
Postgresql 小白学习之路之 PostgreSQL的体系结构
Postgresql 小白学习之路之 PostgreSQL的体系结构
PostgreSQL体系结构
PostgreSQL的物理结构非常简单。它是由共享内存(shared memory)和少量的后台进程以及数据文件组成。
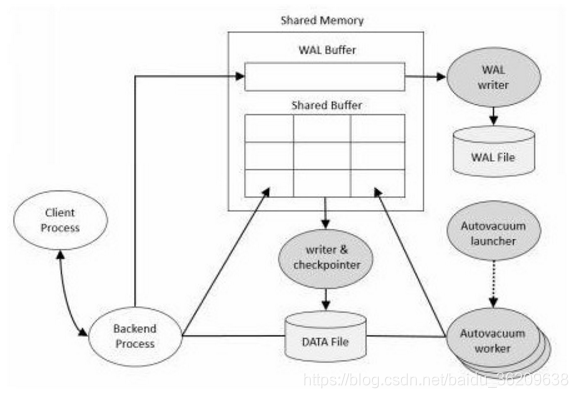
共享内存(shared memory)
共享内存是指提供数据缓存和事务日志缓存的内存。在共享内存中最重要的组成部分是shared Buffer和WAL buffer(Write-Ahead Logging)
共享内存是指提供数据缓存和事务日志缓存的内存。在共享内存中最重要的组成部分是shared Buffer和WAL buffer(Write-Ahead Logging)
shared Buffer(共享缓冲区)
共享缓冲区的主要目的是最大限度的减少磁盘IO.为达到这个目的,必须要满足如下的这些要求
需要快速访问非常大的缓冲区
当多个用户同时访问并发生争用时,应该确保最小化争用。
使用最频繁的数据块必须尽可能长时间的保存在缓冲区中。
WAL buffer(预写日志缓存)
WAL:Write-Ahead Logging 预写日志
WAL buffer 是一个临时存储数据更改的缓冲区,存储在WAL buffer 中的内容将在预定的时间点写入WAL文件。
从备份和恢复的角度,WAL buffer和WAL文件是非常重要的。
PostgreSQL 进程的类型
PostgreSQL有四种类型的进程
Postmaster(Daemon)进程
后台进程(Background Process)
后端进程(Backend Process)
客户端进程(Client Process)
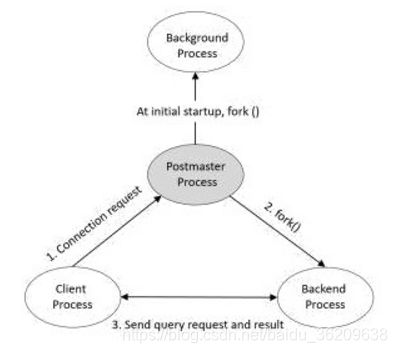
Postmaster 进程
Postgmaster进程是PostgreSQL启动的第一个进程。
负责实施恢复,初始化共享内存,并启动后台进程。
当客户端进程有链接请求时,负责创建后端进程。
如果使用pstree命令检查进程之间的关系,你会发现Postmaster是所有进程的父进程。(pstree命令并不显示进程的名称,为了解释清晰,我增加了进程的名称和参数)
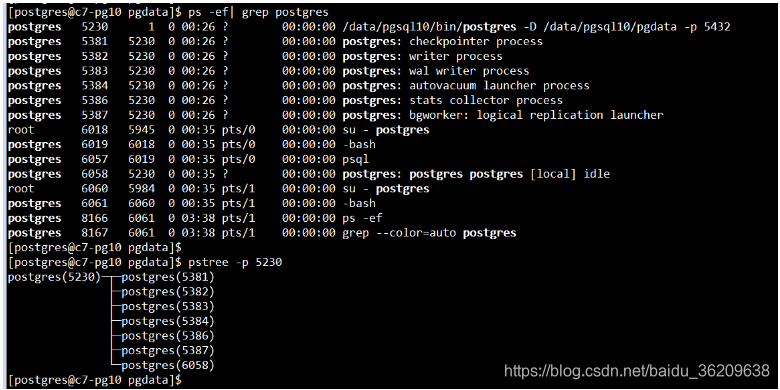
后台进程(Background Process)
PostgreSQL操作所需的后台进程列表如下。

后端进程(Backend Process)
后端进程的最大数量取决于max_connections参数的设置,默认值是100。
后端进程执行用户的查询请求,然后传输结果。
执行查询操作需要一些特定的内存结构,我们称为本地内存。
与本地内存相关的主要参数
work_mem 空间主要用来进行排序、位图操作、哈希连接、合并连接。默认值为4M。
maintenance_work_mem 空间主要用于Vacuum和创建索引。默认值为64M.
temp_buffers 空间用户临时表,默认值为8M
客户端进程(Client Process)
客户端进程是指为每个后端用户连接分配的后台进程。通常,postmaster进程将创建一个子进程,该子进程专用于服务于用户连接。
数据库结构
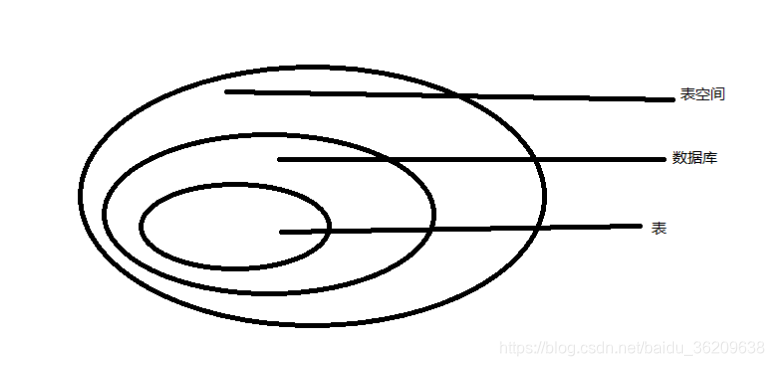
当我们尝试理解PostgreSQL的数据库结构时,有如下这些重要的事情需要了解
与数据库相关的
PostgreSQL由几个数据库组成,我们称之为数据库集群。
当initdb()被执行的时候,template0 , template1 , and postgres 数据库将被创建。
template0 , template1是用户创建数据库时的模板数据库,其中包含了系统字典表。
在执行了initdb()后,template0 , template1中的表是相同的。然而,template1数据库能够创建用户所需的数据库对象。
用户数据库是通过克隆template1数据库创建的。
与表空间相关
在执行完initdb()后,表空间pg_default和pg_global则立即被创建。
- 创建表时如果不指定表空间,则表默认存储在pg_default表空间。(确切的说是存储在该表空间的数据库下面)
- 数据库集群级别管理的表存储在pg_global表空间中。
pg_default表空间的物理位置是
P
G
D
A
T
A
/
b
a
s
e
p
g
g
l
o
b
a
l
表
空
间
的
物
理
位
置
是
PGDATA/base pg_global表空间的物理位置是
PGDATA/basepgglobal表空间的物理位置是PGDATA/global
一个表空间可以被多个数据库使用。此时,将在表空间目录中创建特定于数据库的子目录。
创建用户表空间将在$PGDATA/tblspc目录中创建到用户表空间的符号链接。

与表相关
首先创建一个测试表:
create table test(id int,name varchar(20));
注意:
- 视图pg_tables提供对数据库中每个表的信息的访问
- pg_class记录表和几乎所有具有列或者像表的东西。这包括索引(但还要参
见pg_index)、序列(但还要参见pg_sequence)、视图、物化视图、组合类型和TOAST表,
参见relkind。下面,当我们提及所有这些类型的对象时我们使用“关系”。并非所有列对
于所有关系类型都有意义。
参见官方文档 第 51 章 系统目录
系统目录是关系型数据库存放模式元数据的地方,比如表和列的信息,以及内部统计信息
等。PostgreSQL的系统目录就是普通表
mydb=# select relfilenode,oid from pg_class where relname = 'test';
-[ RECORD 1 ]------
relfilenode | 24578
oid | 24578
官方文档 9.26.7. 数据库对象管理函数

mydb=# select pg_relation_filenode('test');
-[ RECORD 1 ]--------+------
pg_relation_filenode | 24578
mydb=# select pg_relation_filepath('test'); ---->查看表的物理位置
-[ RECORD 1 ]--------+--------------------------------------------
pg_relation_filepath | pg_tblspc/24576/PG_10_201707211/24577/24578
默认创建的表的relfilenode 和 oid 是一样的
表在数据库中通过对象的id (oid) 来组织和管理
数据文件是由relfilenode来管理
为测试表创建索引
mydb=# create index idx_test_id on test(id);
CREATE INDEX
mydb=#
mydb=#
mydb=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | |
name | character varying(20) | | |
Indexes:
"idx_test_id" btree (id)
mydb=# select oid,relfilenode from pg_class where relname = 'idx_test_id';
oid | relfilenode
-------+-------------
32770 | 32770
(1 row)
— 前面提到过 pg_class记录表和几乎所有具有列或者像表的东西
索引的 relfilenode 和 oid 通常和表的 oid 一致
注意:
通常 relfilenode 和 对象的oid 一致,但是如果使用以下命令后,表和索引的
relfilenode 值会改变
TRUNCATE
REINDX
CLUSTER
--为测试表插入数据
mydb=# insert into test values(1,'PostgreSQL');
INSERT 0 1
mydb=#
mydb=# select * from test;
id | name
----+------------
1 | PostgreSQL
(1 row)
mydb=# select oid,relfilenode from pg_class where relname = 'test';
oid | relfilenode
-------+-------------
24578 | 24578
(1 row)
mydb=# truncate table test;
TRUNCATE TABLE
mydb=# select oid,relfilenode from pg_class where relname = 'test';
oid | relfilenode
-------+-------------
24578 | 32771
--relfilenode 变了
--再次插入数据
mydb=# insert into test select id,id || 'eareataetaewt' from generate_series(1,100) as id;
INSERT 0 100
--查看表的物理位置
mydb=# select pg_relation_filepath('test');
pg_relation_filepath
---------------------------------------------
pg_tblspc/24576/PG_10_201707211/24577/32771
(1 row)
--查看表的大小
mydb=# select pg_size_pretty(pg_relation_size('test'));
pg_size_pretty
----------------
16 kB
(1 row)
--插入数据,让表超过1G
mydb=# insert into test select id,id || 'eareataetaewt' from generate_series(1,1000000) as id;
INSERT 0 1000000
mydb=# insert into test select id,id || 'eareataetaewt' from generate_series(1,10000000) as id;
INSERT 0 10000000
mydb=# insert into test select id,id || 'eareataetaewt' from generate_series(1,10000000) as id;
INSERT 0 10000000
mydb=# select pg_size_pretty(pg_relation_size('test'));
pg_size_pretty
----------------
1515 MB
(1 row)
mydb=# select pg_relation_filepath('test');
pg_relation_filepath
---------------------------------------------
pg_tblspc/24576/PG_10_201707211/24577/32771
(1 row)
当表对象超过1G ,那么 表对象将会以 relfilenode 加.编号的方式生成新的文件
该编号是从1开始
可以通过 --with-segsize 来更改单个表文件的大小
表对象除了有对应的物理的数据文件之外,还有两个名为 fsm后缀结尾和vm结尾的文件
fsm:表文件每个页面上的空闲空间信息
vm: 表文件本身的可见性信息
索引本身没有vm文件,只有fsm文件
[postgres@c7-pg10 24577]$ ls -l 32771* -h
-rw------- 1 postgres postgres 1.0G Jul 1 11:50 32771
-rw------- 1 postgres postgres 492M Jul 1 11:50 32771.1
-rw------- 1 postgres postgres 400K Jul 1 11:48 32771_fsm
-rw------- 1 postgres postgres 32K Jul 1 11:44 32771_vm
表空间物理路径的布局
sdedu_tbs
[postgres@sdedu PG_10_201707211]$ pwd
/data/sdedu_tbs/PG_10_201707211
PG_10_201707211
PG_数据库主版本编号_创建的时间
数据库目录
[postgres@sdedu 16388]$ pwd
/data/sdedu_tbs/PG_10_201707211/16388
pg_tblspc
堆表文件的布局
表是由多个page组成,每一个page大小为8k
page的编号从 0 开始
pd_lsn ,该页面最近一次变更写入pg_xact中对应的lsn
pd_checksum:该页面的校验和
pd_lower:指向行指针的末尾
pd_upper: 指向最后一个插入元组的起始位置
补充:
每个表对应三个文件
一个是存储数据的文件,文件名是该表的OID
一个是管理表空闲空间的文件,文件名为OID_fsm
一个是管理表块可见性的文件。文件名是OID_vm
索引没有_vm文件。也就是说,OID和OID_fsm由两个文件组成。
其他需要记住的
创建表和索引时的文件名是OID。OID和pg_class.relfilenode是相同的。
但是,当执行重写操作(Truncate、CLUSTER、Vacuum Full、REINDEX等)时,将更改受影响对象的relfilenode值,文件名也将更改为relfilenode值。您可以使用pg_relation_filepath (’< object name >’)轻松地检查文件位置和名称。
实际操作
如果在initdb()之后查询pg_database视图,可以看到已经创建了template0、template1和postgres数据库。
postgres=# select oid,datname,datistemplate,datallowconn from pg_database order by 1;
oid | datname | datistemplate | datallowconn
-------±----------±--------------±-------------
1 | template1 | t | t
13210 | template0 | t | f
13211 | postgres | f | t
16394 | bucardo | f | t
(4 rows)
通过datistemplate列,您可以看到template0和template1数据库是用于创建用户数据库模板的数据库。
datlowconn列指示是否可以访问数据库。不能访问template0数据库,同时数据库的内容也不能更改。
为模板提供两个数据库的原因是,template0数据库是初始状态模板,template1数据库是用户添加的模板。
postgres数据库是使用template1数据库创建的默认数据库。如果在连接时没有指定数据库,则将连接到postgres数据库。
数据库位于
P
G
D
A
T
A
/
b
a
s
e
目
录
下
。
目
录
名
是
数
据
库
的
O
I
D
号
。
[
p
o
s
t
g
r
e
s
@
l
o
c
a
l
h
o
s
t
b
a
s
e
]
PGDATA/base目录下。目录名是数据库的OID号。 [postgres@localhost base]
PGDATA/base目录下。目录名是数据库的OID号。[postgres@localhostbase] ll
总用量 48
drwx------. 2 postgres postgres 8192 7月 11 14:20 1
drwx------. 2 postgres postgres 8192 6月 28 13:49 13210
drwx------. 2 postgres postgres 8192 7月 11 14:20 13211
drwx------. 2 postgres postgres 8192 7月 11 14:21 16394
创建用户数据库
用户数据库由克隆template1数据库创建。要验证这一点,请在template1数据库中创建一个用户表T1。创建mydb01数据库之后,检查T1表是否存在。
postgres=# \c template1
You are now connected to database “template1” as user “postgres”.
template1=# create table t1 (c1 integer);
CREATE TABLE
template1=# \c postgres
You are now connected to database “postgres” as user “postgres”.
postgres=# create database mydb01;
CREATE DATABASE
postgres=# \c mydb01
You are now connected to database “mydb01” as user “postgres”.
mydb01=# \d
List of relations
Schema | Name | Type | Owner
--------±-----±------±---------
public | t1 | table | postgres
pg_default 表空间
如果在initdb()之后查询pg_tablespace,可以看到已经创建了pg_default和pg_global表空间。
postgres=# select oid,* from pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions
-------±-----------±---------±-------±-----------
1663 | pg_default | 10 | |
1664 | pg_global | 10 | |
16999 | tbs_test | 10 | |
(3 rows)
pg_default表空间的位置是
P
G
D
A
T
A
b
a
s
e
。
这
个
目
录
中
有
一
个
按
数
据
库
O
I
D
划
分
的
子
目
录
[
p
o
s
t
g
r
e
s
@
l
o
c
a
l
h
o
s
t
b
a
s
e
]
PGDATAbase。这个目录中有一个按数据库OID划分的子目录 [postgres@localhost base]
PGDATAbase。这个目录中有一个按数据库OID划分的子目录[postgres@localhostbase] ls -l $PGDATA/base
总用量 60
drwx------. 2 postgres postgres 8192 7月 12 14:57 1
drwx------. 2 postgres postgres 8192 6月 28 13:49 13210
drwx------. 2 postgres postgres 8192 7月 11 14:20 13211
drwx------. 2 postgres postgres 8192 7月 11 14:21 16394
drwx------. 2 postgres postgres 8192 7月 12 14:59 17008
pg_global 表空间
pg_global表空间是用于存储要在“数据库集群”级别管理的数据的表空间。
例如,与pg_database表类型相同的表无论是否从任何数据库访问,都提供相同的信息。
pg_global表空间的位置是$PGDATAglobal。
创建用户表空间
postgres=# create tablespace myts01 location ‘/data01’;
CREATE TABLESPACE
postgres=# select oid,* from pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions
-------±-----------±---------±-------±-----------
1663 | pg_default | 10 | |
1664 | pg_global | 10 | |
16999 | tbs_test | 10 | |
17010 | myts01 | 10 | |
(4 rows)
P
G
D
A
T
A
/
p
g
t
b
l
s
p
c
目
录
中
的
符
号
链
接
指
向
表
空
间
目
录
。
[
p
o
s
t
g
r
e
s
@
l
o
c
a
l
h
o
s
t
]
PGDATA/pg_tblspc目录中的符号链接指向表空间目录。 [postgres@localhost ~]
PGDATA/pgtblspc目录中的符号链接指向表空间目录。[postgres@localhost ] ls -l
P
G
D
A
T
A
/
p
g
t
b
l
s
p
c
总
用
量
0
l
r
w
x
r
w
x
r
w
x
.
1
p
o
s
t
g
r
e
s
p
o
s
t
g
r
e
s
377
月
1213
:
3916999
−
>
/
u
s
r
/
l
o
c
a
l
/
p
g
s
q
l
/
d
a
t
a
/
t
a
b
l
e
s
p
a
c
e
d
a
t
a
l
r
w
x
r
w
x
r
w
x
.
1
p
o
s
t
g
r
e
s
p
o
s
t
g
r
e
s
77
月
1215
:
1517010
−
>
/
d
a
t
a
01
[
p
o
s
t
g
r
e
s
@
l
o
c
a
l
h
o
s
t
]
PGDATA/pg_tblspc 总用量 0 lrwxrwxrwx. 1 postgres postgres 37 7月 12 13:39 16999 -> /usr/local/pgsql/data/tablespace_data lrwxrwxrwx. 1 postgres postgres 7 7月 12 15:15 17010 -> /data01 [postgres@localhost ~]
PGDATA/pgtblspc总用量0lrwxrwxrwx.1postgrespostgres377月1213:3916999−>/usr/local/pgsql/data/tablespacedatalrwxrwxrwx.1postgrespostgres77月1215:1517010−>/data01[postgres@localhost ]
更改表空间位置
PostgreSQL在创建表空间时指定一个目录。因此,如果目录所在的文件系统已满,则不能再存储数据。要解决这个问题,可以使用卷管理器。但是,如果不能使用卷管理器,可以考虑更改表空间位置。操作顺序如下。
[postgres@localhost 13211]$ pg_ctl stop
waiting for server to shut down… done
server stopped
[root@localhost 13210]# cp -rp /data01/PG* /data02
[root@localhost pg_tblspc]# chown postgres.postgres /data02
[root@localhost pg_tblspc]# ll
总用量 0
lrwxrwxrwx. 1 postgres postgres 7 7月 12 15:15 17010 -> /data01
[root@localhost pg_tblspc]# rm 17010
[root@localhost pg_tblspc]# ln -s /data02 17010
[postgres@localhost 13211]$ pg_ctl start
Note: 表空间在使用分区表的环境中也非常有用。因为可以为每个分区表使用不同的表空间,所以可以更灵活地处理文件系统容量问题。
什么是Vacuum?
Vacuum做了如下这些事
收集表和索引统计信息
重新组织表
清理表和索引无用的数据块
由记录XID冻结,以防止XID循环
1和2通常是DBMS管理所必需的。但是3和4是必要的,因为PostgreSQL MVCC特性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号