
ELK(13):ELK+kafka+filebeat(海量日志)
ELK(13):ELK+kafka+filebeat(海量日志)
https://blog.51cto.com/cloumn/blog/240
https://www.cnblogs.com/whych/p/9958188.html
使用filebeat收集日志直接写入kafka,然后再由logstash从kafka读取写到elasticsearch。

如果还是遇到性能瓶颈
使用filebeat收集日志,先转发到beat端的logstash1,然后logstash1转发到kafka,然后再由logstash2从kafka读取写到elasticsearch。
https://mp.weixin.qq.com/s/F8TVva8tDgN0tNsUcLoySg
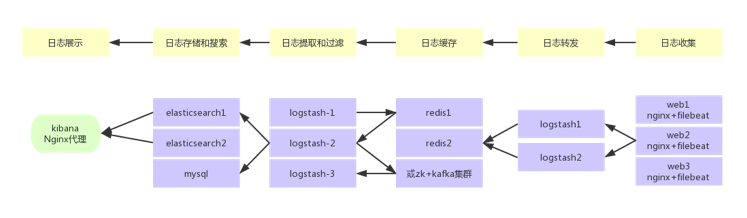
整个系统一共含有10台主机(filebeat部署在客户端,不计算在内),其中Logstash有四台,Elasticsearch有二台,Kafka集群三台,kibana一台并配置Nginx代理。
架构解释:
(1)首先用户通过nginx代理访问ELK日志统计平台,这里的Nginx可以设置界面密码。
(2)Nginx将请求转发到kibana
(3)kibana到Elasticsearch中去获取数据,这里的Elasticsearch是两台做的集群,日志数据会随机保存在任意一台Elasticsearch服务器。
(4)Logstash1从Kafka中取出数据并发送到Elasticsearch中。
(5)Kafka服务器做日志数据的持久化保存,避免web服务器日志量过大的时候造成的数据收集与保存不一致而导致日志丢失,其中Kafka可以做集群,然后再由Logstash服务器从Kafka持续的取出数据。
(6)logstash2从Filebeat取出的日志信息,并放入Kafka中进行保存。
(7)Filebeat在客户端进行日志的收集。
注1:【Kafka的加入原因与作用】
整个架构加入Kafka,是为了让整个系统更好的分层,Kafka作为一个消息流处理与持久化存储软件,能够帮助我们在主节点上屏蔽掉多个从节点之间不同日志文件的差异,负责管理日志端(从节点)的人可以专注于向 Kafka里生产数据,而负责数据分析聚合端的人则可以专注于从 Kafka内消费数据。所以部署时要把Kafka加进去。
而且使用Kafka进行日志传输的原因还在于其有数据缓存的能力,并且它的数据可重复消费,Kafka本身具有高可用性,能够很好的防止数据丢失,它的吞吐量相对来说比较好并且使用广泛。可以有效防止日志丢失和防止logsthash挂掉。综合来说:它均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,
注2:【双层的Logstash作用】
这里为什么要在Kafka前面增加二台logstash呢?是因为在大量的日志数据写入时,容易导致数据的丢失和混乱,为了解决这一问题,增加二台logstash可以通过类型进行汇总分类,降低数据传输的臃肿。
如果只有一层的Logstash,它将处理来自不同客户端Filebeat收集的日志信息汇总,并且进行处理分析,在一定程度上会造成在大规模日志数据下信息的处理混乱,并严重加深负载,所以有二层的结构进行负载均衡处理,并且职责分工,一层汇聚简单分流,一层分析过滤处理信息,并且内层都有二台Logstash来保障服务的高可用性,以此提升整个架构的稳定性。
接下来分别说明原理与各个组件之间的交互(配置文件)。
1 安装filebeat
Filebeat配置参考手册 sudo rpm -ivh filebeat-7.2.0-x86_64.rpm #配置文件在/etc/filebeat #[admin@ris-1 filebeat]$ ls #fields.yml filebeat.reference.yml filebeat.yml filebeat.yml_bak modules.d
2 filebeat收集系统日志输出到文件
2.1 配置
enabled: true 改一下,否则打印不出来,这个坑的啊!网上还找不到文章。
https://www.elastic.co/guide/en/beats/filebeat/current/file-output.html#_literal_enabled_literal_14
#[admin@ris-1 filebeat]$ pwd #/etc/filebeat #[admin@ris-1 filebeat]$ sudo cat filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/*.log - /var/log/messages filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: output.file: path: "/tmp/" filename: filebeat processors: - add_host_metadata: ~ - add_cloud_metadata: ~
2.2 服务启动
sudo systemctl restart filebeat sudo systemctl status filebeat
2.3 查看日志文件
tail -f /tmp/filebeat 日志是json格式
{"@timestamp":"2019-07-19T08:34:20.637Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.2.0"},"host":{"architecture":"x86_64","os":{"family":"redhat","name":"CentOS Linux","kernel":"3.10.0-123.el7.x86_64","codename":"Core","platform":"centos","version":"7 (Core)"},"id":"6a0204048ec74c879526b4a6bc131c07","containerized":false,"name":"ris-1","hostname":"ris-1"},"agent":{"hostname":"ris-1","id":"178be62d-8b55-42f8-ae83-7d217b6b9806","version":"7.2.0","type":"filebeat","ephemeral_id":"9b9bdff3-b5db-44f5-9353-46aa71aacc6f"},"log":{"offset":1652416,"file":{"path":"/var/log/messages"}},"message":"11","input":{"type":"log"},"ecs":{"version":"1.0.0"}}
2.4 添加fields标签
6.2版本 之后取消了filebeat的prospectors里面配置document_type类型,新增一个fields字段
配置
#[admin@ris-1 filebeat]$ sudo cat filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/*.log - /var/log/messages fields: service : "ris-1-systemlog-filebeat" filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: output.file: path: "/tmp/" filename: filebeat processors: - add_host_metadata: ~ - add_cloud_metadata: ~
输出日志
另一个窗口
sudo echo '11' | sudo tee -a /var/log/messages
{"@timestamp":"2019-07-19T08:55:09.753Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.2.0"},"message":"11","input":{"type":"log"},"fields":{"service":"ris-1-systemlog-filebeat"},"ecs":{"version":"1.0.0"},"host":{"name":"ris-1","hostname":"ris-1","architecture":"x86_64","os":{"platform":"centos","version":"7 (Core)","family":"redhat","name":"CentOS Linux","kernel":"3.10.0-123.el7.x86_64","codename":"Core"},"id":"6a0204048ec74c879526b4a6bc131c07","containerized":false},"agent":{"version":"7.2.0","type":"filebeat","ephemeral_id":"aaa7e375-9ef6-4bb9-a62a-d75f5aea477f","hostname":"ris-1","id":"178be62d-8b55-42f8-ae83-7d217b6b9806"},"log":{"offset":1704952,"file":{"path":"/var/log/messages"}}}
3 filebeat写入logstash
3.1 logstash开启接收,输出到控制台
#admin@ris-1 ~]$ cat /etc/logstash/conf.d/beats.conf input { beats { port => "5044" codec => "json" } } output { stdout { codec => "rubydebug" } }
3.2 前台启动logstash
sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/beats.conf -t sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/beats.conf
3.3 filebeat输出系统日志到logstsh
配置
#只能写一个输出源,写入logstash就不能输出到文件,很奇怪 [admin@ris-1 filebeat]$ sudo cat filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/*.log - /var/log/messages fields: service : "ris-1-systemlog-filebeat" filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: output.logstash: hosts: ["10.6.75.171:5044"] #logstash地址可以是多个,我这里是本机,其实没必要 #hosts:["192.168.108.191:5044", "192.168.108.87:5044"] # 发往二台Logstash-collect loadbalance: true #loadbalance: false # 消息只是往一个logstash里发,如果这个logstash挂了,就会自动将数据发到另一个logstash中。(主备模式) #loadbalance: true # 如果为true,则将数据均分到各个logstash中,挂了就不发了,往存活的logstash里面发送。 worker: 2 #线程数 #compression_level: 3 #压缩级别 #output.file: # path: "/tmp/" # filename: filebeat
输出
sudo echo '---------------' | sudo tee -a /var/log/messages
logstash前台查看
{ "message" => "---------------", "host" => { "name" => "ris-1" }, "@version" => "1", "tags" => [ [0] "_jsonparsefailure", [1] "beats_input_codec_json_applied" ], "log" => { "file" => { "path" => "/var/log/messages" }, "offset" => 3864943 }, "fields" => { "service" => "ris-1-systemlog-filebeat" }, "input" => { "type" => "log" }, "@timestamp" => 2019-07-20T01:01:04.156Z, "ecs" => { "version" => "1.0.0" }, "agent" => { "hostname" => "ris-1", "version" => "7.2.0", "id" => "178be62d-8b55-42f8-ae83-7d217b6b9806", "type" => "filebeat", "ephemeral_id" => "4c5284f4-6ba0-4227-a3da-3cd72603c1a2" } }
4 logstash输出到kafka
4.1 查看kafka的topic
查看kafka的topic,如果之前创建了一个ris-1-systemlog-filebeat,为了方便识别,建议先删除,等logstash再次自动创建。之前没有创建肯定更好啊。
/home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181
[admin@pe-jira ~]$ /home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181 __consumer_offsets messagetest ris-1-systemlog ris-api-nginx-1 [admin@pe-jira ~]$
4.2 filebeat配置
filebeat.inputs: - type: log enabled: true paths: - /var/log/*.log - /var/log/messages fields: service : "ris-1-systemlog-filebeat" #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 pattern: '^[' negate: true match: after # Excludelines. A list of regular expressions to match. It drops the lines that are # # 删除以DBG开头的行: # exclude_lines: ['^DBG'] output.logstash: hosts: ["10.6.75.171:5044"] #logstash地址可以是多个,我这里是本机,其实没必要 worker: 1 #开启线程数 compression_levle: 3 #压缩级别 #hosts: ["192.168.108.191:5044","192.168.108.87:5044"] # 发往二台Logstash-collect #loadbalance: true #loadbalance: false # 消息只是往一个logstash里发,如果这个logstash挂了,就会自动将数据发到另一个logstash中。(主备模式) #loadbalance: true # 如果为true,则将数据均分到各个logstash中,挂了就不发了,往存活的logstash里面发送。
4.3 接收Logstash配置
#[admin@ris-1 conf.d]$ cat /etc/logstash/conf.d/beats.conf input { beats { port => "5044" codec => "json" } } output { if [fields][service] == "ris-1-systemlog-filebeat" { kafka { bootstrap_servers => "10.6.76.27:9092,10.6.76.28:9092,10.6.76.18:9092" topic_id => "ris-1-systemlog-filebeat" batch_size => "5" codec => "json" } } }
4.4 重启filebeat和logstash
sudo systemctl restart logstash sudo systemctl restart filebeat
4.5 再次查看kafka的topic
#查看到topic说明filebeat-logstash-kafka是通的
/home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181
[admin@pe-jira ~]$ /home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181 __consumer_offsets messagetest ris-1-systemlog ris-1-systemlog-filebeat ris-api-nginx-1
4.6 logstash从kafka读数据写入elasticsearch
前台查看logstash接收
配置
[admin@pe-jira conf.d]$ cat /etc/logstash/conf.d/sys-kafka-es.conf input{ kafka { bootstrap_servers => "10.6.76.27:9092" #kafka服务器地址 topics => "ris-1-systemlog-filebeat" group_id => "systemlog-filebeat" decorate_events => true #kafka标记 consumer_threads => 1 codec => "json" #写入的时候使用json编码,因为logstash收集后会转换成json格式 } } output{ stdout { codec => "rubydebug" } }
日志
{ "fields" => { "multiline" => { "pattern" => "^[", "match" => "after", "negate" => true }, "service" => "ris-1-systemlog-filebeat" }, "input" => { "type" => "log" }, "@version" => "1", "message" => "Jul 22 10:29:01 ris-1 systemd: Started Session 581591 of user admin.", "agent" => { "hostname" => "ris-1", "type" => "filebeat", "id" => "178be62d-8b55-42f8-ae83-7d217b6b9806", "ephemeral_id" => "3bd63afa-c26d-4088-9288-a19a6fc5399d", "version" => "7.2.0" }, "ecs" => { "version" => "1.0.0" }, "host" => { "name" => "ris-1" }, "tags" => [ [0] "_jsonparsefailure", [1] "beats_input_codec_json_applied" ], "@timestamp" => 2019-07-22T02:29:01.409Z, "log" => { "file" => { "path" => "/var/log/messages" }, "offset" => 14606656 } }
服务方式启动
配置
#[admin@pe-jira conf.d]$ cat /etc/logstash/conf.d/sys-kafka-es.conf input{ kafka { bootstrap_servers => "10.6.76.27:9092" #kafka服务器地址 topics => "ris-1-systemlog-filebeat" group_id => "systemlog-filebeat" decorate_events => true #kafka标记 consumer_threads => 1 codec => "json" #写入的时候使用json编码,因为logstash收集后会转换成json格式 } } output{ # stdout { # codec => "rubydebug" # } #if [type] == "ris-1-systemlog-filebeat"{ if [fields][service] == "ris-1-systemlog-filebeat" { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-ris-1-systemlog-beat-%{+YYYY.MM.dd}" } } }
#启动
sudo systemctl restart logstash
5 添加到kibana
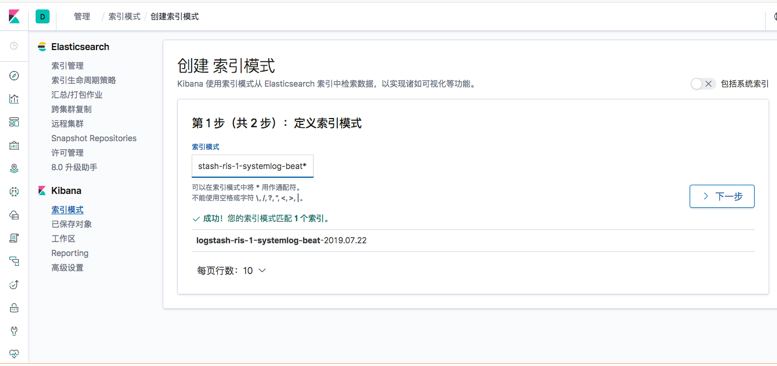
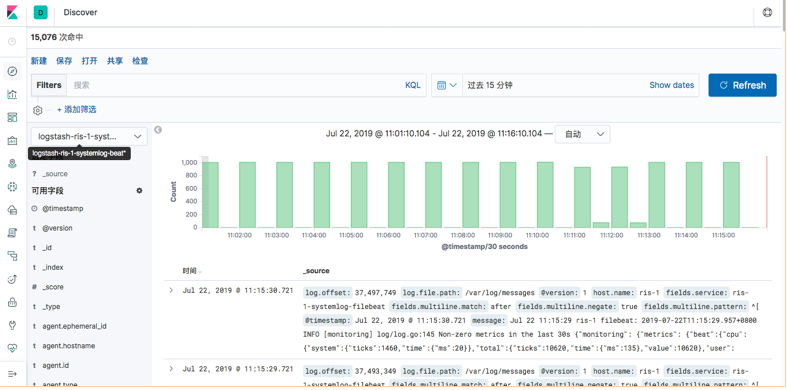
6 收集Nginx日志
6.1 filebeat配置
#追加到系统日志配置后面的 #[admin@ris-1 filebeat]$ sudo cat /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/*.log - /var/log/messages fields: service : "ris-1-systemlog-filebeat" #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 pattern: '^[' negate: true match: after # Excludelines. A list of regular expressions to match. It drops the lines that are # # 删除以DBG开头的行: exclude_lines: ['^DBG'] exclude_lines: ['.gz$'] #收集Nginx日志 - type: log enabled: true paths: - /home/admin/webserver/logs/api/api.log fields: service : "ris-1-api-nginx" #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 pattern: '^[' negate: true match: after # Excludelines. A list of regular expressions to match. It drops the lines that are # # 删除以DBG开头的行: exclude_lines: ['^DBG'] exclude_lines: ['.gz$'] output.logstash: hosts: ["10.6.75.171:5044"] #logstash地址可以是多个,我这里是本机,其实没必要 worker: 1 #开启线程数 compression_levle: 3 #压缩级别 #hosts: ["192.168.108.191:5044","192.168.108.87:5044"] # 发往二台Logstash-collect #loadbalance: true #loadbalance: false # 消息只是往一个logstash里发,如果这个logstash挂了,就会自动将数据发到另一个logstash中。(主备模式) #loadbalance: true # 如果为true,则将数据均分到各个logstash中,挂了就不发了,往存的logstash里面发送。 [admin@ris-1 filebeat]$
6.2 logstash收集配置
#追加到系统日志配置后面的 #[admin@ris-1 filebeat]$ cat /etc/logstash/conf.d/beats.conf input { beats { port => "5044" codec => "json" } } output { if [fields][service] == "ris-1-systemlog-filebeat" { kafka { bootstrap_servers => "10.6.76.27:9092,10.6.76.28:9092,10.6.76.18:9092" topic_id => "ris-1-systemlog-filebeat" batch_size => "5" codec => "json" } } if [fields][service] == "ris-1-api-nginx" { kafka { bootstrap_servers => "10.6.76.27:9092,10.6.76.28:9092,10.6.76.18:9092" topic_id => "ris-1-api-nginx" batch_size => "5" codec => "json" } } } [admin@ris-1 filebeat]$
6.3 kafka查看topic
/home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181
[admin@pe-jira ~]$ /home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181|grep ris-1-api-nginx ris-1-api-nginx [admin@pe-jira ~]$
6.4 logstash写入elasticsearch
[admin@pe-jira conf.d]$ cat /etc/logstash/conf.d/ris-1-nginx-kafka-es.conf input{ kafka { bootstrap_servers => "10.6.76.27:9092" #kafka服务器地址 topics => "ris-1-api-nginx" group_id => "ris-api-nginx" decorate_events => true #kafka标记 consumer_threads => 1 codec => "json" #写入的时候使用json编码,因为logstash收集后会转换成json格式 } } output{ if [fields][service] == "ris-1-api-nginx" { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-ris-1-api-nginx-%{+YYYY.MM.dd}" } } } [admin@pe-jira conf.d]$
6.5 添加kibana
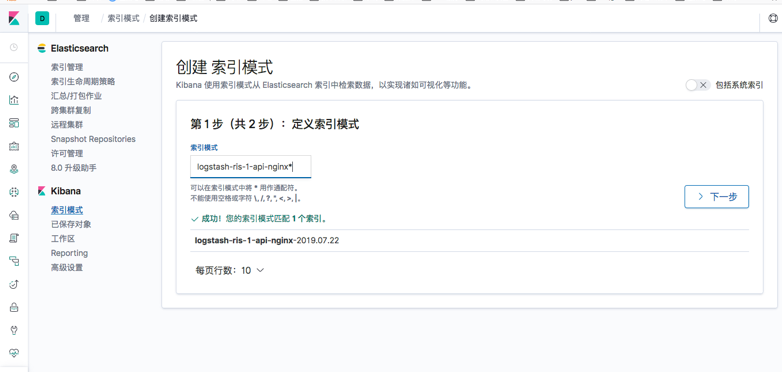

7 收集Java日志
java日志需要正则匹配
例如 [22 12:00:00,003 DEBUG] [mqScheduler-9] spring.SqlSessionUtils - Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5c90e795] 正则 ^\[[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}
7.1 filebeat配置
#Nginx混写到一起了 #[admin@ris-1 filebeat]$ sudo cat /etc/filebeat/filebeat.yml filebeat.inputs: #- type: log # enabled: true # paths: # - /var/log/*.log # - /var/log/messages # fields: # service : "ris-1-systemlog-filebeat" # #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 # #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. # multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 # pattern: '^[' # negate: true # match: after ## Excludelines. A list of regular expressions to match. It drops the lines that are ## # 删除以DBG开头的行: # exclude_lines: ['^DBG'] # exclude_lines: ['.gz$'] # #收集Nginx日志 - type: log enabled: true paths: - /home/admin/webserver/logs/api/api.log fields: service : "ris-1-api-nginx" #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 pattern: '^[' negate: true match: after # Excludelines. A list of regular expressions to match. It drops the lines that are # # 删除以DBG开头的行: exclude_lines: ['^DBG'] exclude_lines: ['.gz$'] #收集java日志 - type: log enabled: true paths: - /home/admin/ris-api-8080/logs/catalina.out fields: service : "ris-1-api-catalina" #service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断 #条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略. multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。 pattern: '^\[[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}' negate: true match: after # Excludelines. A list of regular expressions to match. It drops the lines that are # # 删除以DBG开头的行: #exclude_lines: ['^DBG'] #我想打印debug exclude_lines: ['.gz$'] output.logstash: hosts: ["10.6.75.171:5044"] #logstash地址可以是多个,我这里是本机,其实没必要 worker: 1 #开启线程数 compression_levle: 3 #压缩级别 #hosts: ["192.168.108.191:5044","192.168.108.87:5044"] # 发往二台Logstash-collect #loadbalance: true #loadbalance: false # 消息只是往一个logstash里发,如果这个logstash挂了,就会自动将数据发到另一个logstash中。(主备模式) #loadbalance: true # 如果为true,则将数据均分到各个logstash中,挂了就不发了,往存活的logstash里面发送。
7.2 logstash收集配置
##Nginx混写到一起了 #[admin@ris-1 filebeat]$ cat /etc/logstash/conf.d/beats.conf input { beats { port => "5044" codec => "json" } } output { if [fields][service] == "ris-1-api-nginx" { kafka { bootstrap_servers => "10.6.76.27:9092,10.6.76.28:9092,10.6.76.18:9092" topic_id => "ris-1-api-nginx" batch_size => "5" codec => "json" } } if [fields][service] == "ris-1-api-catalina" { kafka { bootstrap_servers => "10.6.76.27:9092,10.6.76.28:9092,10.6.76.18:9092" topic_id => "ris-1-api-catalina" batch_size => "5" codec => "json" } } }
7.3 kafka查看topic
/home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181
[admin@pe-jira ~]$ /home/admin/elk/kafka/bin/kafka-topics.sh --list --zookeeper kafka1:2181, kafka2:2181, kafka3:2181 __consumer_offsets messagetest ris-1-api-catalina ris-1-api-nginx ris-1-systemlog ris-1-systemlog-filebeat ris-api-nginx-1 [admin@pe-jira ~]$ [admin@pe-jira ~]$
7.4 logstash写入elasticsearch
#[admin@pe-jira ~]$ cat /etc/logstash/conf.d/ris-1-catalina-kafka-es.conf input{ kafka { bootstrap_servers => "10.6.76.27:9092" #kafka服务器地址 topics => "ris-1-api-catalina" group_id => "ris-api-catalina" decorate_events => true #kafka标记 consumer_threads => 1 codec => "json" #写入的时候使用json编码,因为logstash收集后会转换成json格式 } } output{ if [fields][service] == "ris-1-api-catalina" { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-ris-1-api-catalina-%{+YYYY.MM.dd}" } } }
7.5 添加kibana
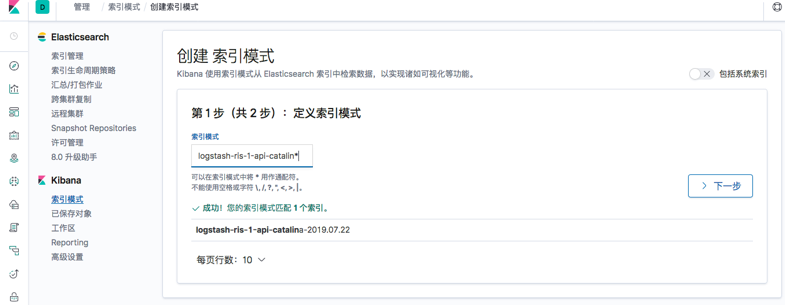
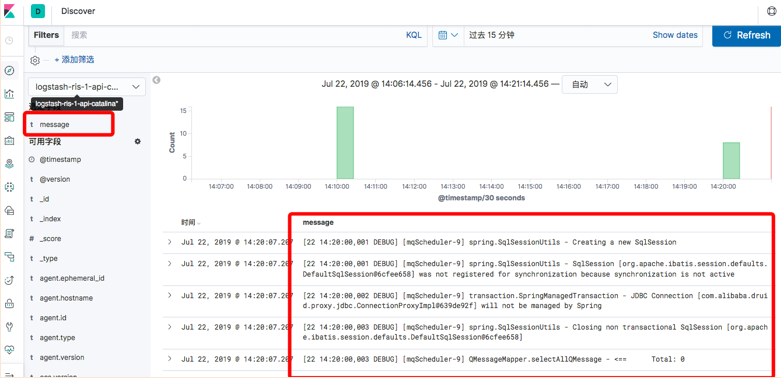
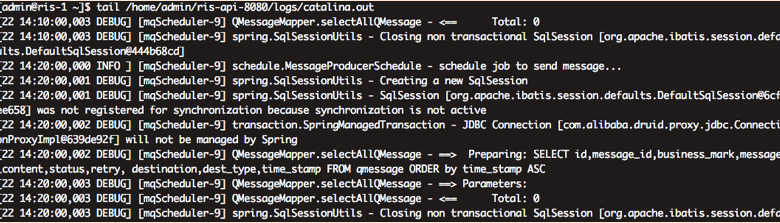

 浙公网安备 33010602011771号
浙公网安备 33010602011771号