报错get jedis resource failed.Could not get a resource from the pool redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
get jedis resource failed.Could not get a resource from the pool redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
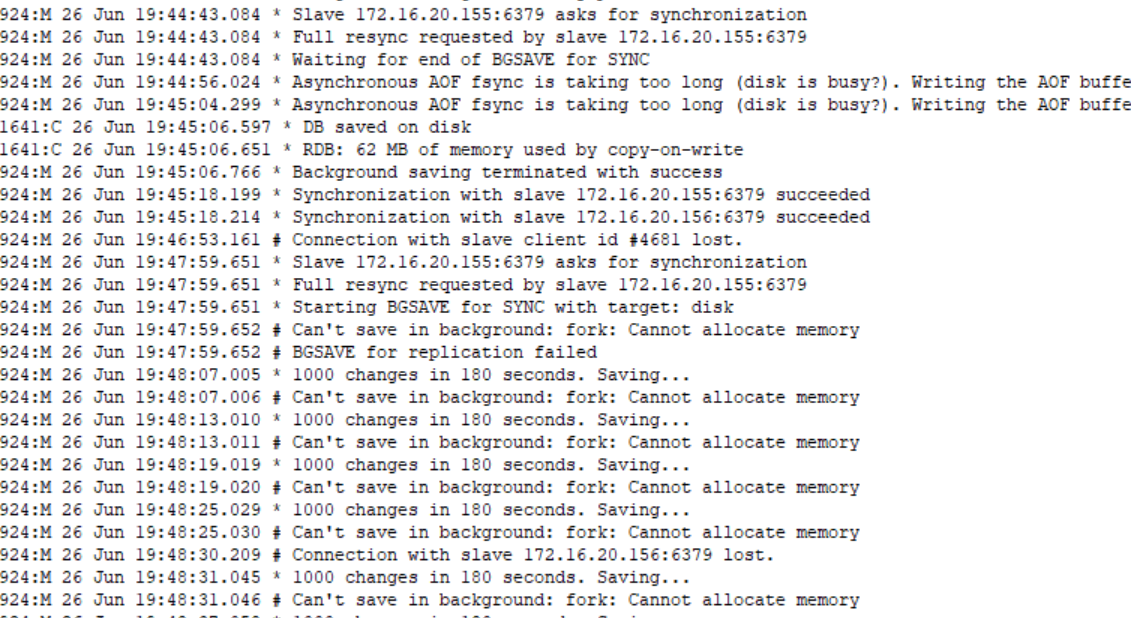
报错如上,导致系统瘫痪。
运维看了 Zabbix redis的内存分析,内存占了90%。4个多G。很明显应该有很多大Key站着redis的空间,然后再RDB的时候因为整个redis实例太大了复制的时间也很长,在复制完成之前,父进程也会被阻塞无法处理客户端请求。
Redis BGSAVE因为内存不足 fork 失败导致目标 Redis 无法访问的问题。
所以我们关键要找到哪些大key是可以删除的,然后找到了这个工具redis rdb 文件分析工具和使用 - 段佳伟 - 博客园 (cnblogs.com)
然后确认了可以删除的key,删除之后 内存一下就下来了。 也没有再出现拿不到连接的问题了。
反思:所以我们再使用redis的时候 也要考虑key的过期时间,不能一直占着内存,这样的话redis的内存大小有限 肯定会到达瓶颈。
以下来自:php bgsave,Redis-bgsave导致的接口响应延迟(深入分析Linux的fork()机制)_weixin_39850599的博客-CSDN博客
bgsave引起的接口相应延迟探索
关于fork,在redis官网有这么一段描述:
RDB disadvantages
RDB is NOT good if you need to minimize the chance of data loss in case Redis stops working (for example after a power outage). You can configure different save points where an RDB is produced (for instance after at least five minutes and 100 writes against the data set, but you can have multiple save points). However you'll usually create an RDB snapshot every five minutes or more, so in case of Redis stopping working without a correct shutdown for any reason you should be prepared to lose the latest minutes of data.
RDB needs to fork() often in order to persist on disk using a child process. Fork() can be time consuming if the dataset is big, and may result in Redis to stop serving clients for some millisecond or even for one second if the dataset is very big and the CPU performance not great. AOF also needs to fork() but you can tune how often you want to rewrite your logs without any trade-off on durability.
这里说了RDB的劣势,第二点说明了fork会造成的问题。
大意是:RDB为了将数据持久化到硬盘,需要经常fork一个子进程出来。数据集如果过大的话,fork()的执行可能会非常耗时,如果数据集非常大的话,可能会导致Redis服务器产生几毫秒甚至几秒钟的拒绝服务(),并且CPU的性能会急剧下降。
这个停顿的时间长短取决于redis所在的系统,对于真实硬件、VMWare虚拟机或者KVM虚拟机来说,Redis进程每占用1个GB的内存,fork子进程的时间就增加10-20ms,对于Xen虚拟机来说,Redis进程每占用1个GB的内存,fork子进程的时间需要增加200-300ms。
以下来自:https://blog.csdn.net/qq_39221436/article/details/125495754
RDB分析:
触发 RDB 文件创建的命令有两条,save 和 bgsave。
save 我们知道会阻塞整个实例,通常也不太可能会用。
bgsave 命令是在后台生成 RDB 文件,Redis 仍然可以处理客户端请求。
但是并不能保证 bgsave 不会影响 Redis 所有的客户端请求,在生成 RDB的过程中,Redis 会 fork 出一个子进程,子进程和父进程会共享内存地址空间,可以保证子进程拥有父进程相同的内存数据。但是在 fork 子进程时,操作系统需要将父进程的内存页表复制给子进程。如果整个 Redis 实例占用的内存很大,那么它的内存页表也会很大,复制的时间也会比较长。
同时,这个过程会消耗大量的 CPU 资源,在复制完成之前,父进程也会被阻塞,无法处理客户端请求。
执行 fork 后,子进程可以扫描 Redis 中所有数据,然后将所有数据写入 RDB 文件。
之后,父进程仍然处理客户端的请求。父进程在处理写命令时,会重新分配新的内存地址空间,向操作系统申请新的内存使用,不再与子进程共享。这样,父子进程的内存会逐渐分离,父进程会申请新的内存空间并改变内存数据,子进程的内存数据不会受到影响。
可以看出,在生成RDB文件时,不仅消耗CPU资源,还需要消耗更多的内存空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号