
ELK(3):ELK-安装elasticsearch
ELK(3):ELK-安装elasticsearch
版本7集群模式
https://www.cnblogs.com/aubin/p/8012840.html
1 创建用户
sudo useradd elasticsearch
2 新建日志和数据目录
mkdir /home/admin/elk/elasticsearch sudo chown -R elasticsearch: /home/admin/elk/elasticsearch
3 配置
cluster.name: elk-cluster1 #集群名称 node.name: elk-node-1 #另一台集群只有这个地方不一样 #集群节点id,唯一 path.data: /home/admin/elk/elasticsearch/data #数据 path.logs: /home/admin/elk/elasticsearch/logs #日志 network.host: 10.6.76.27 #主机或IP http.port: 9200 #http端口 cluster.initial_master_nodes: ["elk-node-1"] #设置默认master节点,7.0版本新特性,否则加入不了集群,很坑,head插件也用不了。集群中可以成为master节点的节点名,这里指定唯一的一个,防止脑裂 discovery.seed_hosts: ["10.6.76.27", "10.6.76.28"] #广播区域
4 启动
#启动 sudo systemctl daemon-reload sudo systemctl start elasticsearch
[admin@pe-jira soft]$ curl "10.6.76.28:9200" { "name" : "elk-node-2", "cluster_name" : "elk-cluster1", "cluster_uuid" : "_na_", "version" : { "number" : "7.2.0", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "508c38a", "build_date" : "2019-06-20T15:54:18.811730Z", "build_snapshot" : false, "lucene_version" : "8.0.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } [admin@pe-jira soft]$
5 安装插件
head
只需要一个节点安装即可
https://github.com/mobz/elasticsearch-head#running-with-built-in-server
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head sudo yum install npm -y npm install grunt -save ll node_modules/grunt npm install npm run start & #后台启动 #open http://localhost:9100/
elasticsearch.yml配置文件增加,重启elasticsearch
http.cors.enabled: true http.cors.allow-origin: "*"
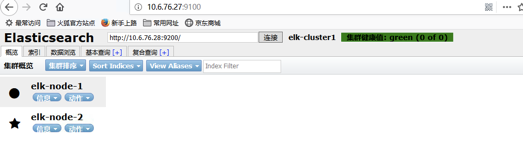
6 优化
安装走到这一步再优化,否则会报错
修改内存限制
https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
##Set Xmx and Xms to no more than 50% of your physical RAM #物理内存的一半
#but can be as large as 30 GB on some systems #30G左右
要尽量到进程的地址空间锁定到RAM中,防止任何Elasticsearch内存被交换出去
修改elasticsearch.yml中的配置: bootstrap.memory_lock: true
后期数据比较多时,运行比较快
/usr/lib/systemd/system/elasticsearch.service 添加,然后重启 [Service] LimitMEMLOCK=infinity #可以最大化使用内存 vim /etc/elasticsearch/jvm.options #默认1G -Xms1g -Xmx1g
sudo systemctl daemon-reload sudo systemctl restart elasticsearch
7 裂脑大坑
两个同时重启后出现以下错误,选不出master,可能跟之前的历史数据有关系,我清空历史数据,重启就OK 了。
master not discovered or elected yet, an election requires a node with id
8 cat查看信息
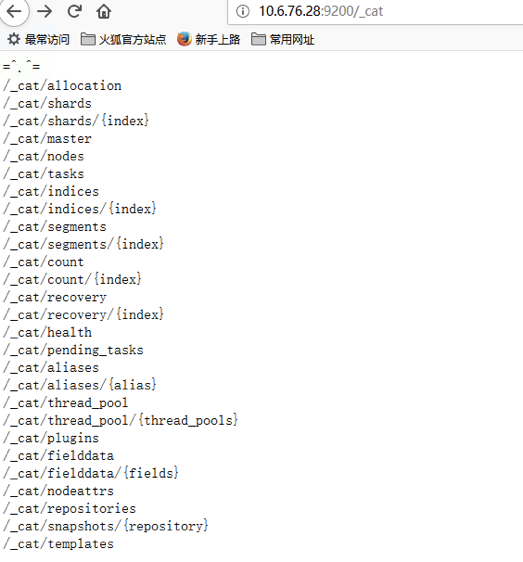
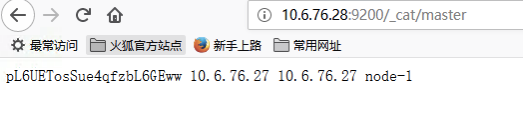
9 es监控(status)
shell
curl -sXGET http://10.6.76.28:9200/_cluster/health?pretty=true { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 1, "active_shards" : 2, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
python
#[admin@pe-jira elk]$ cat elasticsearch.py #!/usr/bin/nev python #coding:utf8 import subprocess body = '' false = 'false' obj = subprocess.Popen(("curl -sXGET http://10.6.76.28:9200/_cluster/health?pretty=true"),shell=True,stdout=subprocess.PIPE) data = obj.stdout.read() #print(data) data1 = eval(data) status = data1.get("status") if status == "green" : print("\033[32melasticesearch集群状态好\033[0m") else: print("发短信啦,发邮件啦") print("\033[31m集群有点问题了\033[0m"]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号