
深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble
2017.10.06
材料来自:

首先提到的是 Bagging 的方法:

我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果。例如:
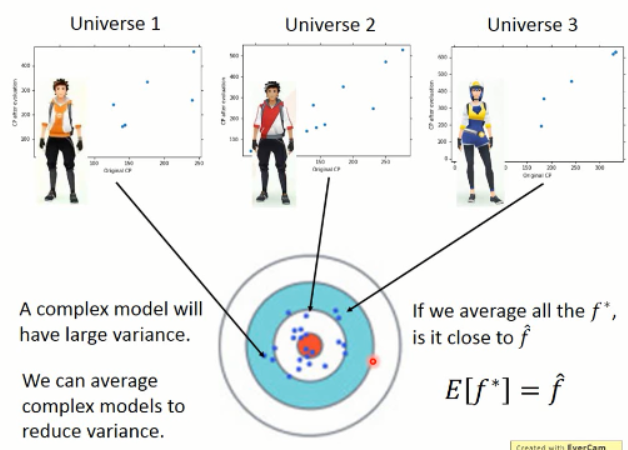
通过这种求平均的方法,可以得到更加接近 真实值的输出。
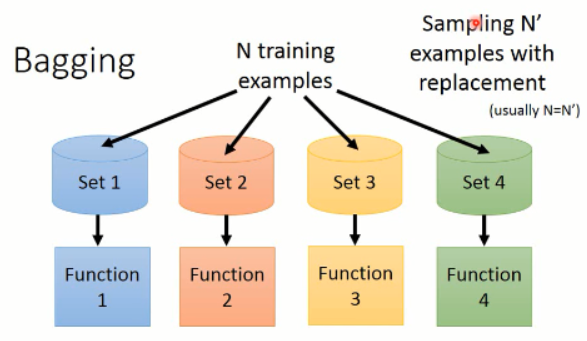
我们可以对训练数据集进行随机采样,构建四个子数据集,然后分别对这些数据进行分类器的训练,得到多个强分类器。
上面是训练的情况,当测试的时候,我们可以将多个分类器的结果综合起来,得到最终的结果。
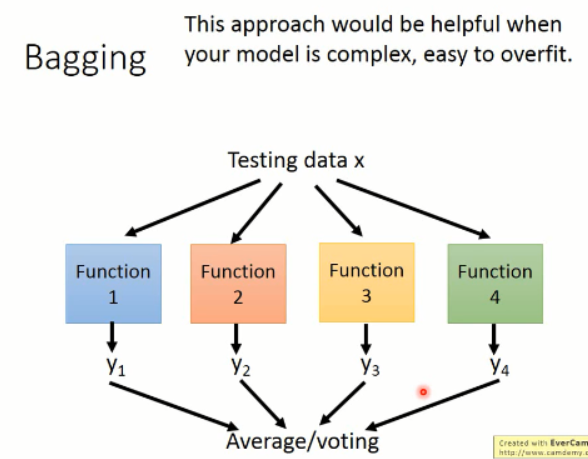

==>> 这些方法在你的模型比较复杂,容易过拟合的时候,才更有效果,如:决策树。。。
随机森林,就是决策树做 bagging 之后的版本。这里,大致讲解了什么是决策树。
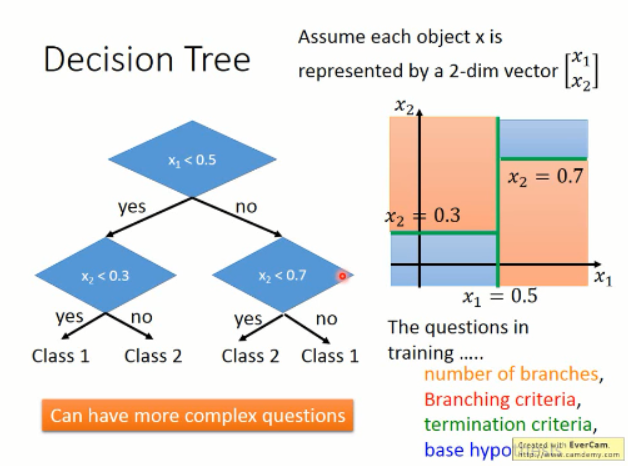
这里,给了一个例子,来说明下决策树。比如说,我们用决策树来做二分类的问题。

我们来看看结果,我们知道,随着树的深度增加,其效果变的非常好了,甚至可以做到在 training data 上的 error 为 0. 这一点,神经网络其实是很难做到的。
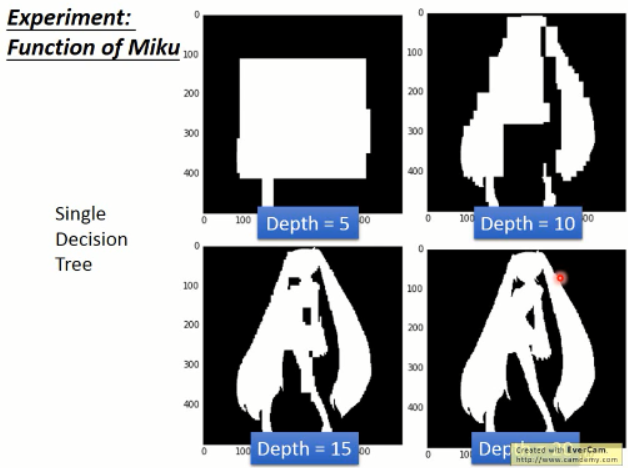
但是,决策树有一个很大的缺点,就是:容易过拟合。我们来引入随机森林。



上面大致就是这样子,针对强分类器的组合,我们用 Bagging 的方法,而对于弱分类器呢?是的,上 Boosting 。。。


需要注意的是:分类器的选择,是依次进行的,是有次序的。。。
假设我们这里需要处理一个二元分类问题,我们有一堆这样子的数据。


Stay Hungry,Stay Foolish ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号