强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)
强化学习策略梯度方法之: REINFORCE 算法 (从原理到代码实现)
2018-04-01 15:15:42
最近在看policy gradient algorithm, 其中一种比较经典的算法当属:REINFORCE 算法,已经广泛的应用于各种计算机视觉任务当中。
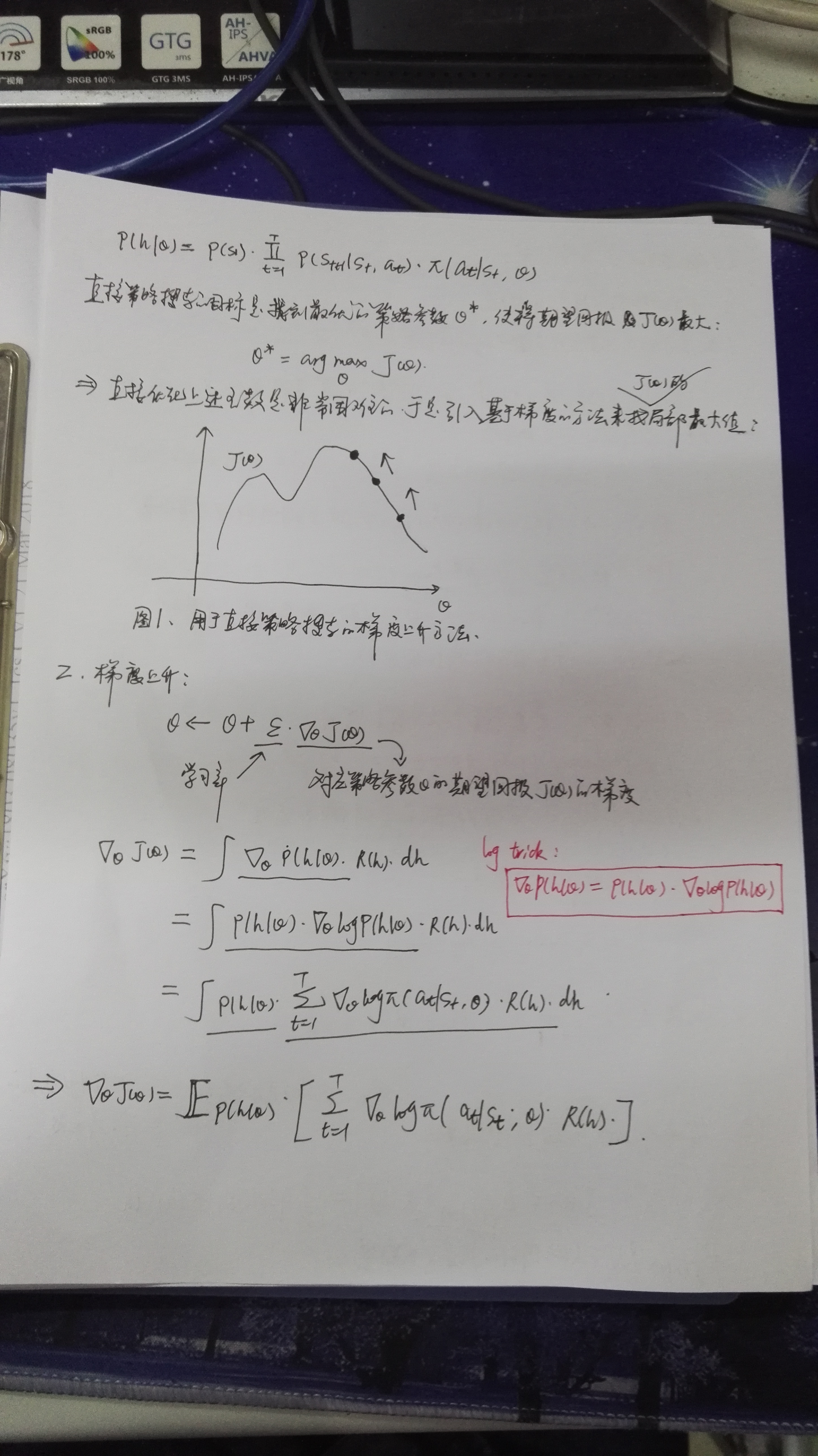
【REINFORCE 算法原理推导】



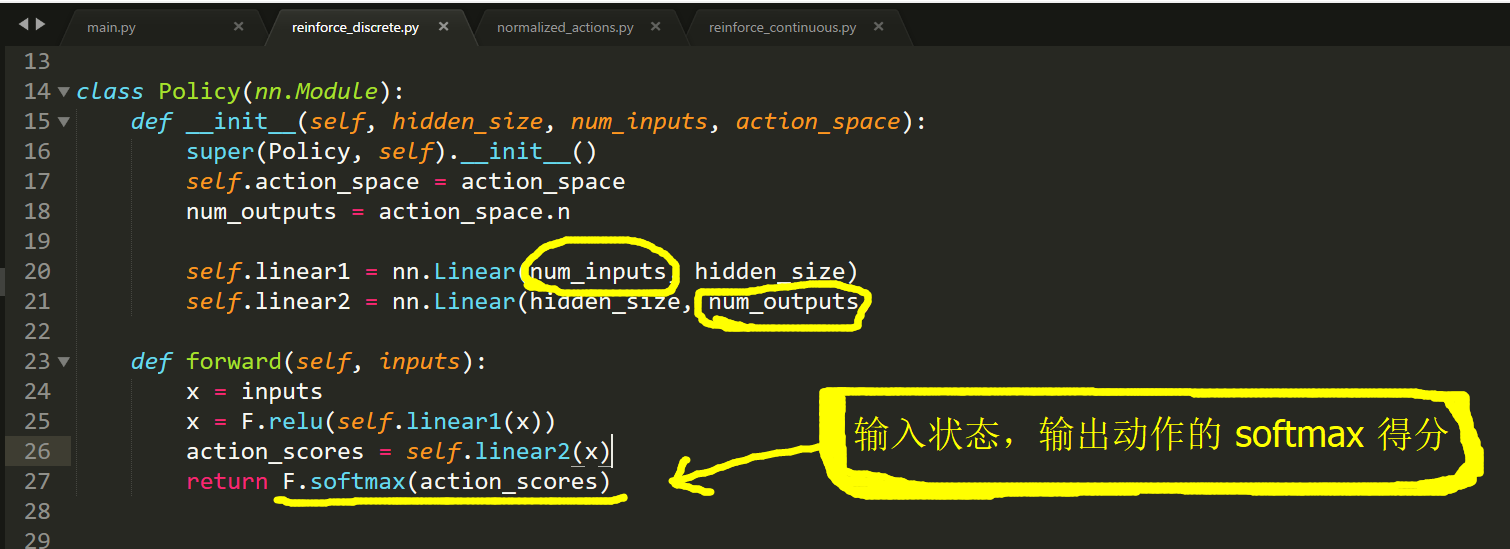
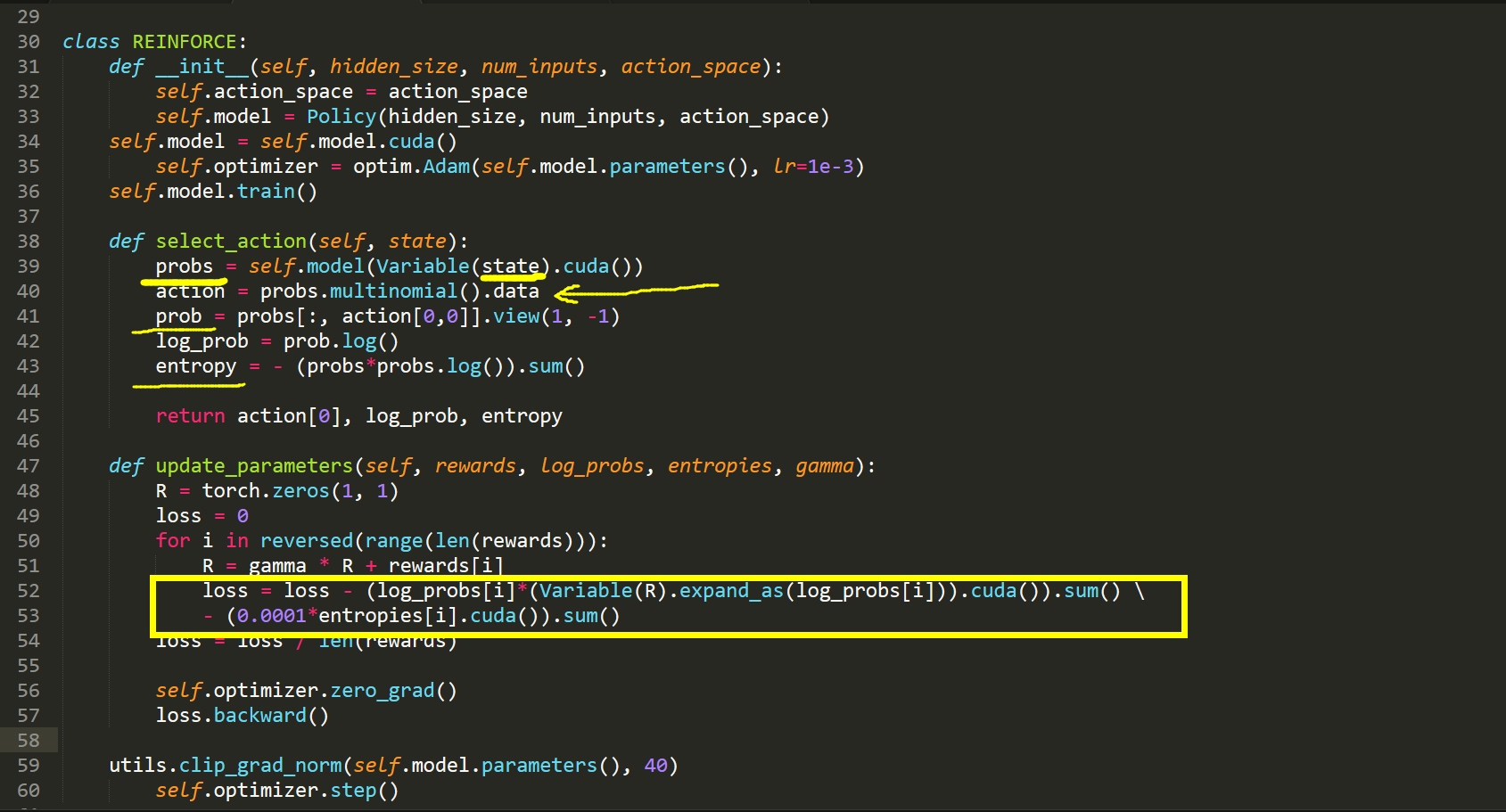
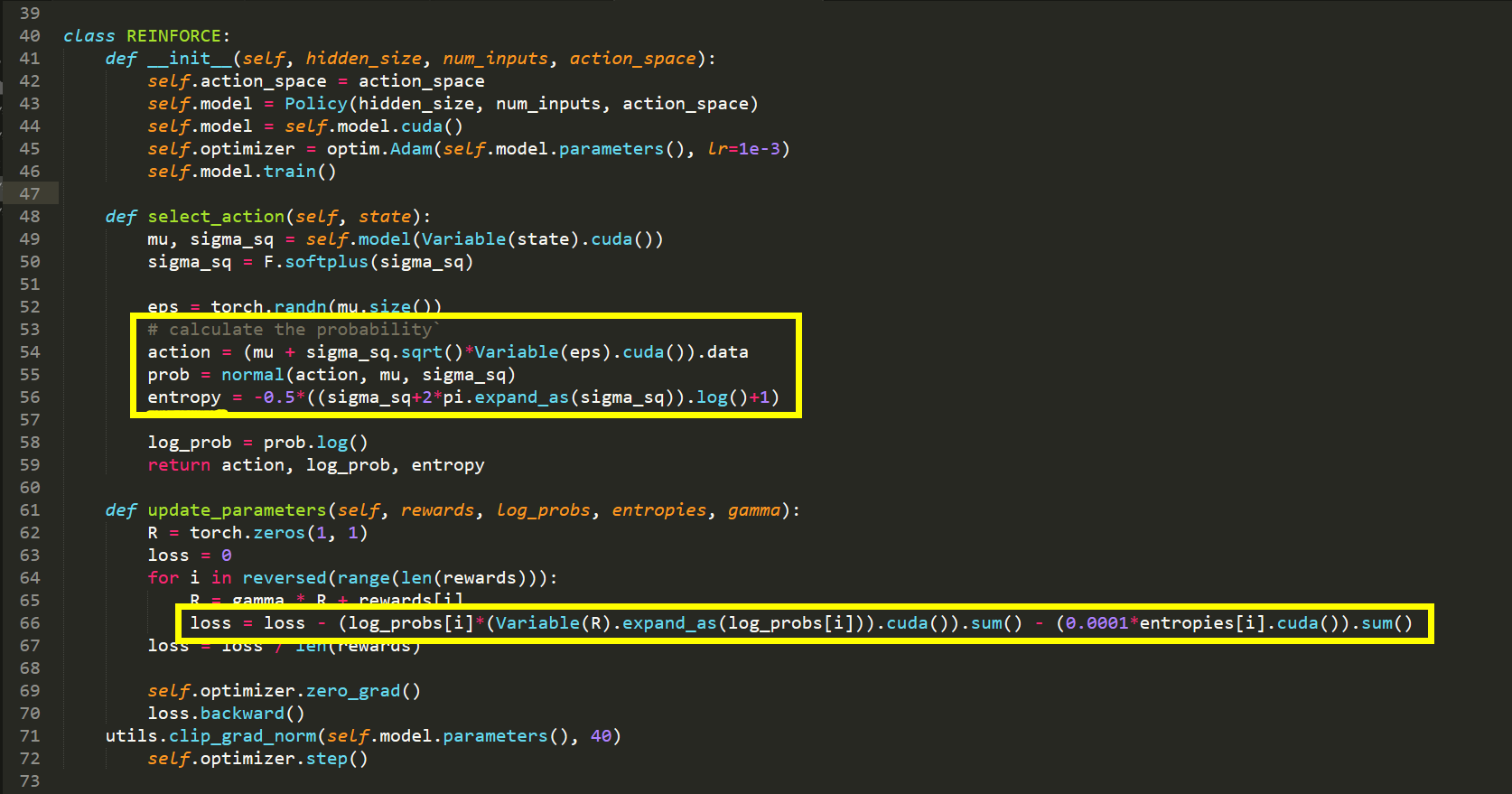
【Pytorch 代码实现】

该图像来自于:https://github.com/JamesChuanggg/pytorch-REINFORCE/blob/master/assets/algo.png

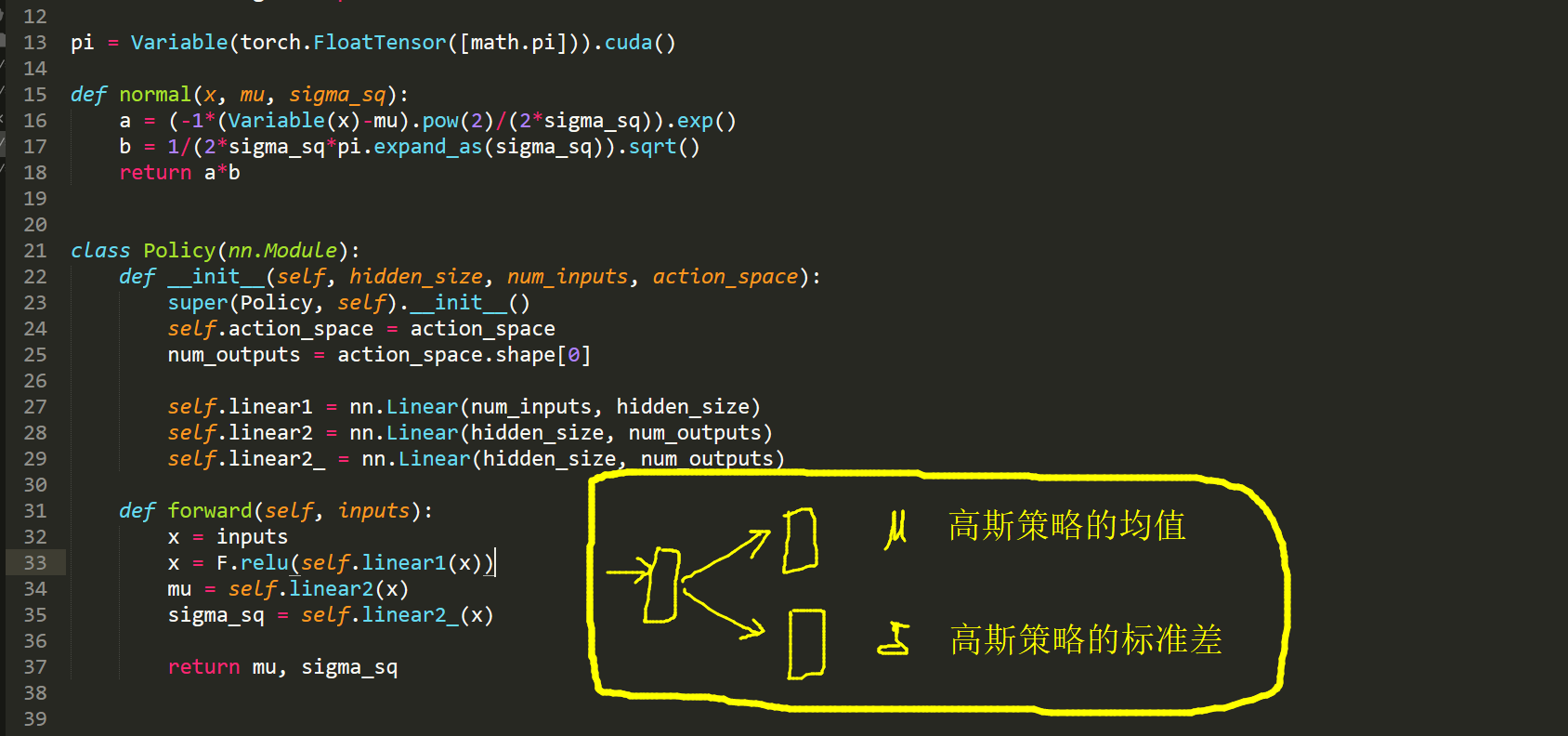
上面函数是 离散情况下的,那么,连续领域是什么情况呢?
-------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------
Reference:
1. 参考博文:http://www.tuananhle.co.uk/notes/reinforce.html
2. 参考博文:http://www.scholarpedia.org/article/Policy_gradient_methods
3. 代码实现(Pytorch version)https://github.com/JamesChuanggg/pytorch-REINFORCE
4. REINFORCE 文章链接:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.129.8871&rep=rep1&type=pdf
5. 书籍:Statistical_Reinforcement_Learning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号