
论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts
Concept Mask: Large-Scale Segmentation from Semantic Concepts
2018-08-21 11:16:07
Paper:https://arxiv.org/pdf/1808.06032.pdf
本文做了这么一件事:给定一张图片以及概念名词,输出其对应的分割结果,如下图所示:
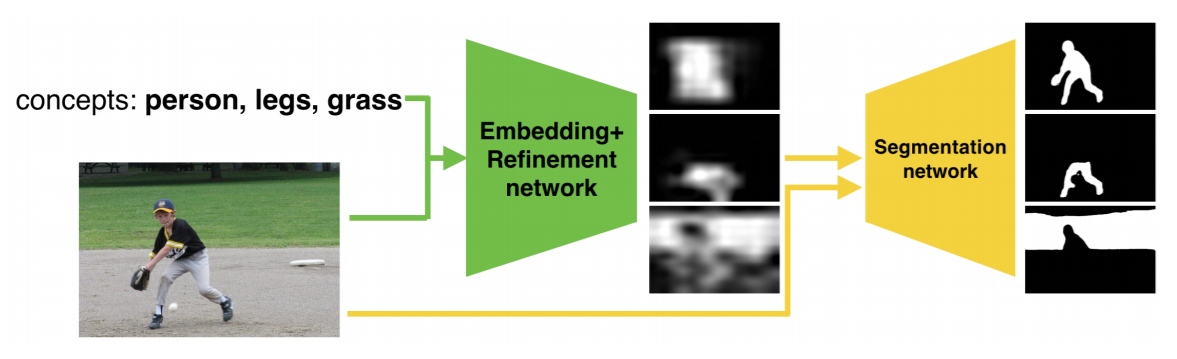
具体来说,这个流程大致可以分为如下几个部分:
1. Embedding Network 来学习视觉特征和语义概念之间的对应关系;此时,我们可以得到一个粗糙的 attention map;
2. 优化模块,在上一步骤的基础上,利用 BBox 的标注信息,得到高质量的 attention maps;
3. A label agnostic segmentation network,在 COCO-80 分割数据集上进行有监督的训练。这个网络将上述得到的 coarse attention maps,以及原图作为输入,得到最终概念级别的分割结果;
总体的流程图如下:
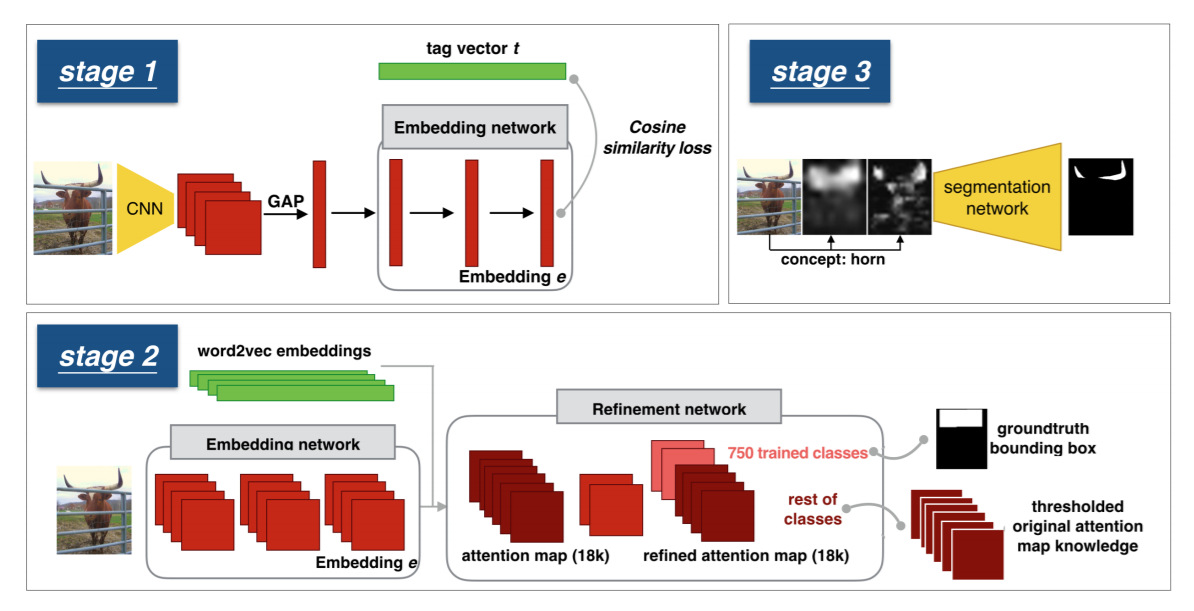
下面分别详细的介绍下对应的每一个模块:
1. Embedding Network:
作者在 Stock-18K dataset 上进行了训练,该数据集包含 6 million images,每一个图像都对应有标注的 tags,有 18K vocabulary。
Word Embedding
有了 tag 的信息,第一步就是将其映射为 vector,与通常直接用 pre-trained Word embedding 的方法不同,本文采用的是:point-wise mutual information (PMI) 来学习我们自己的 Word embedding。当一张图像有多个对应的 label 时,作者采用了常规的 加权平均的方法,得到一个统一的表达,称为:“soft topic embedding”。
Joint Word-Image Embedding
作者用余弦相似性 loss 函数来衡量,visual embedding 与 soft topic word vector 之间的距离:
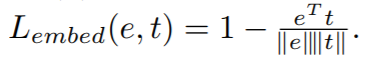
Attention Map
作者用一个全卷机的网络结构,将输入的图像,转换为对应的 attention map;然后计算每一个位置上,图像和单词描述之间的相似度:
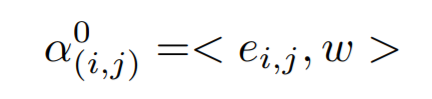
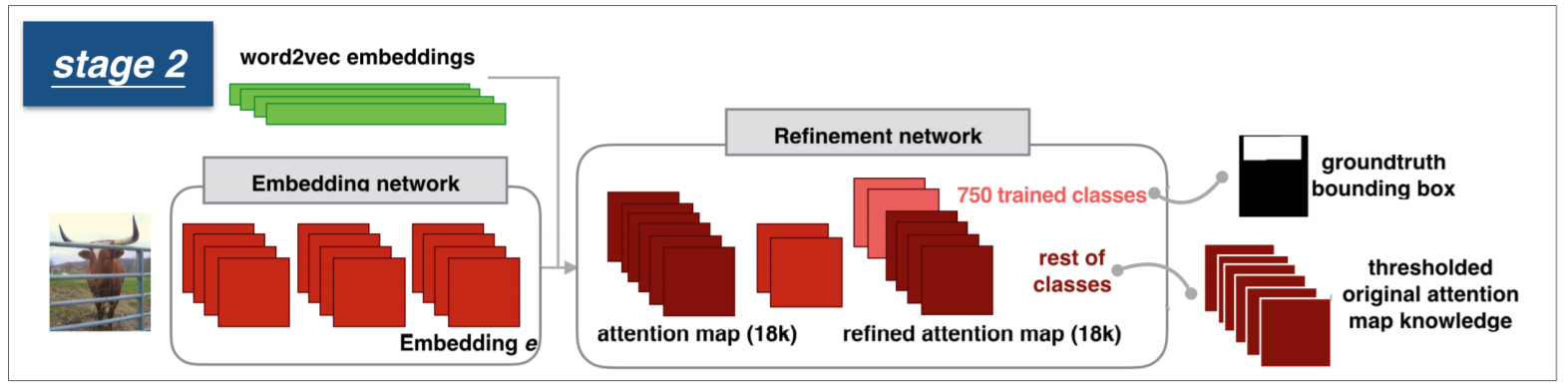
2. Attention Map Refinement
虽然上述过程得到了初始的 attention maps,但是由于缺乏 空间信息的标注,使得该 attention map 非常的粗糙;
Multi-task Training
作者采用了 二元交叉熵损失函数来度量所输出的 maps 和 GT maps 之间的差距:

Spatial Discrimination Loss
作者给出了不采用 softmax loss,而用 binary cross entropy loss 的原因:there are many concepts whose masks are overlapping with each other. 但是,仍然有一些概念,几乎从来不会重合。为了充分利用这种关系,作者提出了一种辅助的 loss 函数,来判断这些空间上不重合的概念,即:spatial discriminatives loss。
特别的,我们统计训练数据中,相互重叠的概念对:
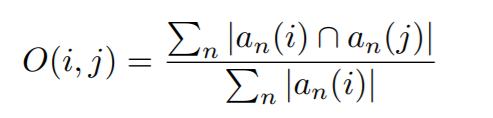
有了这个重叠比例矩阵 O(i, j),那么,我们可以用一个概念 i 的训练样本当做 非重合概念 j 的 negative training example,即:
for a particular location in the image, the output for concept j should be 0 if the ground-truth for concept i is 1.
为了软化这个约束,作者进一步根据重合度,进行了辅助 loss 的加权,权重的计算方法如下:
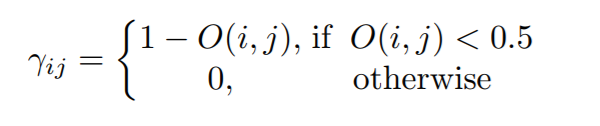
3. Label Agnostic Segmentation Network
为了得到更加精细化的分割结果,像素级的标注信息是必不可少的。所以,这里,作者将上述过程中得到的 coarse maps 以及 原始图像都作为分割网络的输入,然后得到最终精细化的分割结果。
Experiments:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号