



clickhouse
1.ClickHouse-23.2.1.2537 单机安装部署文档(RPM版安装)
下载rpm文件
下载地址:https://packages.clickhouse.com/rpm/stable/
2、上传rmp文件到Linux中
我的目录是 /usr/local/share/jars/clickhouse其中clickhouse-install是自己创建的

3.开始安装
1、进入目录:
cd /usr/local/soft/clickhouse-install
2、使用rpm命令安装
sudo rpm -ivh *.rpm
注意:安装过程需要输入密码,密码不要复杂,123456即可
3、启动服务
systemctl start clickhouse-server
4、状态查看
systemctl status clickhouse-server
5、停止服务
systemctl stop clickhouse-server
6、重启服务
systemctl restart clickhouse-server
4、远程工具连接
1、打开clickhouse配置文件
vim /etc/clickhouse-server/config.xml
2、搜索并放开下面配置的注释
<listen_host>0.0.0.0</listen_host>
3、保存即可
:wq!
:
4、重启
systemctl restart clickhouse-server
clickhouse-client --host localhost --port 9001 进入click house命令行
ClickHouse 是一个用于联机分析(OLAP)的列式数据库管理系统。
特点:
1、绝大多数是读请求
2. 列式存储 只需要读取查询涉及的列,减少了数据的读取量,提高查询性能
3.高性能
快速处理大规模数据:能够在秒级甚至毫秒级内响应查询,处理数十亿行甚至更多的数据量。
高效的压缩算法:可以极大地减少数据存储占用的空间,同时提高数据读取的速度。
2、数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
3、已添加到数据库的数据不能修改。
4、对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
5、宽表,即每个表包含着大量的列
6、查询相对较少(通常每台服务器每秒查询数百次或更少)
7、对于简单查询,允许延迟大约50毫秒
8、列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
9、处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
10、事务不是必须的
11、对数据一致性要求低
12、每个查询有一个大表。除了他以外,其他的都很小。
13、查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
数据类型
注意事项:
1、建表写数据类型的时候,严格区分大小写Int32,不能写成int32
2、建表的时候,必须要指定表引擎(详细引擎的使用,后面介绍)
a.整数类型
UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256
Int8 — [-128 : 127]
Int16 — [-32768 : 32767]
Int32 — [-2147483648 : 2147483647]
Int64 — [-9223372036854775808 : 9223372036854775807]
Int128 — [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]
Int256 — [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]
UInt8 — [0 : 255]
UInt16 — [0 : 65535]
UInt32 — [0 : 4294967295]
UInt64 — [0 : 18446744073709551615]
UInt128 — [0 : 340282366920938463463374607431768211455]
UInt256 — [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
b.字符类型
String:可变长字符串 varchar
FixedString(长度):固定长字符串,参数是字节数,执行效率比String要高 char 例如age FixedSteing(8)
###c.日期类型
Date 年-月-日
Date32 年-月-日
DateTime 年-月-日 时-分-秒
DateTime64 年-月-日 时-分-秒.毫秒
案例:
# 建表语句:
create table date_test (date1 Date,date2 Date32,date3 DateTime,date4 DateTime64) ENGINE = TinyLog;
# 插入语句:
insert into date_test values ('2023-11-21','2023-11-21','2023-11-21','2023-11-21');
insert into date_test values (1691825618123,1691825618123,1691825618123,1691825618123); //2023-08-12 15:33:38
d. UUID类型
clickhouse提供了一个函数:generateUUIDv4() 生成一个 00000000-0000-0000-0000-000000000000 的编号 编号的类型就是UUID类型
e. 可为空 Nullable
例如建表的时候,有一个id字段类型时Int32,如果当id不确定的时候,我们应该使用null进行填充,而不应该用默认值0,所以,我们这里应该添加的是null
Nullable(Int32)
insert into students_test values (null,'张玮2','男','特训营24期');
f. 数组 Array(T)
字段类型是数组,对于同一个数组,在建表的时候指定数据类型,注意:在MergeTree表引擎中是不允许出现数组嵌套的
注意:需要使用array()函数,将元素组成数组,将来还可以使用toTypeName()查看某一列的数据类型
# 举例:
create table t1 (col1 Array(Int8)) ENGINE = TinyLog;
insert into t1 values array(11,12,13);
g. 小数类型
Decimal(P,S),Decimal32(S),Decimal64(S),Decimal128(S)
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)
P - 精度。有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。
S - 规模。有效范围:[0:P],决定数字的小数部分中包含的小数位数。
Decimal(4,2)
举例:12.12234
P: 7
S: 5
数据库引擎
1.1 Atomic
clickhouse数据库建库默认指定的数据库引擎
mysql引擎
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行`INSERT`和`SELECT`查询,以方便您在ClickHouse与MySQL之间进行数据交换
`MySQL`数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此您可以执行诸如`SHOW TABLES`或`SHOW CREATE TABLE`之类的操作。
但您无法对其执行以下操作:
- `RENAME`
- `CREATE TABLE`
- `ALTER`
# 在clickhouse中创建数据库并指定远程的MySQL服务,将其中的某一个数据库映射过来(就将这新建的数据库看成一个远程客户端连接了mysql)
# 建库语句
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
# 举例
create database IF NOT EXISTS bigdata24_mysql ENGINE = MySQL('192.168.169.100:3306','bigdata24','root','123456');
# 参数理解:
host:port — MySQL服务地址,既可以是ip地址,也可以是主机名(如果是主机名,要配置hosts映射)
database — MySQL数据库名称
user — MySQL用户名
password — MySQL用户密码
表引擎
##### a. Log
> `Log` 与 `TinyLog` 的不同之处在于,«标记» 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。`Log`引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。`Log`引擎适用于临时数据,write-once 表以及测试或演示目的。
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
并发数据访问不受任何限制:
- 如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则您可能会发现切换使用 TinyLog 类型的表更容易。**不支持索引**。
合并树家族
MergeTree
> Clickhouse 中最强大的表引擎当属 `MergeTree` (合并树)引擎及该系列(`*MergeTree`)中的其他引擎。
`MergeTree` 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
- 存储的数据按主键排序。
这使得您能够创建一个小型的稀疏索引来加快数据检索。
- 如果指定了 [分区键](https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/custom-partitioning-key) 的话,可以使用分区。
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本。
`ReplicatedMergeTree` 系列的表提供了数据副本功能。更多信息,请参阅 [数据副本](https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replication) 一节。
- 支持数据采样。
需要的话,您可以给表设置一个采样方法。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
# 案例
# 建表语句
create table goods_orders (id String,uname String,goods_name String,price Int64,date Date32) ENGINE = MergeTree() order by date PARTITION BY date;
insert into company.goods_orders values ('1001','李刚','oppo手机',7000,'2024-10-24'),('1002','江川','机械革命电脑',10000,'2023-10-22'),
('1003','钱志强','iphone14',5000,'2024-10-24'),('1004','吴问强','AI吸尘器',17000,'2024-10-22')
('1005','王骏','iphone15',8000,'2024-7-1');
注意:默认是针对每一批数据按照分区字段的值进行分区
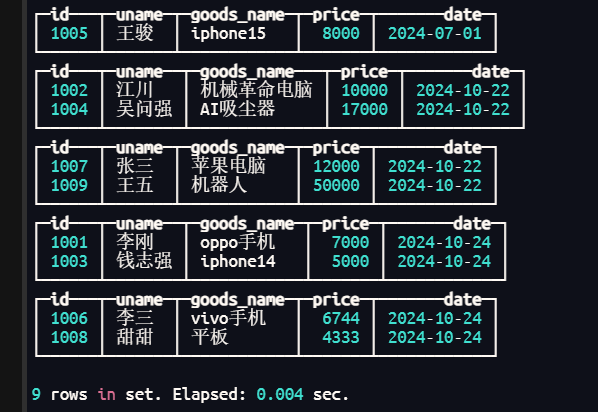
根据上图所示,并不会立刻的将所有的相同的分区进行合并,如果想要很快的看到结果,可以手动的进行合并
optimize table 表名 final;
optimize table goods_orders final;

今后开发的时候,常用的表引擎:针对数据量小的表引擎用TinyLog, 数据量大表引擎就用MergeTree
开窗
-- 开窗 over()
-- select xxx(...) over(...)
-- 开窗不会改变数据条数,新增一列开窗的列
建表导入数据
点击查看代码
CREATE TABLE bigdata32.employees (
emp_no UInt16,
emp_name String,
job String,
mgr_no UInt16,
hire_date Date,
salary Decimal(10, 2),
commission Decimal(10, 2),
dept_no UInt8
) ENGINE = MergeTree()
ORDER BY emp_no;
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800.00, NULL, 20);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600.00, 300.00, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250.00, 500.00, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975.00, NULL, 20);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250.00, 1400.00, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850.00, NULL, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450.00, NULL, 10);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000.00, NULL, 20);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000.00, NULL, 10);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500.00, 0.00, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100.00, NULL, 20);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950.00, NULL, 30);
INSERT INTO bigdata32.employees (emp_no, emp_name, job, mgr_no, hire_date, salary, commission, dept_no) VALUES (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000.00, NULL, 20);
select
t1.emp_name,
t1.job,
t1.mgr_no,
t1.hire_date,
t1.salary,
t1.commission,
t1.dept_no,
t1.rn
from
(
select emp_no,
emp_name,
job,
mgr_no,
hire_date,
salary,
commission,
dept_no,
row_number() over (partition by dept_no order by salary desc) as rn --相同部门分区在一起,根据薪资逆序,然后进行排序123
from bigdata32.employees
) t1 where t1.rn<3; -- 根据上述表在继续查找前三名即rn<3
由内而外
select emp_no,
emp_name,
job,
mgr_no,
hire_date,
salary,
commission,
dept_no,
row_number() over (partition by dept_no order by salary desc) as rn, --12345
rank() over (partition by dept_no order by salary desc) as rn2, --11345
dense_rank() over (partition by dept_no order by salary desc) as rn3 --11234
from bigdata32.employees;

