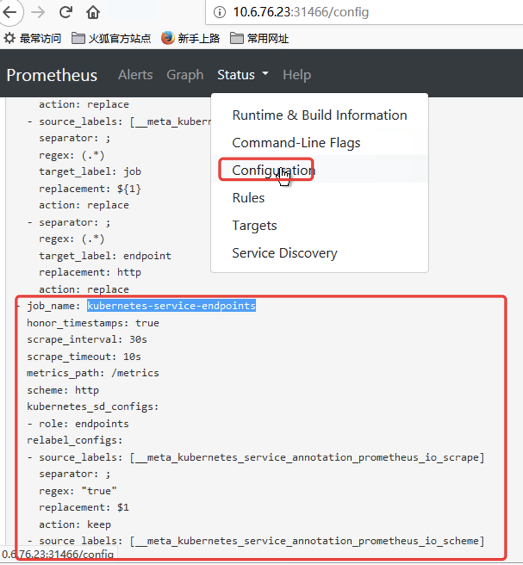
在 Prometheus Dashboard 的配置页面下面我们可以看到已经有了对应的的配置信息了,但是我们切换到 targets 页面下面却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志:
#kubectl logs -f prometheus-k8s-0 prometheus -n monitoring
level=error ts=2019-10-08T06:05:56.184Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:264: Failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"services\" in API group \"\" at the cluster scope"
level=error ts=2019-10-08T06:05:56.185Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:265: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"
可以看到有很多错误日志出现,都是xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:(prometheus-clusterRole.yaml)
[root@k8s-master manifests]# cat prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
上面的权限规则中我们可以看到明显没有对 Service 或者 Pod 的 list 权限,所以报错了,要解决这个问题,我们只需要添加上需要的权限即可:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
[root@k8s-master manifests]# vim prometheus-clusterRole.yaml
[root@k8s-master manifests]# kubectl apply -f prometheus-clusterRole.yaml
clusterrole.rbac.authorization.k8s.io/prometheus-k8s configured
[root@k8s-master manifests]#
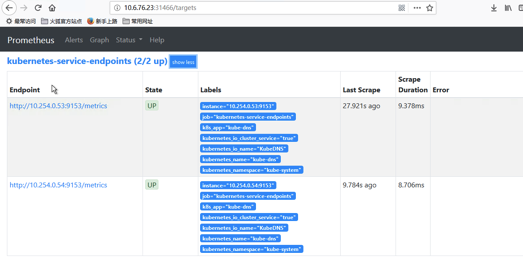
更新上面的 ClusterRole 这个资源对象,等一会,如果5分钟不出现重建下 Prometheus 的所有 Pod,正常就可以看到 targets 页面下面有 kubernetes-service-endpoints 这个监控任务了:
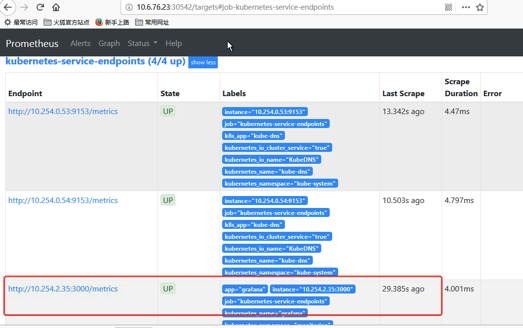
我们对grafana的service进行修改
[root@k8s-master manifests]# cat grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "3000"
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
ports:
- name: http
port: 3000
targetPort: http
selector:
app: grafana
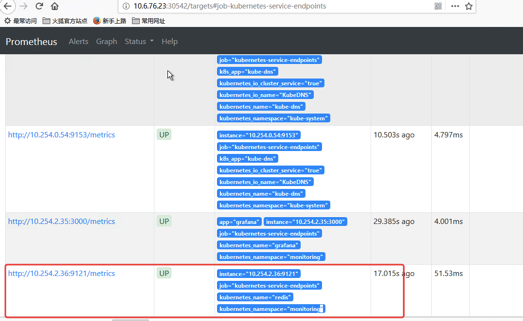
我们这里新建一个redis服务再通过redis-expoter去采集
[root@k8s-master manifests]# cat redis-prom.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: redis
namespace: monitoring
spec:
template:
metadata:
# annotations:
# prometheus.io/scrape: "true"
# prometheus.io/port: "9121"
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
name: redis
namespace: monitoring
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: redis-exporter
port: 9121
targetPort: 9121
[root@k8s-master manifests]# kubectl get pods,svc -n monitoring | grep redis
pod/redis-69987696df-z28pn 2/2 Running 0 6m30s
service/redis ClusterIP 10.96.30.29 <none> 6379/TCP,9121/TCP 6m11s
确认redis-exporter能连接redis
[root@k8s-master manifests]# curl 10.96.30.29:9121/metrics|grep "redis_up 1"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 16934 0 16934 0 0 1877k 0 --:--:-- --:--:-- --:--:-- 2067k
redis_up 1
[root@k8s-master manifests]#
我们可以通过 9121 端口来校验是否能够采集到数据:
[root@k8s-master manifests]# curl 10.96.30.29:9121/metrics
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.2366e-05
go_gc_duration_seconds{quantile="0.25"} 5.2366e-05
go_gc_duration_seconds{quantile="0.5"} 5.2366e-05
go_gc_duration_seconds{quantile="0.75"} 5.2366e-05
go_gc_duration_seconds{quantile="1"} 5.2366e-05
go_gc_duration_seconds_sum 5.2366e-05
go_gc_duration_seconds_count 1
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 6
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.13.1"} 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号