
CS231n 2016 通关 第五章 Training NN Part1
在上一次总结中,总结了NN的基本结构。
接下来的几次课,对一些具体细节进行讲解。
比如激活函数、参数初始化、参数更新等等。
=========================================================================================
首先,课程做 一个小插曲:

经常使用已经训练好的模型》》Finetune network
具体例子:
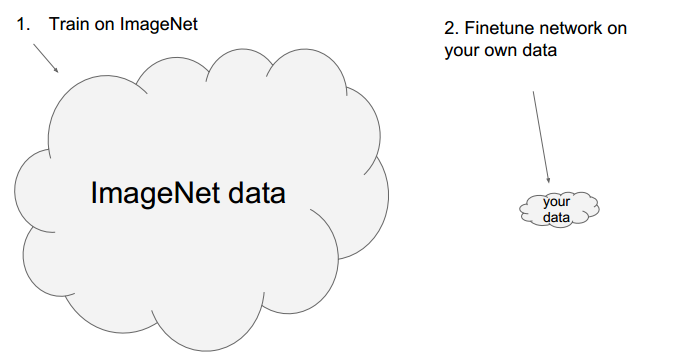

使用现成模型,修改部分层,使用现成的参数做初始参数。
以caffe为例,其提供了很多现成的模型:
https://github.com/BVLC/caffe/wiki/Model-Zoo
使用Finetune 主要是计算资源有限。

其次是上节课主要内容的简单回顾:

概括了NN的主要流程: 得到数据 ---》前向传播 ---》反向传播 ---》更新参数
另外便是链式法则:


实例:


NN的结构特点:
加入非线性:

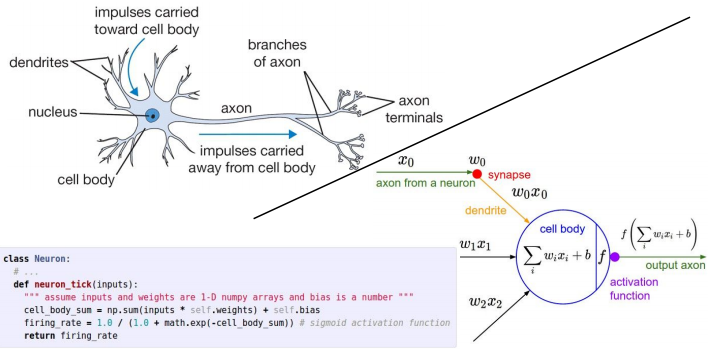
与神经系统比较:
多层NN结构:
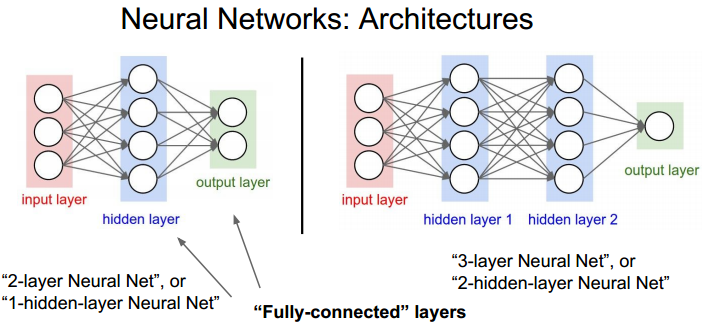
注意: 有些资料把输入层也算在NN的层数里。
=========================================================================================
本章的内容如下:
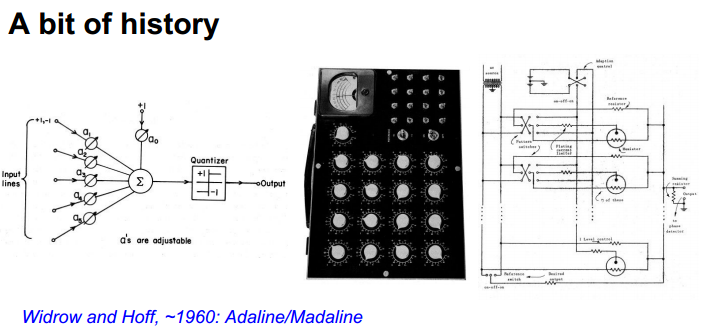
一些历史回顾
简单的字母识别系统:

当时就使用了伪梯度下降。其实不是严格可导。
之后形成了网络结构,并使用电路实现:
进一步形成了多层网络:

反向传播算法开始流行起来。
Deep Learning :
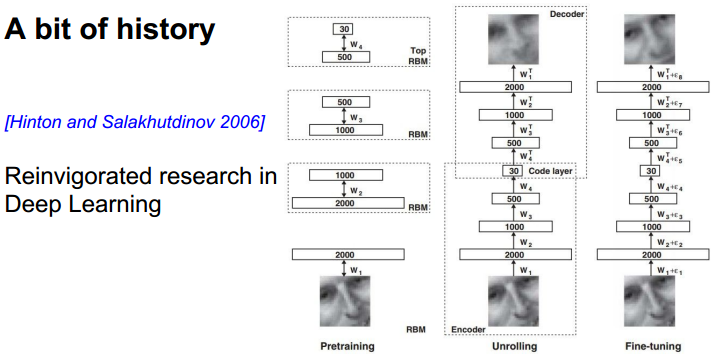
使用了非监督学习进行预处理,然后将得到的结果放到back propagation中。如今不需要这样做了。
技术革新:

2012年的图像分类结果最优。从此DL火起来了。
技术内容总览:

=========================================================================================
1、激活函数
激活函数的作用:

常用激活函数:

Sigmoid:特点以及缺陷
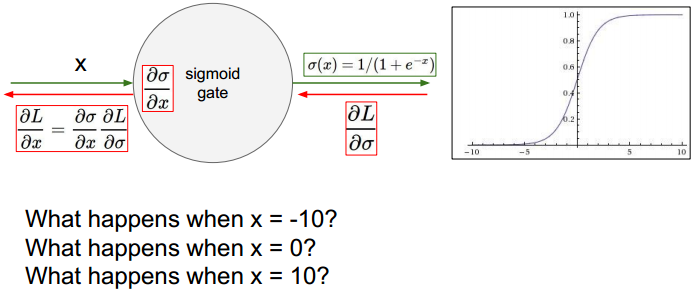

比较左侧s输入值与经过f后的输出值,会导致梯度消失、数值溢出。


当输入为正时,偏导均为正或均为负。

tanh:

仍然会有梯度消失的后果。
ReLU (Rectified Linear Unit):

其不会有溢出,计算更快。当x<0时,梯度为0.
缺点:出现死亡状态。
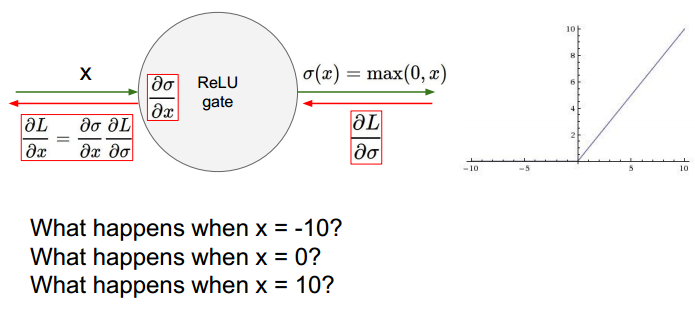

为负值输入时,不能更新参数。一般是学习率过高导致。另外使用合适的初始化,比如加入小的bias。
Leaky ReLU :解决负值不能更新参数。

ELU:

Maxout:

总结:

=========================================================================================
2、数据预处理
减均值与规则化:

减去均值,使得数据以0点为中心。规则化使得数据范围变成-1到1之间。
PCA 与 Whitening

PCA能将数据降为表示。白化降低数据的相关性。
具体的细节可以参考课程配套笔记。
效果比较:

实践经验:在图像处理中减均值用的较多,归一化也比会使用。

=========================================================================================
3、权重参数初始化
问题:

方案一:

可能导致的结果:
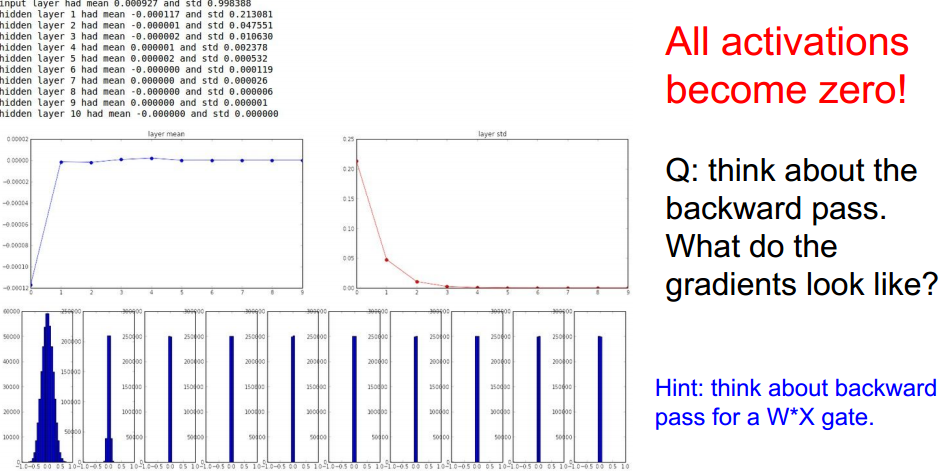
可能由于scale太小造成,使得后面隐藏层的输入变为了0。改进:

方案二:

方案三:

一些参考:具体的细节需要分析论文。

=========================================================================================
4、Batch Normalization
结构:


在全连接或者卷积层后、在非线性激活函数之前使用。
可以参考此博文进行了解。
计算细节:
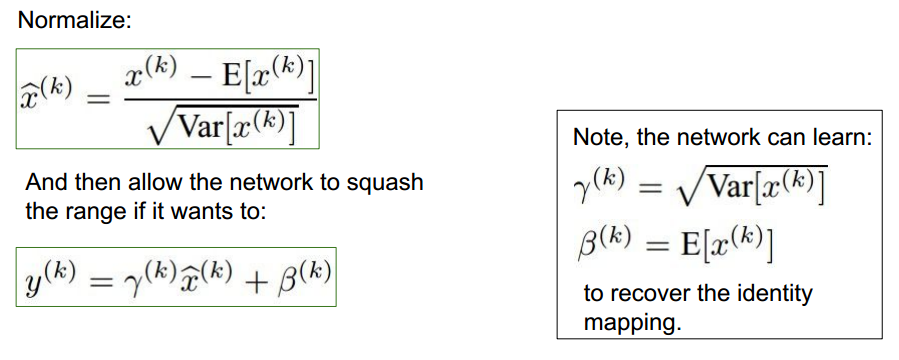

BN的优点: 可使用高的学习率更快收敛。dropout与正则化需求降低。
训练阶段与测试阶段不同的处理:

主要均值与方差的计算。测试阶段不再对数据计算均值与方差,而是使用train阶段得到的值。
=========================================================================================
5、实现流程
(1) 对数据预处理

(2) 选择合适的网络结构。

(3) 验证loss 是否合理。

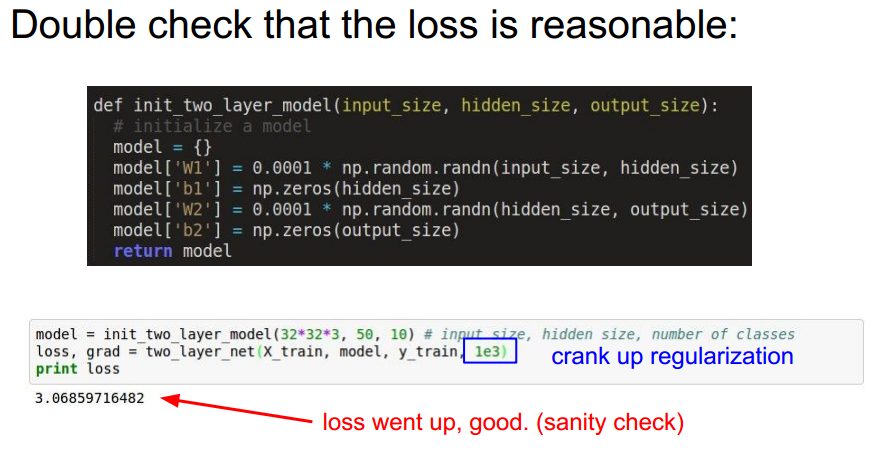
(4) 开始训练
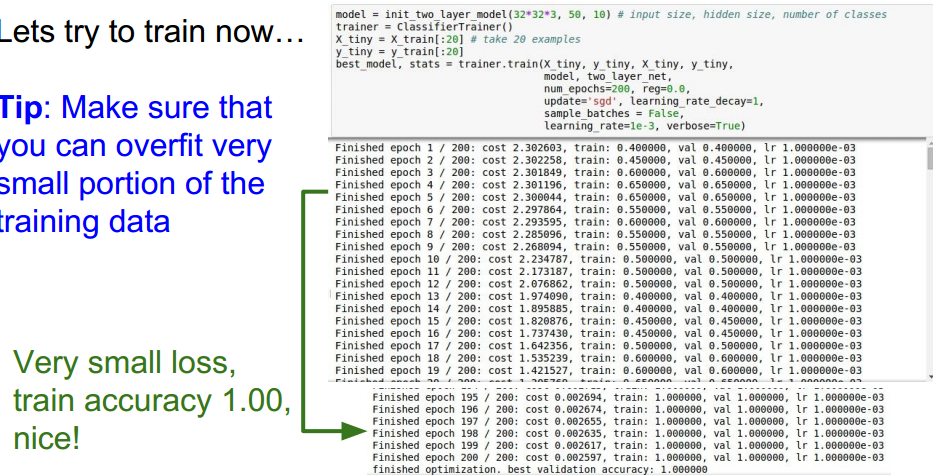
选择不同的正则强度系数和学习率,观察loss是否在下降:


不同的选择:

=========================================================================================
6、超参数选取
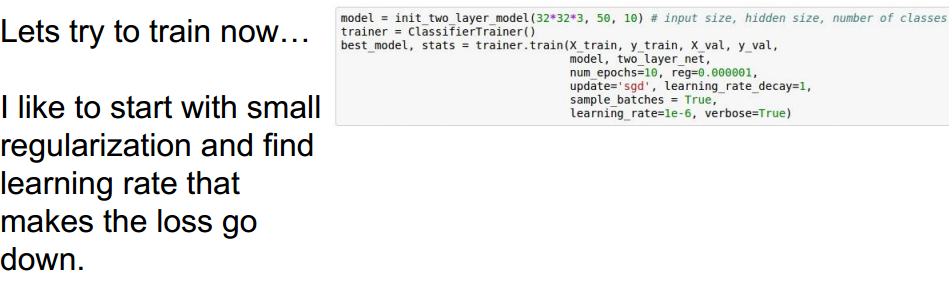
选择策略:

实例:正则化强度系数与学习率选取
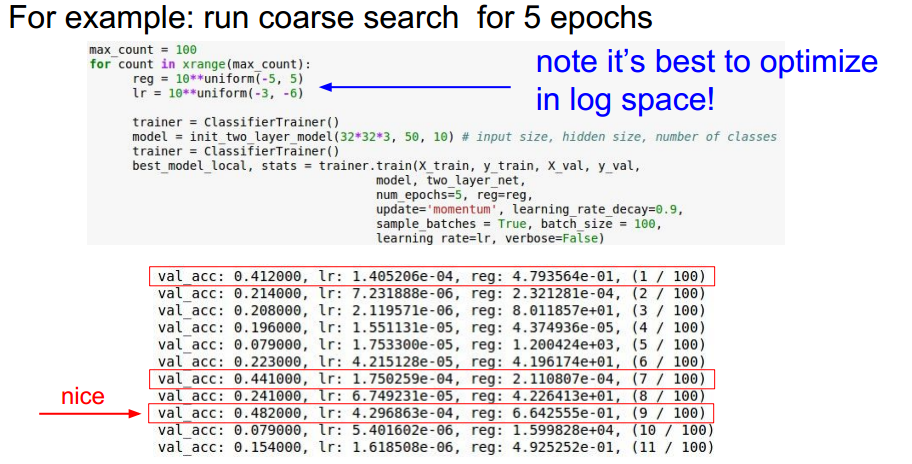
调整:

原因是学习率太高了。
选取参数的策略:


大神的经验:将不同的选取方式做总结并代码实现,方便调试不同的模型。快速有效:

一些例子:
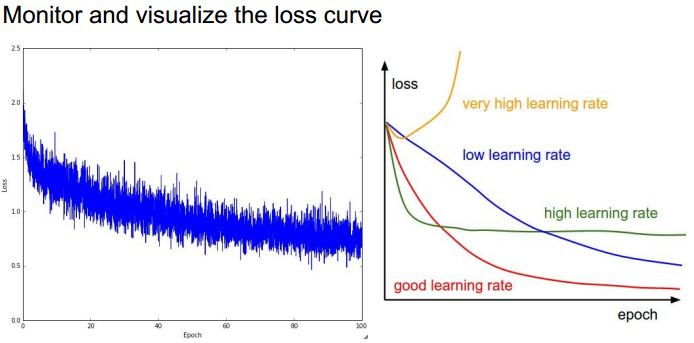
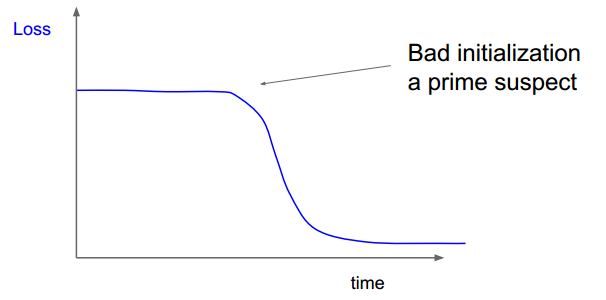
右图的初始化存在问题,在很长时间里,loss并没有下降。
一些loss 图:
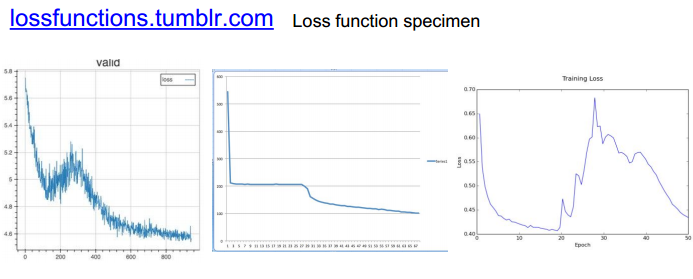
关于accuracy以及参数更新:


对更新参数进行评估。
=========================================================================================
总结:

本章是相对而言比较难,并且及其重要的一章。需要多参考对应的note对细节进行学习。
附:通关CS231n企鹅群:578975100 validation:DL-CS231n

 浙公网安备 33010602011771号
浙公网安备 33010602011771号