Proximal Policy Optimization Algorithm (PPO)
Proximal Policy Optimization Algorithms
Updated on 2019-09-14 16:15:59
Paper: https://arxiv.org/pdf/1707.06347.pdf
TensorFlow Code from OpenAI: https://github.com/openai/baselines
PyTorch Code: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail/blob/master/a2c_ppo_acktr/algo/ppo.py
RL-Adventure-2 Policy Gradients (PyTorch version): https://github.com/higgsfield/RL-Adventure-2
Reference: https://blog.openai.com/openai-baselines-ppo/
Video Tutorials:
1. https://www.youtube.com/watch?v=OAKAZ hFmYoI&t=1s
2. Policy Gradient methods and Proximal Policy Optimization (PPO): diving into Deep RL!
3. CS885 Lecture 15b: Proximal Policy Optimization (Presenter: Ruifan Yu)
4. https://www.youtube.com/watch?v=UvdWDcbAY7M (中文版)
Related Blogs:
1. An Intuitive Explanation of Policy Gradient [Link]
2. RL — Proximal Policy Optimization (PPO) Explained [Link]
3. The Pursuit of (Robotic) Happiness: How TRPO and PPO Stabilize Policy Gradient Methods [Link]
4. Proximal Policy Optimization Tutorial (Part 2/2: GAE and PPO loss) [Link]
Proximal Policy Optimization Algorithms (原文解析) :
Abstract:
首先要说的是本文提出一种新的 Policy Gradient 的方法,可以在如下两个步骤之间来回迭代进行学习:
1. sampling data through interaction with the environment ; 通过与环境进行交互,进行采样;
2. optimizing a "surrogate" objective function using stochastic gradient ascent. 利用梯度上升的方法进行代替的目标函数(surrgogate objective function)的优化。
传统的 Policy Gradient Method 仅仅能够利用采样得到的 samples 进行一次更新,就要将这些samples扔掉,重新采样,再实现更新。而本文所提出的方法可以进行 multiple epochs of minibatch updates.
Introduction :
最近深度学习的方法和强化学习的组合,得到了很多新的成果,如:Deep Q-leanring, "Vanilla" policy gradient method, trust region/natural poliicy gradient methods. 但是这些方法其实都是有其各自不足的地方,如:
Deep Q-learning 在很多简单的任务上却失败了,并且 poorly understood, vanilla policy gradient methods 数据的效率和鲁棒性很差;TRPO(trust region policy optimization)是一个相对较为复杂,并且不能与其他框架兼容的(not compatiable with architecture that including noise (such as dropout) or parameter sharing (between the policy and value function, or with auxiliary tasks)). 这篇文章旨在通过引入算法获得 data efficiency,and reliable performance of TRPO,来改善当前算法的情况,与此同时,仅仅采用 first-order optimization. 我们提出 a novel objective with clipped probability ratios,为了优化策略,我们用该 policy 进行采样,然后在采样的数据上进行几个 epoch 的更新。作者的实验证明,本文的方法在几个数据集上都取得了不错的效果。
2. Background:Policy Optimization
2.1 Policy Gradient Methods:
策略梯度方法通常会计算 policy gradient 的估计,然后将其结合到随机梯度上升算法中。最常用的梯度估计(gradient estimator)如下所示:

其中,$\pi_{theta}$ 是随机策略,$\hat{A}_t$ 是时刻 t 的 优势函数的估计(an estimator of the advantage function at time step t)。该期望 E 表示:有限样本的经验平均(the empirical average over a finite batch of samples)。实际实现时,可以用自动微分的软件来构建一个目标函数,其梯度是 policy gradient estimator;而该梯度估计可以通过微分下面的目标来得到:
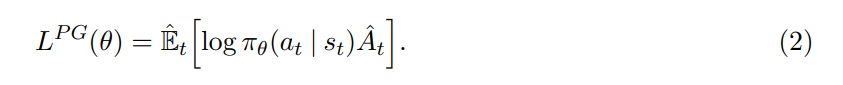
同同样的轨迹来执行多个步骤的优化,但是并不好调节。
2.2 Trust Region Methods:
在 TRPO 中,其作者换了个目标函数,如下所示:
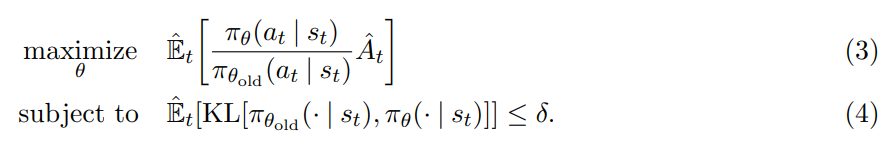
可以看出跟公式 2 的主要区在在于:添加了一个约束项,即:the constraint on the size of the policy update,要求前后两个策略之间的 KL散度小于某一阈值。此处,$\theta_{old}$ 是更新以前的策略参数的向量(the vector of policy parameters before the update)。该问题在对目标预测一个线性估计,以及对约束进行二次估计之后,就可以有效地通过共轭梯度算法来求解。
该理论说明了 TRPO 实际上表明用的是一个惩罚项,而不是约束项,即:求解非受限优化问题:

这服从了如下的事实:a certain surrogate objective forms a lower bound on the performance of the policy $\pi$。TRPO 采用了一个 hard constraint,而非是 a penty, 因为在不同的问题上选择合适的 $\beta$ 值是非常困难的,甚至在单个问题上,不同的特征也会随着学习而变化。所以,仅仅简单地设置一个固定的参数来用 SGD 优化公式 5,是不够的。
3. Clipped Surrogate Objective.
这里我们用 $r_t (\theta)$ 表示概率比:![]() TRPO 最大化如下的目标:
TRPO 最大化如下的目标:
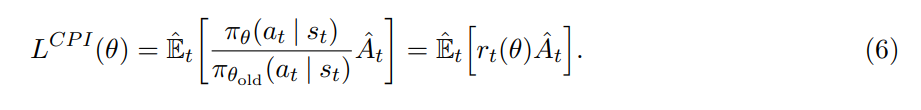
其中,上标 CPI 表示 conservative policy iteration (CPI)。在没有了约束项之后,最大化该目标将会得到一个过大的策略更新。所以,作者这里考虑如何修改该目标,去惩罚使得 $r_t (\theta)$ 远离 1 的策略更新。因为如果远离 1 了,那么说明,更新前后的策略,差异较大,而作者并不想大幅度的更新策略。
本文所提出的目标函数如下:
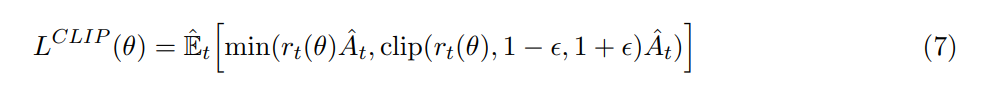
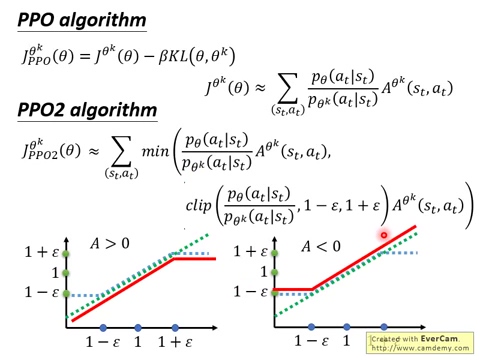
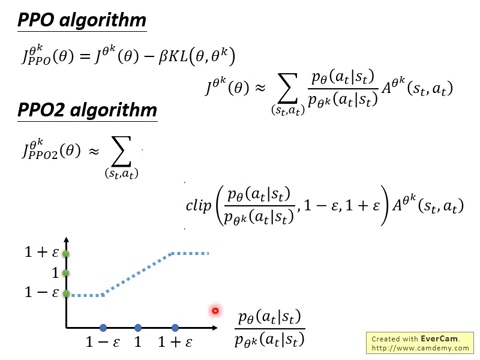
其中,$\epsilon$ 是一个超参数,设置为 0.2。该目标函数的第一项就是 $L^{CPI}$,而第二项是对 surrogate objective 进行修改,裁剪了概率比例(Clipping the probability ratio),可以防止 $r_t$ 超出设置的范围 [1-$epsilon$, 1+$\epsilon$]。最终,我们选择 clipped 和 unclipped objective 中较小的那个,所以最终的目标函数是一个 lower bound。有了这种机制,只有当对概率比例的改变可能会改善该目标函数时,我们才会忽略该改变,不对其进行调整。当调整后会变差时,我们就会将其包含进来,进行修正。作者绘制了一个示意图来说明该问题,如图 1 所示:
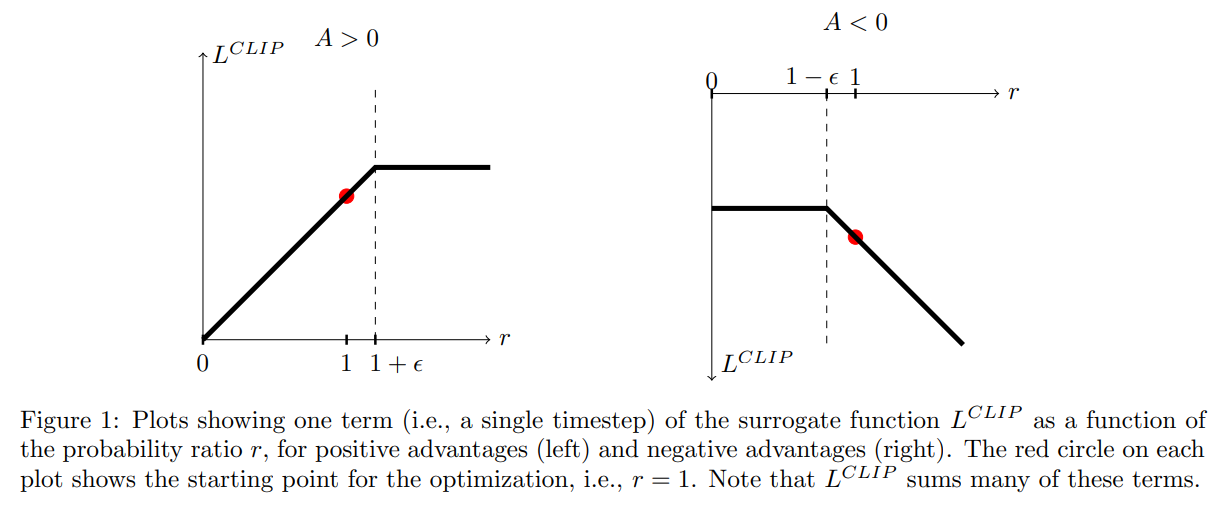
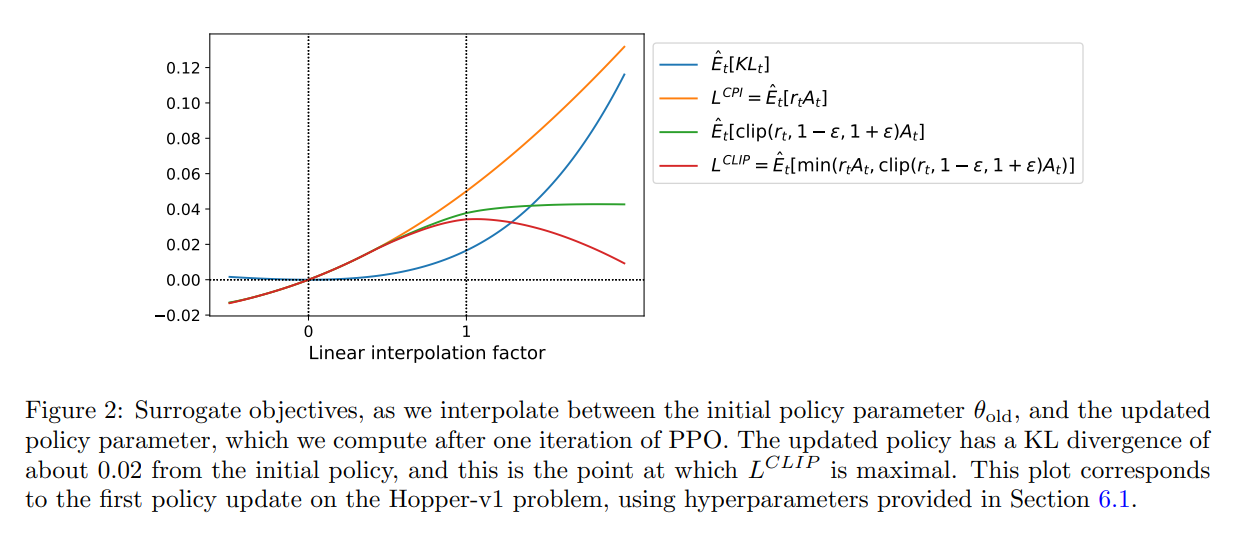
图 2 提供了另一种关于 surrogate objective $L^{CLIP}$ 直观的说明。It shows how several objective vary as we interpolate along the policy update direction,obtained by proximal policy optimization on a continuous control problem。我们可以发现,$L^{CLIP}$ 是 $L^{CPI}$ 的一个下界(lower bound),惩罚过大的策略更新。
4. Adaptive KL Penalty Coefficient:
另一个方法来改善 TRPO就是自使用的调节参数 $\beta$:use a penalty on KL divergence to adapt the penalty coefficient。作者的实验发现,这种自动调节参数的实验效果不如本文所设计的新目标函数。但是作者这里还是将其写出来,作为对比的baseline。

5. Algorithm:
在用神经网络共享 policy 和 value function 的参数时,我们必须使用包含 policy surrogate 和 value function error term 的损失函数。该目标函数可以进一步的用 entropy bonus 进行增强,因为这可以促进探索。将这些项进行组合,即可得到本文的目标:
![]()
其中,c1 和 c2 是参数,S 代表了 entropy bonus,$L_t^{VF}$ 是 squared-error loss ![]()


==== 算法部分完结














 浙公网安备 33010602011771号
浙公网安备 33010602011771号