统计符合条件的去重过的数量 - - count distinct if case
现有表结构:
CREATE TABLE `example_dataset` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `tel` bigint(11) DEFAULT NULL, `gender` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
插入数据
INSERT INTO `example_dataset` (`id`, `tel`, `gender`) VALUES (2, 7136609221, 'male'), --'male'是男,'female'是女
(3, 7136609222, 'male'), (6, 7136609222, 'male'), (4, 7136609223, 'female'), (7, 7136609223, 'female'), (5, 7136609228, 'male');
现在sql记录里面有重复的。我想统计表中有多少人,多少男的,多少女的。
SELECT COUNT(DISTINCT tel, gender) as gender_count,
COUNT(DISTINCT tel, gender = 'male') as man_count,
SUM(if(gender = 'female', 1, 0)) as woman_count
FROM example_dataset;

显然结果是不对的。
SELECT COUNT(*) gender_count, SUM(IF(gender='male',1,0)) male_count, SUM(IF(gender='female',1,0)) female_count FROM ( SELECT DISTINCT tel, gender FROM example_dataset ) t
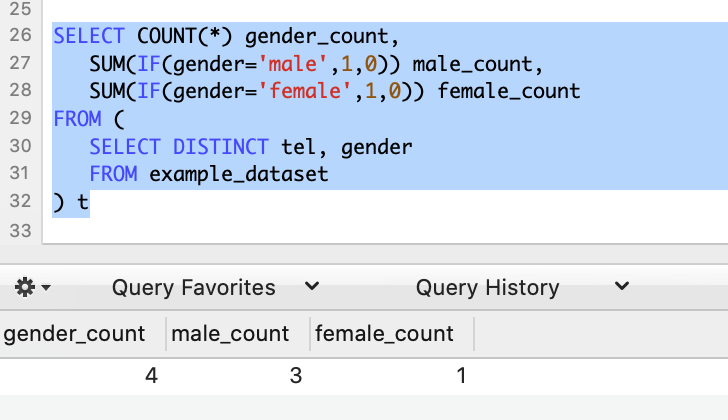
这样结果是对的。但是我想如果example_dataset表的数据量比较大,子查询会影响效率。
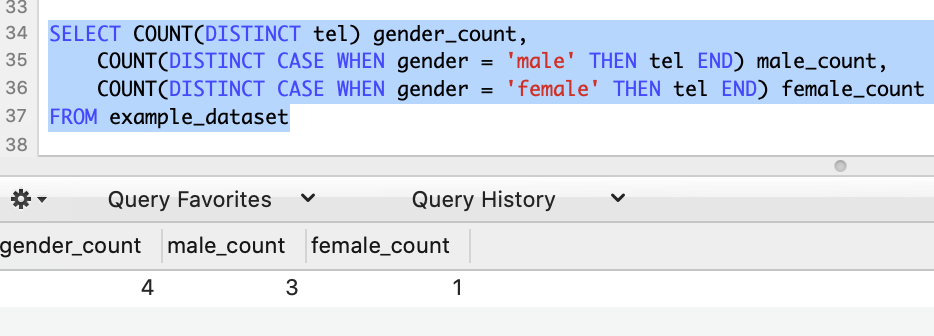
最终答案:
SELECT COUNT(DISTINCT tel) gender_count,
COUNT(DISTINCT CASE WHEN gender = 'male' THEN tel END) male_count,
COUNT(DISTINCT CASE WHEN gender = 'female' THEN tel END) female_count
FROM example_dataset
参考文章:https://stackoverflow.com/questions/19672001/mysql-distinct-count-if-conditions-unique
心稳了,手也就稳了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号