
ELK(7):ELK-logstash收集tomcat(java)日志
ELK(7):ELK-logstash收集tomcat(java)日志
https://www.cnblogs.com/bixiaoyu/p/9665677.html
tomcat主要有两种日志类型,即访问日志(localhost_access_log.Y-M-D.txt)以及运行状态日志(catalina.out)
localhost_access_log.Y-M-D.log:访问日志主要是记录访问的时间,IP以及访问的资料等相关信息
catalina.out其实记录了tomcat运行状态信息以及异常告警信息等
accesslog
tomcat配置文件修改accesslog
server.xml
首先是locathost_accesslog.Y-M-D.log访问日志,将日志输出定义为json格式,方便后续kibana展示
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
改成
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access." suffix=".log" pattern="{"client":"%h", "client user":"%l", "authenticated":"%u", "access time":"%t", "method":"%r", "status":"%s", "send bytes":"%b", "Query?string":"%q", "partner":"%{Referer}i", "Agent version":"%{User-Agent}i"}"/>
directory:日志文件存放的位置
prefix:日志文件名称前缀
suffix:日志名称后缀
pattern:是一个json解析字段的参数
"client":"%h"其中%h表示请求的主机名称,这里指的是请求端的IP
"client user":"%l"其中%l记录的是刘拉着进行身份验证时提供的名称
"authenticated":"%u" 其中%u代表获得验证的访问请求者,否则就是"-"
"access time":"%t" 其中%t代表请求的时间
"method":"%r" 其中%r代表请求的方法和URL
"status":"%s" 其中%s代表HTTP的响应状态码
"send bytes":"%b" 其中%b代表发送请求的字节数,但不包括请求http头部信息
"Query?string":"%q" 其中%q指的是查询字符串的意思
#tail -f tomcat_access2018-09-18.log
{"client":"192.168.2.10", "client user":"-", "authenticated":"-", "access time":"[18/Sep/2018:17:17:12 +0800]", "method":"GET /favicon.ico HTTP/1.1", "status":"200", "send bytes":"21630", "Query?string":"", "partner":"http://192.168.2.101:8080/", "Agent version":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
在线json校验
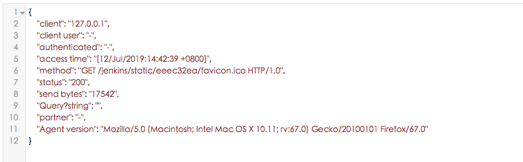
logstash文件
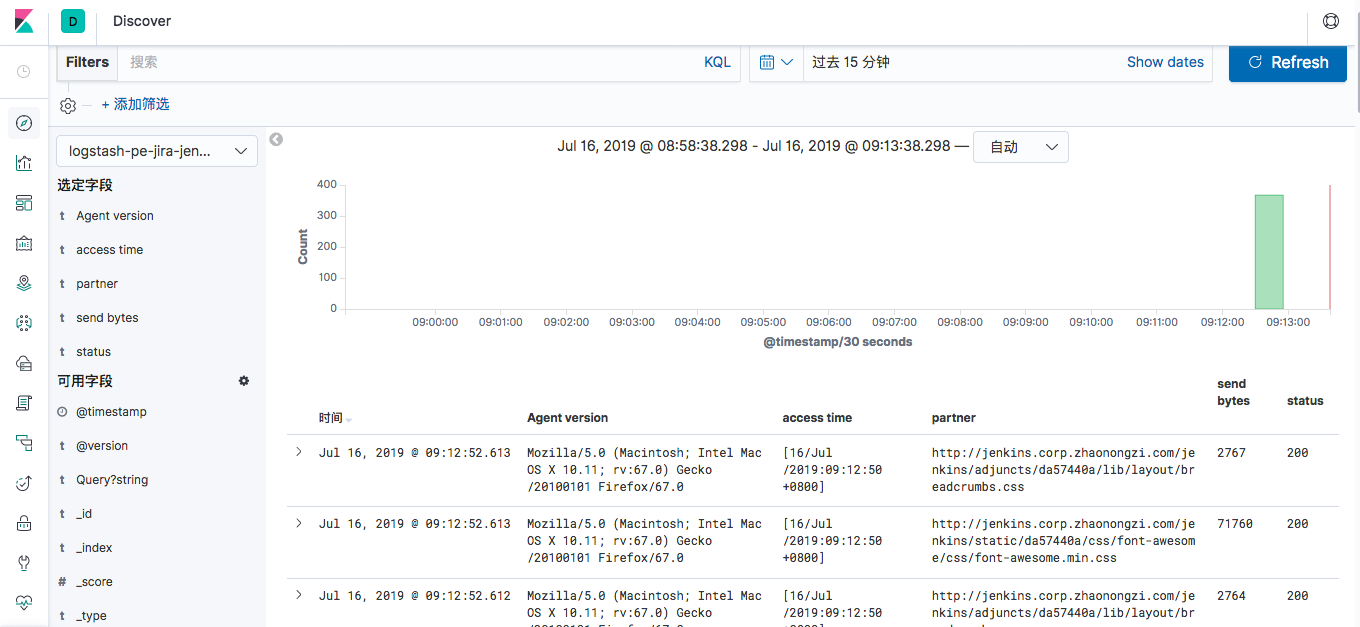
input { file { type => "pe-jira-jenkins-access" path => "/home/admin/jenkins/logs/localhost_access.*.log" start_position => "beginning" stat_interval => "2" codec => "json" } } #如果在input 中添加 codec = json 我设置不起作用,采用这个方式 #filter{ # json { # source => "message" # skip_on_invalid_json => true # } # } output { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-pe-jira-jenkins-access-%{+YYYY.MM.dd}" } }
测试
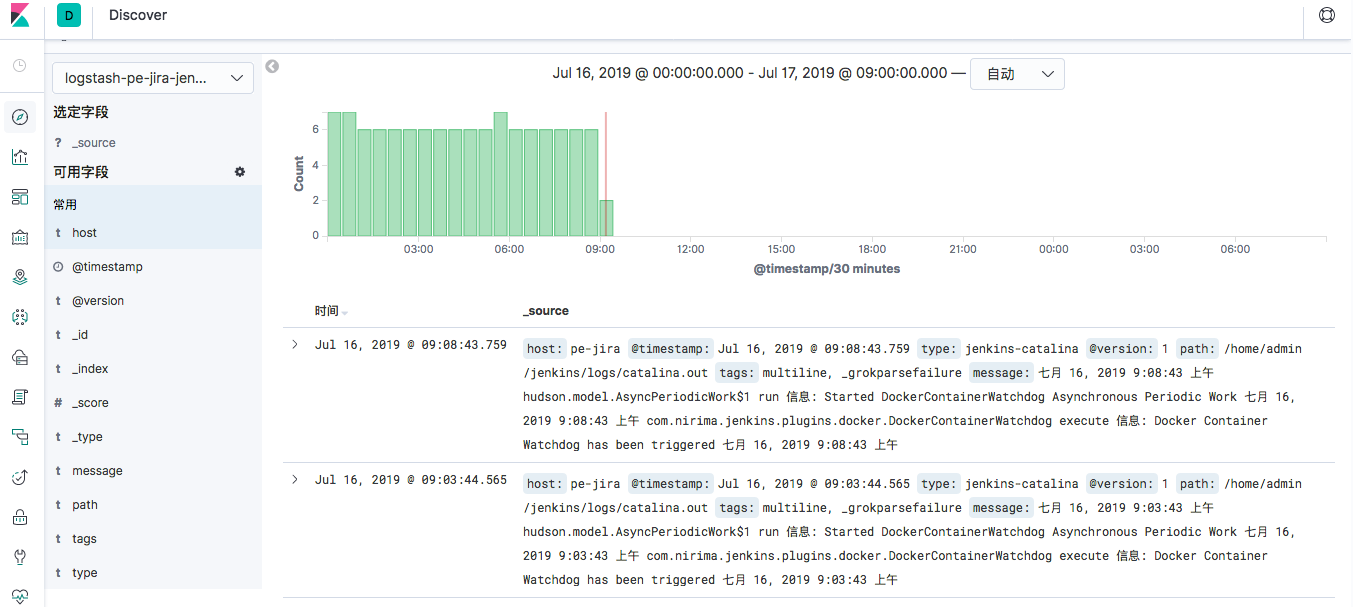
catalina.out处理
这个默认会分行处理,但日志很多错误都连起来看才有价值,我们安装一个logstash-filter-multiline
插件,合并一下日志,多行匹配
https://www.cnblogs.com/centos2017/p/9306471.html
https://blog.csdn.net/ljx1528/article/details/82588636
multiline 使用方法
codec =>multiline {
charset=>... #可选 字符编码
max_bytes=>... #可选 bytes类型 设置最大的字节数
max_lines=>... #可选 number类型 设置最大的行数,默认是500行
multiline_tag... #可选 string类型 设置一个事件标签,默认是multiline
pattern=>... #必选 string类型 设置匹配的正则表达式
patterns_dir=>... #可选 array类型 可以设置多个正则表达式
negate=>... #可选 boolean类型 默认false不显示,可设置ture
what=>... #必选 向前previous , 向后 next
}
## negate 只支持布尔值,true 或者false,默认为false。
如果设置为true,表示与正则表达式(pattern)不匹配的内容都需要整合,
具体整合在前还是在后,看what参数。如果设置为false,即与pattern匹配的内容
## what 前一行 或者后一行,指出上面对应的规则与前一行内容收集为一行,还是与后一行整合在一起
简单来说:
negate默认是 false,不显示
与patten匹配的行
由what决定 向前或向后 匹配
negate 设置为true
则与patten 不匹配的行
由what决定 向前或向后 匹配
logstash配置文件
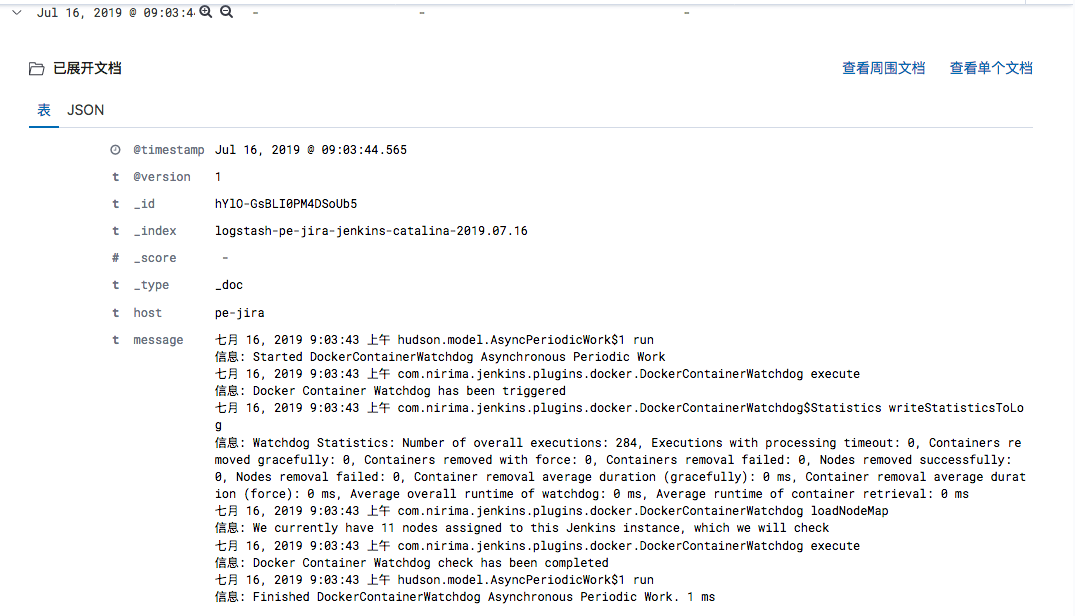
input { file { type => "pe-jira-jenkins-access" path => "/home/admin/jenkins/logs/localhost_access.*.log" start_position => "beginning" stat_interval => "2" codec => "json" } file { type => "jenkins-catalina" path => ["/home/admin/jenkins/logs/catalina.out" ] codec => plain{ charset => "UTF-8" } } } ####### filter { if [type] == "jenkins-catalina"{ multiline { pattern => "(^%{TOMCAT_DATESTAMP})|(^%{CATALINA_DATESTAMP})" negate => true what => "previous" } if "_grokparsefailure" in [tags] { drop { } } grok { match => [ "message", "%{TOMCATLOG}", "message", "%{CATALINALOG}" ] } date { match => [ "timestamp", "yyyy-MM-dd HH:mm:ss,SSS Z", "MMM dd, yyyy HH:mm:ss a" ] } } } ########## output { if [type] == "pe-jira-jenkins-access" { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-pe-jira-jenkins-access-%{+YYYY.MM.dd}" } } if [type] == "jenkins-catalina" { elasticsearch { hosts => ["10.6.76.27:9200"] index => "logstash-pe-jira-jenkins-catalina-%{+YYYY.MM.dd}" } } }
测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号