论文笔记:Variational Capsules for Image Analysis and Synthesis
Variational Capsules for Image Analysis and Synthesis
2018-07-16 16:54:36
Paper: https://arxiv.org/pdf/1807.04099.pdf
随着深度学习的崛起,已经有很多不同的应用领域都取得了巨大的成功,其中就包括:image analysis 以及 synthesis。
Image analysis 通常是指:用一个判别性模型从图像中去抽取信息;
Image synthesis 是指:用产生式模型根据一个给定的分布,来产生图像样本。
这两个任务是高度相关的,并且希望能够互相补充和促进。不同的方法被用来分析这两个模块, analysis blocks (即:分类器),synthesis blocks (即:自回归模型,GAN, VAEs) 等。在这些方法中,analysis blocks 被用来产生可控制的条件来给 synthesis block,或者提供给生成的图像一些约束条件。但是,大部分的条件下,synthesis 和 analysis blocks 都不是联合进行训练的,所以对于同时解决这两个问题的思路来说,得到的可能不是最优解。所以,构建一个联合的框架来处理这两个任务,仍然是一个没有被解决的问题,使得这两个任务可以相互补充和协助。
为了克服上述困难,我们提出一种新的方法,即:变分胶囊网络(Variational Capsule Network (VSs)),在一个联合的判别和产生式的框架下,进行图像的建模。我们知道 capsule 最开始的时候,是由大佬 hinton 提出的,并且将其建模为:一组神经元的集合(groups of neurons whose activity vector represent vairous properties of particular entity)。所提出的 variational capsules 是一种新型的 capsule,which use the divergence of each capsule with a prior distribution rather than the length of the activity vector to represent the probability that an entity exsits. 划重点!!!这里意思是:本文所提出的新的 capsule 是用 先验分布的 KL-散度来衡量对应的示例是否存在,而不是依赖于激活向量的长度。变分胶囊将一张图像建模为多个示例的混合,将已有的示例映射到 posterior,使得其能够与 prior 恰当的进行匹配。
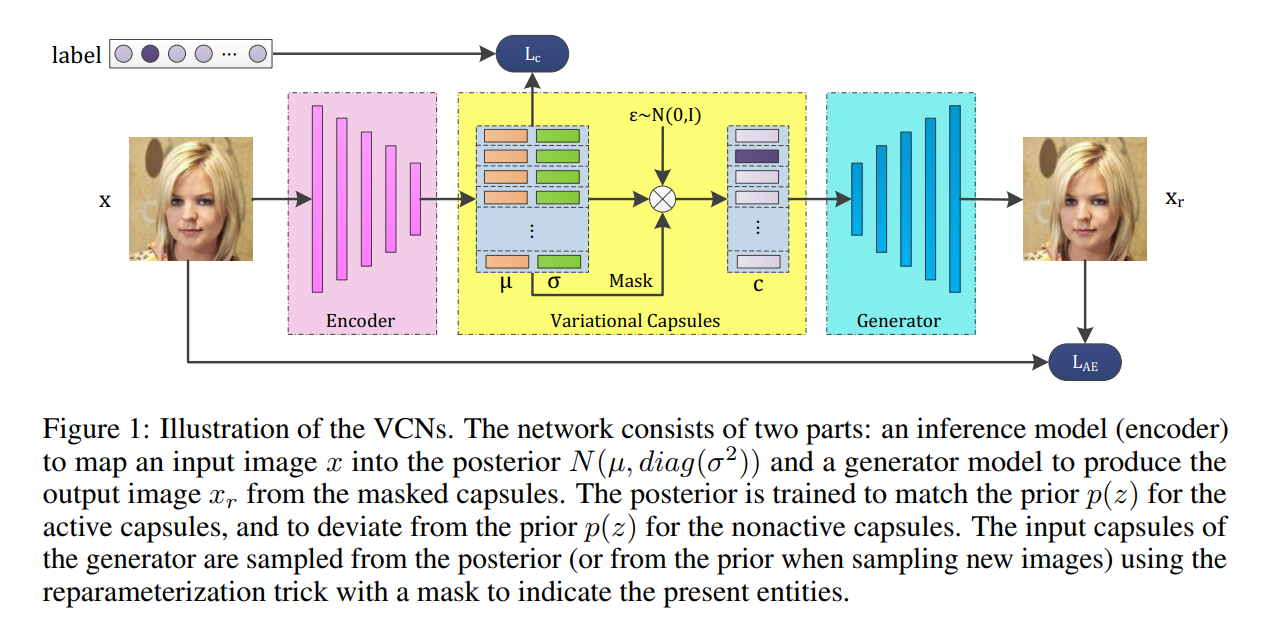
如图1所示:我们的框架服从 VAE 一样的结构,是有两个部分构成的:
an encoder: mapping the input images into variatinoal capsules;
a generator (or decoder): generating images from masked varaitional capsules.
在训练阶段,the encoder 目标是检测或者分类现有的 entity,然后使得激活的胶囊能够很好的服从先验分布,
the decoder 尝试从激活向量中去重构原始的图像。
在测试阶段,the encoder 可以通过预测胶囊,来分析输入的图像;
the decoder 通过从先验分布中进行采样,从而可以合成一个新的样本;
本文的创新可以分为如下四个部分:
1. 提供了一种新型的 capsule,即:variational capsules;
2. 提供了一种图像分析和合成的统一框架;
3. 提供了一种新的技术来进行基于条件的图像生成(conditional image generation);
4. 充分的实验验证了本文方法的有效性。
我们先来看看原始的 capsule network 训练的时候,它用的是什么距离?
![]()
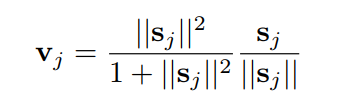
而本文则尝试用 KL-D 来度量,即:
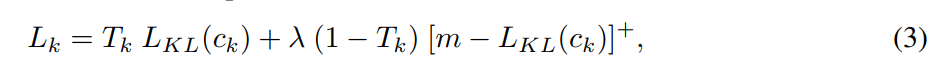
来看本文 3.1 小节:
The capsules proposed in Hinton's paper use the length of the instantiation vector to represent the probability of the existing entity.
为了促进新型胶囊的采样,我们设计的胶囊能够以概率的方式:the activation capsules follow a known prior distribution while the noactive ones do the opposite.
服从 VAEs,我们选择 KL 散度 作为度量两个分布匹配程度的度量方法。所以,带有先验分布的胶囊网络的 KL-散度,代表了一个胶囊示例是否存在的概率,i.e. 对应已有示例的胶囊有较小的 KL散度,而不存在的示意,则有较大的 KL 距离。
Following the original VAEs [10], the prior p(z) is assumed to follow isotropic multivariate Gaussian distribution, i.e., p(z) ∼ N(0; I),
while the proposed capsule qφ(c|x) follows multivariate Gaussian distribution whose mean and covariance are parameterized by N(µ(x); diag(σ2(x))).
The KL- divergence of each capsule c with the prior p(z), i.e., DKL(qφ(c|x)||p(z)), can be computed using Eq. (2).
Let LKL(c) denote the above divergence, we use a separate margin loss Lk for each capsule ck (where k indicates the index of the capsule), which is defined as:
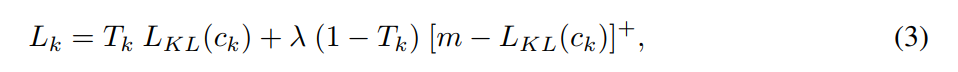
另外,为了获得更好的结果,本文结合了 MSE loss 以及 对抗loss,所以总体的训练loss 函数为:
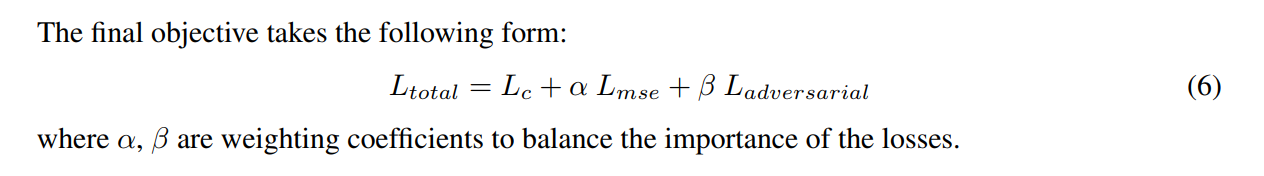
其中,adversarial loss and mse loss 的损失函数分别为:
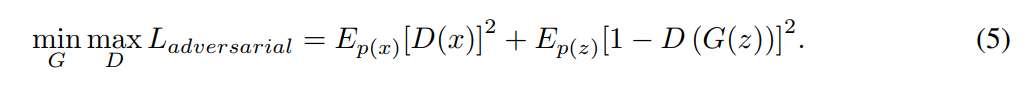
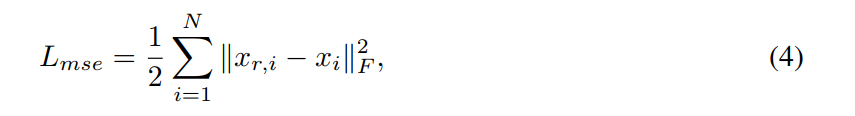


 浙公网安备 33010602011771号
浙公网安备 33010602011771号