
Prometheus监控k8s(1)-Prometheus简介
Prometheus监控k8s(1)-Prometheus简介
https://github.com/prometheus/prometheus
https://github.com/yunlzheng/prometheus-book
https://www.cnblogs.com/xzkzzz/p/10208115.html
Prometheus介绍
Prometheus是一个最初在SoundCloud上构建的开源监控系统 。它现在是一个独立的开源项目,为了强调这一点,并说明项目的治理结构,Prometheus 于2016年加入CNCF,作为继Kubernetes之后的第二个托管项目。
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库。从字面上理解,Prometheus由两个部分组成,一个是监控报警系统,另一个是自带的时序数据库(TSDB)
特点
- 具有由 metric 名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,有一个灵活的查询语言
- 不依赖分布式存储,只和本地磁盘有关
- 通过 HTTP 的服务拉取时间序列数据
- 也支持推送的方式来添加时间序列数据
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持
架构图
此图说明prometheus的体系结构及其一些系统组件
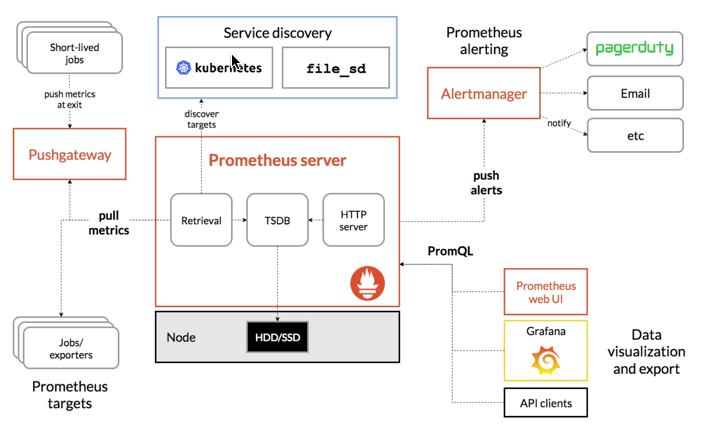
图片左侧是各种数据源主要是各种符合 Prometheus 数据格式的 exporter,除此之外为了支持推动数据 类型的 Agent,可以通过 Pushgateway 组件,将 Push 转化为 Pull。Prometheus 甚至可以从其它的 Prometheus 获取数据,组建联邦集群。 Prometheus 的基本原理是通过 HTTP 周期性抓取被监控组件的状态,任意组件只要提供对应的 HTTP 接口 并且符合 Prometheus 定义的数据格式,就可以接入 Prometheus 监控。
图片的上侧是服务发现,Prometheus 支持监控对象的自动发现机制,从而可以动态获取监控对象。 图片中间是 Prometheus Server,Retrieval 模块定时拉取数据,并通过 Storage 模块保存数据。PromQL 为 Prometheus 提供的查询语法,PromQL 模块通过解析语法树,调用 Storage 模块查询接口获取监控数据。 图片右侧是告警和页面展现,Prometheus 将告警推送到 alertmanger,然后通过 alertmanger 对告警进行处 理并执行相应动作。数据展现除了 Prometheus 自带的 webui,还可以通过 grafana 等组件查询 Prometheus 监控数据。
与其他监控系统的比较
在Prometheus 之前市面已经出现了很多的监控系统,如 Zabbix、Open-falcon 等。那么 prometheus 和这些监控系统有啥异同呢?我们先简单介绍一下这些监控系统
Zabbix 是由 Alexei Vladishev 开源的分布式监控系统,支持多种采集方式和采集客户端,同时支持 SNMP、 IPMI、JMX、Telnet、SSH 等多种协议,它将采集到的数据存放到数据库中,然后对其进行分析整理,如果 符合告警规则,则触发相应的告警。
Zabbix 核心组件主要是 Agent 和 Server,其中 Agent 主要负责采集数据并通过主动或者被动的方式采集数据发送到 Server/Proxy,除此之外,为了扩展监控项,Agent 还支持执行自定义脚本。Server 主要负责 接收 Agent 发送的监控信息,并进行汇总存储,触发告警等。 为了便于快速高效的配置 zabbix 监控项,zabbix 提供了模板机制,从而实现批量配置的目的。
Zabbix Server 将收集的监控数据存储到 Zabbix Database 中。Zabbix Database 支持常用的关系型 数据库,如果 MySQL、PostgreSQL、Oracle 等,默认 是 MySQL。Zabbix Web 页面(PHP 编写)负责数据 查询。Zabbix 由于使用了关系型数据存储时序数据,所以在监控大规模集群时常常在数据存储方面捉襟见 肘。为此 zabbix 4.2 版本后也开始支持时序数据存储,不过目前还不成熟。
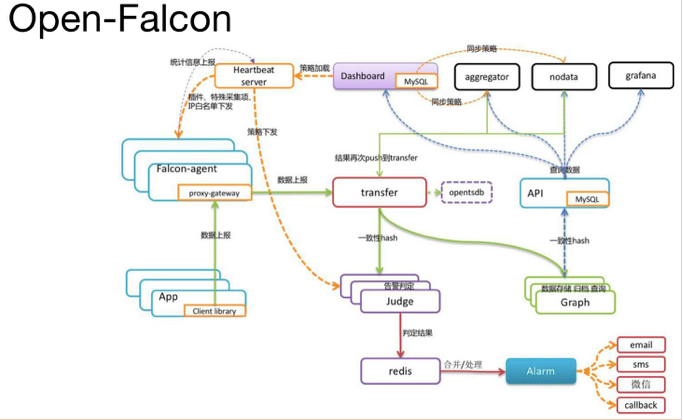
Open-Falcon 是小米开源的企业级监控工具,用 Go 语言开发而成,包括小米、滴滴、美团等在内的互 联网公司都在使用它,是一款灵活、可扩展并且高性能的监控方案,主要组件包括:
Falcon-agent:用 Go 语言开发的 Daemon 程序,运行在每台 Linux 服务器上,用于采集主机上的各种 指标数据,主要包括 CPU、内存、磁盘、文件系统、内核参数、Socket 连接等,目前已经支持 200 多项监 控指标。并且,Agent 支持用户自定义的监控脚本,
Hearthbeat server:简称 HBS 心跳服务,每个 Agent 都会周期性地通过 RPC 方式将自己的状态上报给 HBS,主要包括主机名、主机 IP、Agent 版本和插件版本,Agent 还会从 HBS 获取自己需要执行的采集任务 和自定义插件。
Transfer:负责接收 Agent 发送的监控数据,并对数据进行整理,在过滤后通过一致性 Hash 算法发送 到 Judge 或者 Graph
Graph:RRD 数据上报、归档、存储的组件。Graph 在收到数据以后,会以 rrdtool 的数据归档方式来存 储,同时提供 RPC 方式的监控查询接口。
Judge:告警模块,Transfer 转发到 Judge 的数据会触发用户设定的告警规则,如果满足,则会触发邮 件、微信或者回调接口。这里为了避免重复告警引入了 Redis 暂存告警,从而完成告警的合并和抑制。
Dashboard:面向用户的监控数据查询和告警配置界面
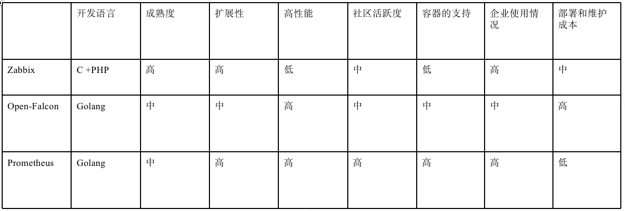
从开发语言上看,为了应对高并发和快速迭代的需求,监控系统的开发语言已经慢慢从 C 语言转移到 Go。不得不说,Go 凭借简洁的语法和优雅的并发,在 Java 占据业务开发,C 占领底层开发的情况下,准确 定位中间件开发需求,在当前开源中间件产品中被广泛应用。
从系统成熟度上看,Zabbix 是老牌的监控系统:Zabbix 是在 1998 年出现的,系统功能比较稳定,成熟 度较高。而 Prometheus 和 Open-Falcon 都是最近几年才诞生的,虽然功能还在不断迭代更新,但站在巨人 的肩膀之上,在架构设计上借鉴了很多老牌监控系统的经验;
从系统扩展性方面看,Zabbix 和 Open-Falcon 都可以自定义各种监控脚本,并且 Zabbix 不仅可以做到 主动推送,还可以做到被动拉取,Prometheus 则定义了一套监控数据规范,并通过各种 exporter 扩展系统 采集能力;
从数据存储方面来看,Zabbix 采用关系数据库保存,这极大限制了 Zabbix 采集的性能,Open-Falcon 采用 RDD 数据存储,并且可以对接到 OpenTSDB,而 Prometheus 自研一套高性能的时序数据库,在 V3 版 本可以达到每秒千万级别的数据存储,通过对接第三方时序数据库扩展历史数据的存储;
从配置和维护的复杂度上看,prometheus 只有一个核心 server 组件,一条命令便可以启动,相比而言, 其他系统配置相对麻烦,尤其是 open-falcon。
从社区活跃度上看,目前 Zabbix 社区活跃度比较低,Open-Falcon 虽然也比较活跃,但基本都是国内 的公司参与,Prometheus 在这方面占据绝对优势,社区活跃度最高,并且受到 CNCF 的支持,后期的发展 值得期待;
从容器支持角度看,由于 Zabbix 出现得比较早,当时容器还没有诞生,自然对容器的支持也比较差。 Open-Falcon 虽然提供了容器的监控,但支持力度有限。Prometheus 的动态发现机制,不仅可以支持 swarm 原生集群,还支持 Kubernetes 容器集群的监控,是目前容器监控最好解决方案。Zabbix 在传统监控系统中, 尤其是在服务器相关监控方面,占据绝对优势。伴随着容器的发展,Prometheus 开始成为主导及容器监控 方面的标配,并且在未来可见的时间内被广泛应用。总体来说,对比各种监控系统的优劣,Prometheus 可 以说是目前监控领域最锋利的“瑞士军刀”了。
Prometheus 数据结构和类型

指标格式分为两个部分:一份是指标名称,另一个是指标标签。
标签可体现指标的维度特征,用于过滤和聚合。它通过标签名(label name)和标签值(label value) 这种键值对的形式,形成多种维度。
例如 , 对 于 指 标 http_request_total , 可 以 有 {status="200", method="POST"} 和 {status="200", method="GET"}这两个标签。在需要分别获取 GET 和 POST 返回 200 的请求时,可分别使用上述两种指标; 在需要获取所有返回 200 的请求时,可以通过 http_request_total{status="200"}完成数据的聚合,非常便捷 和通用。
指标类型有四种:
l Counter(计数器):计数统计,累计多长或者累计多少次等。它的特点是只增不减,譬如 HTTP 访问总 量
l Gauge(仪表盘):数据是一个瞬时值,如果当前内存用量,它随着时间变化忽高忽低。
如果需要了解某个时间段内请求的响应时间,通常做法是使用平均响应时间,但这样做无法体现数据的 长尾效应。例如,一个 HTTP 服务器的正常响应时间是 30ms,但有很少几次请求耗时 3s,通过平均响应时 间很难甄别长尾效应,
l Histogram(直方图):服务端分位,不同区间内样本的个数,譬如班级成绩,低于 60 分的 9 个,低于 70 分的 10 个,低于 80 分的 50 个
l Summary(摘要):客户端分位,直接在客户端通过分位情况,还是用班级成绩举例:0.8 分位的是 80 分,0.9 分为 85 分,0.99 分为的是 98 分
Prometheus 数据采集
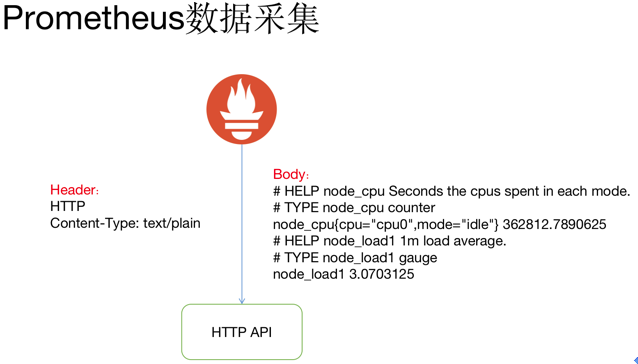
Prometheus 通过 HTTP 接口的方式从各种客户端获取数据,这些客户端必须符合 Prometheus 监控数 据格式,通常由两种方式,一直是侵入式埋点监控,通过在客户端集成如果 kubernetes API 直接通过引入 Prometheus go client,提供/metrics 接口查询 kubernetes API 各种指标,另一种是通过 exporter 方式,在外 部将原来各种中间件的监控支持转化为 Prometheus 的监控数据格式,如 redis exporter 将 reids 指标转化为 Prometheus 能够识别的 HTTP 请求。
Prometheus 并没有采用 json 的数据格式,而是采用 text/plain 纯文本的方式 ,这是它的特殊之处。 HTTP 返回 Header 和 Body 如上图所示,指标前面两行#是注释,标识指标的含义和类型。指标和指标的值 通过空格分割,开发者通常不需要自己拼接这种个数的数据, Prometheus 提供了各种语言的 SDK 支持。
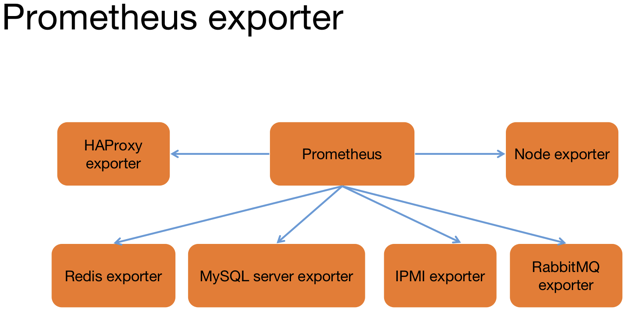
Prometheus 为了支持各种中间件以及第三方的监控提供了 exporter,大家可以把它理解成监控适配器, 将不同指标类型和格式的数据统一转化为 Prometheus 能够识别的指标类型。
譬如 Node exporter 主要通过读取 linux 的/proc 以及/sys 目录下的系统文件获取操作系统运行状态, reids exporter 通过 reids 命令行获取指标,mysql exporter 通过读取数据库监控表获取 mysql 的性能数据。 他们将这些异构的数据转化为标准的 Prometheus 格式,并提供 HTTP 查询接口。
Prometheus 数据存储

Prometheus 提供了两种数据持久化方式:一种是本地存储,通过 Prometheus 自带的 tsdb(时序数据 库),将数据保存到本地磁盘,为了性能考虑,建议使用 SSD。但本地存储的容量毕竟有限,建议不要保存 超过一个月的数据。Prometheus本地存储经过多年改进,自Prometheus2.0 后提供的V3版本tsdb性能已 经非常高,可以支持单机每秒 1000w 个指标的收集。
Prometheus 本地数据存储能力一直为大家诟病,但 Prometheus 本地存储设计的初衷就是为了监控数 据的查询,Facebook 发现 85%的查询是针对 26 小时内的数据。所以 Prometheus 本地时序数据库的设计 更多考虑的是高性能而非分布式大容量。
另一种是远端存储,适用于大量历史监控数据的存储和查询。通过中间层的适配器的转化,Prometheus 将数据保存到远端存储。适配器实现 Prometheus 存储的 remote write 和 remote read 接口并把数据转化为 远端存储支持的数据格式。目前,远端存储主要包括 OpenTSDB、InfluxDB、Elasticsearch、M3db 等,其中 M3db 是目前非常受欢迎的后端存储。
prometheus查询语言 PromQL
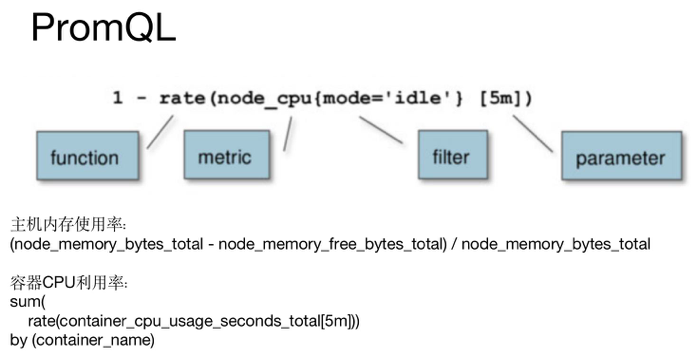
和关系型数据库的 SQL 类型,Prometheus 也内置了数据查询语言 PromQL,它提供对时间序列数据丰 富的查询,聚合以及逻辑运算的能力。
数据运算包括了
+ (加法)
- (减法)
* (乘法)
/ (除法)
% (求余)
^ (幂运算)
聚合包括了
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (标准差)
stdvar (标准差异)
count (计数)
count_values (对 value 进行计数)
bottomk (后 n 条)
topk (前 n 条)
quantile (分布统计)
如果需要获取某个时刻的数据可以通过
curl 'http://Prometheus地址:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z' 查询监控数据,其中 query 参数就是一个 PromQL 表达式。
还支持范围查询 query_range,需要额外添加下面的参数:
start=: 起始时间。
end=: 结束时间。
step=: 查询步长。
Prometheus 数据展现除了自带的 webui 还可以通过 grafana,他们本质上都是通过 HTTP + PromQL 的 方式查询 Prometheus 数据。
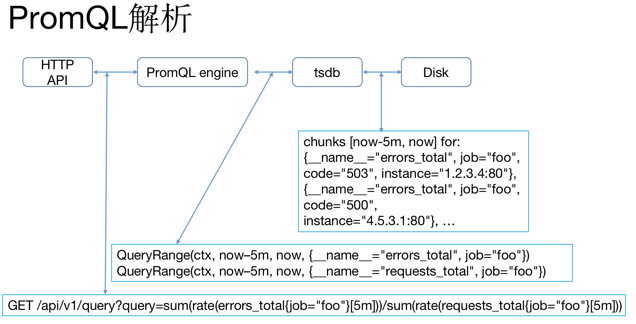
Prometheus 提供了 HTTP 查询接口,当接收到请求参数后,通过 PromQL 引擎解析 PromQL,确定查 询的数据序列和时间范围,通过 tsdb 接口获取对应数据块(chunks),最后根据聚合函数处理监控数据并返回。
Prometheus 告警
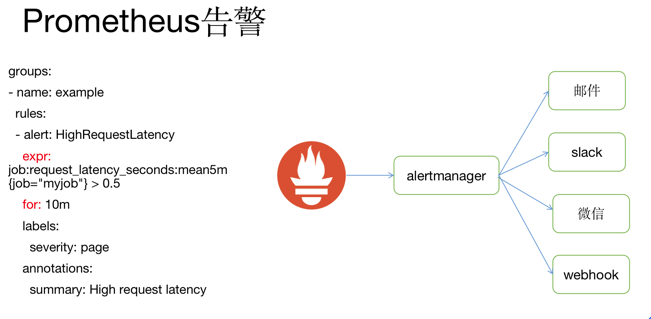
如果监控数据达到告警阈值 Prometheus Server 会通过 HTTP 将告警发送到告警模块 alertmanger。 Prometheus 告警配置也是通过 yaml 文件,核心是上面的 expr 表达式(告警规则)和查询一样也是一个 PromQL 表达式。 for 代表持续时间,如果在 for 时间内持续触发 Prometheus 才发出告警
告警组件 alertmanger 地址是在 Prometheus 的配置文件中指定,告警经过 alertmanger 去重、抑制等 操作,最后执行告警动作,目前支持邮件、slack、微信和 webhook,如果是对接钉钉,便可以通过 webhook 方式触发钉钉的客户端发送告警
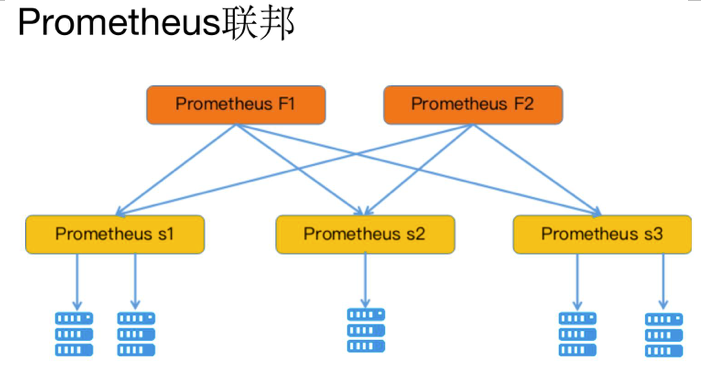
Prometheus 联邦
为了扩展单个 Prometheus 的采集能力和存储能力,Prometheus 引入了“联邦”的概念。多个 Prometheus 节点组成两层联邦结构,如图所示,上面一层是联邦节点,负责定时从下面的 Prometheus 节点获取数据并 汇总,部署多个联邦节点是为了实现高可用以及数据汇聚存储。下层的 Prometheus 节点又分别负责不同区 域的数据采集,在多机房的事件部署中,下层的每个 Prometheus 节点可以被部署到单独的一个机房,充当 代理。
Prometheus 与 kubernetes
Prometheus 的流行和 kubernetes 是密不可分的,下面将介绍 Prometheus 和 kubernetes 结合的内容
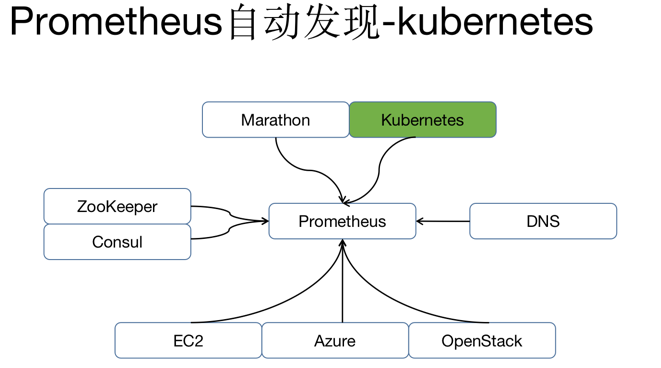
Prometheus 配置告警对象有两种方式,一种是通过静态文件配置,另一种是动态发现机制,自动完成 数据采集。
Prometheus 动态发现目前已经支持 Kubernetes、etcd、Consul 等多种服务发现机制,动态发现机制可 以减少运维人员手动配置,在容器运行环境中尤为重要,容器集群通常在几千甚至几万的规模,如果每个容 器都需要单独配置监控项不仅需要大量工作量,而且容器经常变动,后续维护更是异常麻烦。
如果 kubernetes 环境的动态发现,Prometheus 通过 watch kubernetes api 动态获取当前集群所有主机、 容器以及服务的变化情况。
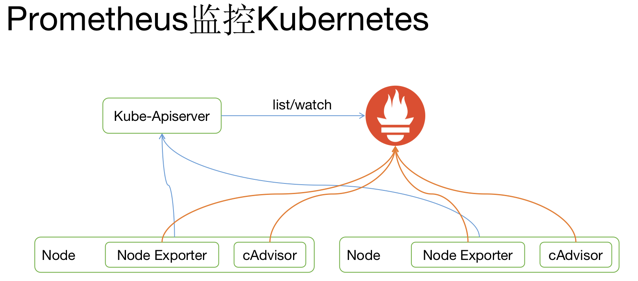
通过自动发现机制,prometheus 可以动态获取 Node 和 Pod 的变化,将 Node exporter 和 cAdvisor 加 入监控。
针对容器常用的监控指标包括:
CPU 利用率
rate(container_cpu_usage_seconds_total{
container_name="xxx" }[5m]
)
内存用量(使用内存减去缓存)
container_memory_usage_bytes{ container_name="xxx"
} -
container_memory_cache{ container_name="xxx"
}
网络发送速率
rate(container_network_transmit_bytes_total{ pod_name="xxxx"
}[5m]
)
网络接收速率
rate(container_network_receive_bytes_total{ pod_name="xxxx"
}[5m] )
prometheusOperator
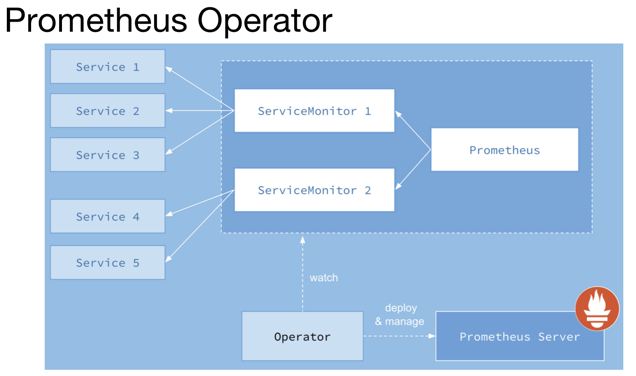
和其他的 k8s 的 Operator 类似,Prometheus Operator 通过定义了下面四种 k8s 的 CRD 资源,从而
实现的操作 k8s 资源去管理 prometheus 的监控和告警的目标。
Prometheus:Prometheus Deployment 定义
ServiceMonitor:Prometheus 监控对象的定义
PrometheusRule:告警规则
Alertmanager:Alertmanager Deployment 定义
HPA
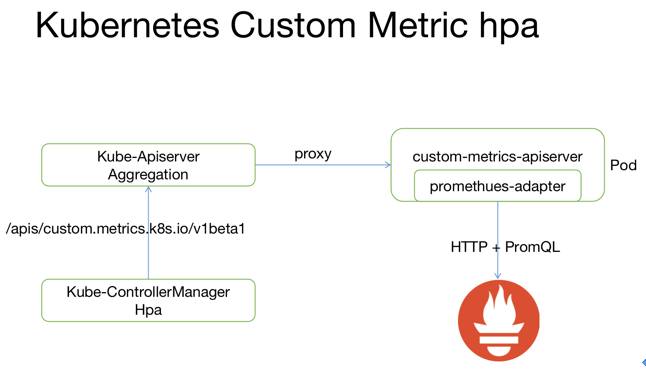
hpa 是 k8s 提供的水平伸缩服务,原生支持基于 CPU 利用率的扩缩容。如果用户希望根据自定义指标 (如 QPS)扩容可以借助 k8s 的 custom metrics api。
k8s 资源扩展通常由两种方式,一种是通过上面 Operator 使用的 CRD,另一种是通过 Aggregated API Server(未来可能会被 Kubebuilder 代替)。 custom-metrics-apiserver 便是通过 Aggregated API 扩展 k8s 的 custom metric 接口。
Hpa 查询自定义监控数据的请求通过 kube-apiserver 代理到 custom-metrics-apiserver,并通过 prometheus-adapter 转化为对 prometheus 数据查询,从而实现自定义指标的扩缩容。
最后Prometheus 并非监控银弹
首先,Prometheus 只针对性能和可用性监控,并不具备日志监控等功能,并不能通过 Prometheus 解 决所有监控问题。
其次,Prometheus 认为只有最近的监控数据才有查询的需要,所有 Prometheus 本地存储的设计初衷 只是保持短期(一个月)的数据,并非针对大量的历史数据的存储。如果需要报表之类的历史数据,则建议 使用 Prometheus 的远端存储如 OpenTSDB、M3db 等。
Prometheus 还有一个小瑕疵是没有定义单位,这里需要使用者自己去区分或者事先定义好所有监控数 据单位。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号