
(转) 深度增强学习与通用人工智能


作者: Flood Sung,CSDN博主,人工智能方向研究生,专注于深度学习,增强学习与机器人的研究。
责编:何永灿,欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至heyc@csdn.net
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
2016年AlphaGo计算机围棋系统战胜顶尖职业棋手李世石,引起了全世界的广泛关注,人工智能进一步被推到了风口浪尖。而其中的深度增强学习算法是AlphaGo的核心,也是通用人工智能的实现关键。本文将带领大家了解深度增强学习的前沿算法思想,领略人工智能的核心奥秘。
前言
深度增强学习(Deep Reinforcement Learning,DRL)是近两年来深度学习领域迅猛发展起来的一个分支,目的是解决计算机从感知到决策控制的问题,从而实现通用人工智能。以Google DeepMind公司为首,基于深度增强学习的算法已经在视频、游戏、围棋、机器人等领域取得了突破性进展。2016年Google DeepMind推出的AlphaGo围棋系统,使用蒙特卡洛树搜索和深度学习结合的方式使计算机的围棋水平达到甚至超过了顶尖职业棋手的水平,引起了世界性的轰动。AlphaGo的核心就在于使用了深度增强学习算法,使得计算机能够通过自对弈的方式不断提升棋力。深度增强学习算法由于能够基于深度神经网络实现从感知到决策控制的端到端自学习,具有非常广阔的应用前景,它的发展也将进一步推动人工智能的革命。
深度增强学习与通用人工智能
当前深度学习已经在计算机视觉、语音识别、自然语言理解等领域取得了突破,相关技术也已经逐渐成熟并落地进入到我们的生活当中。然而,这些领域研究的问题都只是为了让计算机能够感知和理解这个世界。以此同时,决策控制才是人工智能领域要解决的核心问题。计算机视觉等感知问题要求输入感知信息到计算机,计算机能够理解,而决策控制问题则要求计算机能够根据感知信息进行判断思考,输出正确的行为。要使计算机能够很好地决策控制,要求计算机具备一定的“思考”能力,使计算机能够通过学习来掌握解决各种问题的能力,而这正是通用人工智能(Artificial General Intelligence,AGI)(即强人工智能)的研究目标。通用人工智能是要创造出一种无需人工编程自己学会解决各种问题的智能体,最终目标是实现类人级别甚至超人级别的智能。
通用人工智能的基本框架即是增强学习(Reinforcement Learning,RL)的框架,如图1所示。
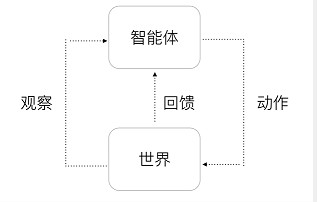 图1 通用人工智能基本框架
图1 通用人工智能基本框架
智能体的行为都可以归结为与世界的交互。智能体观察这个世界,然后根据观察及自身的状态输出动作,这个世界会因此而发生改变,从而形成回馈返回给智能体。所以核心问题就是如何构建出这样一个能够与世界交互的智能体。深度增强学习将深度学习(Deep Learning)和增强学习(Reinforcement Learning)结合起来,深度学习用来提供学习的机制,而增强学习为深度学习提供学习的目标。这使得深度增强学习具备构建出复杂智能体的潜力,也因此,AlphaGo的第一作者David Silver认为深度增强学习等价于通用人工智能DRL=DL+RL=Universal AI。
深度增强学习的Actor-Critic框架
目前深度增强学习的算法都可以包含在Actor-Critic框架下,如图2所示。
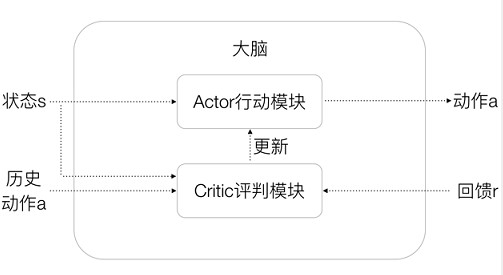 图2 Actor-Critic框架
图2 Actor-Critic框架
把深度增强学习的算法认为是智能体的大脑,那么这个大脑包含了两个部分:Actor行动模块和Critic评判模块。其中Actor行动模块是大脑的执行机构,输入外部的状态s,然后输出动作a。而Critic评判模块则可认为是大脑的价值观,根据历史信息及回馈r进行自我调整,然后影响整个Actor行动模块。这种Actor-Critic的方法非常类似于人类自身的行为方式。我们人类也是在自身价值观和本能的指导下进行行为,并且价值观受经验的影响不断改变。在Actor-Critic框架下,Google DeepMind相继提出了DQN,A3C和UNREAL等深度增强学习算法,其中UNREAL是目前最好的深度增强学习算法。下面我们将介绍这三个算法的基本思想。
DQN(Deep Q Network)算法
DQN是Google DeepMind于2013年提出的第一个深度增强学习算法,并在2015年进一步完善,发表在2015年的《Nature》上。DeepMind将DQN应用在计算机玩Atari游戏上,不同于以往的做法,仅使用视频信息作为输入,和人类玩游戏一样。在这种情况下,基于DQN的程序在多种Atari游戏上取得了超越人类水平的成绩。这是深度增强学习概念的第一次提出,并由此开始快速发展。
DQN算法面向相对简单的离散输出,即输出的动作仅有少数有限的个数。在这种情况下,DQN算法在Actor-Critic框架下仅使用Critic评判模块,而没有使用Actor行动模块,因为使用Critic评判模块即可以选择并执行最优的动作,如图3所示。
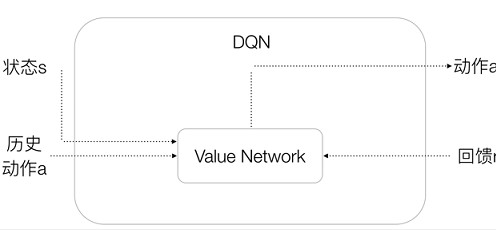 图3 DQN基本结构
图3 DQN基本结构
在DQN中,用一个价值网络(Value Network)来表示Critic评判模块,价值网络输出Q(s,a),即状态s和动作a下的价值。基于价值网络,我们可以遍历某个状态s下各种动作的价值,然后选择价值最大的一个动作输出。所以,主要问题是如何通过深度学习的随机梯度下降方法来更新价值网络。为了使用梯度下降方法,我们必须为价值网络构造一个损失函数。由于价值网络输出的是Q值,因此如果能够构造出一个目标Q值,就能够通过平方差MSE的方式来得到损失函数。但对于价值网络来说,输入的信息仅有状态s,动作a及回馈r。因此,如何计算出目标Q值是DQN算法的关键,而这正是增强学习能够解决的问题。基于增强学习的Bellman公式,我们能够基于输入信息特别是回馈r构造出目标Q值,从而得到损失函数,对价值网络进行更新。
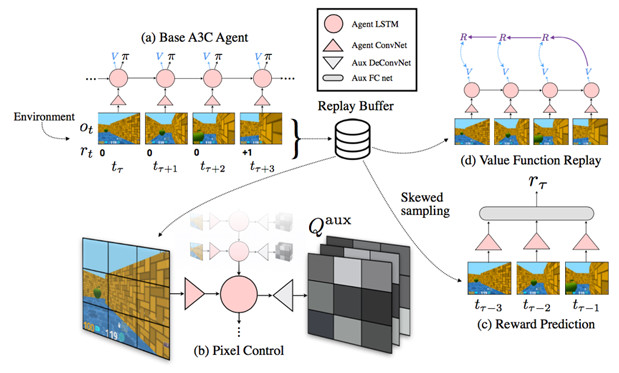 图4 UNREAL算法框图
图4 UNREAL算法框图
在实际使用中,价值网络可以根据具体的问题构造不同的网络形式。比如Atari有些输入的是图像信息,就可以构造一个卷积神经网络(Convolutional Neural Network,CNN)来作为价值网络。为了增加对历史信息的记忆,还可以在CNN之后加上LSTM长短记忆模型。在DQN训练的时候,先采集历史的输入输出信息作为样本放在经验池(Replay Memory)里面,然后通过随机采样的方式采样多个样本进行minibatch的随机梯度下降训练。
DQN算法作为第一个深度增强学习算法,仅使用价值网络,训练效率较低,需要大量的时间训练,并且只能面向低维的离散控制问题,通用性有限。但由于DQN算法第一次成功结合了深度学习和增强学习,解决了高维数据输入问题,并且在Atari游戏上取得突破,具有开创性的意义。
A3C(Asynchronous Advantage Actor Critic)算法
A3C算法是2015年DeepMind提出的相比DQN更好更通用的一个深度增强学习算法。A3C算法完全使用了Actor-Critic框架,并且引入了异步训练的思想,在提升性能的同时也大大加快了训练速度。A3C算法的基本思想,即Actor-Critic的基本思想,是对输出的动作进行好坏评估,如果动作被认为是好的,那么就调整行动网络(Actor Network)使该动作出现的可能性增加。反之如果动作被认为是坏的,则使该动作出现的可能性减少。通过反复的训练,不断调整行动网络找到最优的动作。AlphaGo的自我学习也是基于这样的思想。
基于Actor-Critic的基本思想,Critic评判模块的价值网络(Value Network)可以采用DQN的方法进行更新,那么如何构造行动网络的损失函数,实现对网络的训练是算法的关键。一般行动网络的输出有两种方式:一种是概率的方式,即输出某一个动作的概率;另一种是确定性的方式,即输出具体的某一个动作。A3C采用的是概率输出的方式。因此,我们从Critic评判模块,即价值网络中得到对动作的好坏评价,然后用输出动作的对数似然值(Log Likelihood)乘以动作的评价,作为行动网络的损失函数。行动网络的目标是最大化这个损失函数,即如果动作评价为正,就增加其概率,反之减少,符合Actor-Critic的基本思想。有了行动网络的损失函数,也就可以通过随机梯度下降的方式进行参数的更新。
为了使算法取得更好的效果,如何准确地评价动作的好坏也是算法的关键。A3C在动作价值Q的基础上,使用优势A(Advantage)作为动作的评价。优势A是指动作a在状态s下相对其他动作的优势。假设状态s的价值是V,那么A=Q-V。这里的动作价值Q是指状态s下a的价值,与V的含义不同。直观上看,采用优势A来评估动作更为准确。举个例子来说,假设在状态s下,动作1的Q值是3,动作2的Q值是1,状态s的价值V是2。如果使用Q作为动作的评价,那么动作1和2的出现概率都会增加,但是实际上我们知道唯一要增加出现概率的是动作1。这时如果采用优势A,我们可以计算出动作1的优势是1,动作2的优势是-1。基于优势A来更新网络,动作1的出现概率增加,动作2的出现概率减少,更符合我们的目标。因此,A3C算法调整了Critic评判模块的价值网络,让其输出V值,然后使用多步的历史信息来计算动作的Q值,从而得到优势A,进而计算出损失函数,对行动网络进行更新。
A3C算法为了提升训练速度还采用异步训练的思想,即同时启动多个训练环境,同时进行采样,并直接使用采集的样本进行训练。相比DQN算法,A3C算法不需要使用经验池来存储历史样本,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。
A3C算法在以上多个环节上做出了改进,使得其在Atari游戏上的平均成绩是DQN算法的4倍,取得了巨大的提升,并且训练速度也成倍的增加。因此,A3C算法取代了DQN成为了更好的深度增强学习算法。
UNREAL(UNsupervised REinforcement and Auxiliary Learning)算法
UNREAL算法是2016年11月DeepMind提出的最新深度增强学习算法,在A3C算法的基础上对性能和速度进行进一步提升,在Atari游戏上取得了人类水平8.8倍的成绩,并且在第一视角的3D迷宫环境Labyrinth上也达到了87%的人类水平,成为当前最好的深度增强学习算法。
A3C算法充分使用了Actor-Critic框架,是一套完善的算法,因此,我们很难通过改变算法框架的方式来对算法做出改进。UNREAL算法在A3C算法的基础上,另辟蹊径,通过在训练A3C的同时,训练多个辅助任务来改进算法。UNREAL算法的基本思想来源于我们人类的学习方式。人要完成一个任务,往往通过完成其他多种辅助任务来实现。比如说我们要收集邮票,可以自己去买,也可以让朋友帮忙获取,或者和其他人交换的方式得到。UNREAL算法通过设置多个辅助任务,同时训练同一个A3C网络,从而加快学习的速度,并进一步提升性能。
在UNREAL算法中,包含了两类辅助任务:第一种是控制任务,包括像素控制和隐藏层激活控制。像素控制是指控制输入图像的变化,使得图像的变化最大。因为图像变化大往往说明智能体在执行重要的环节,通过控制图像的变化能够改善动作的选择。隐藏层激活控制则是控制隐藏层神经元的激活数量,目的是使其激活量越多越好。这类似于人类大脑细胞的开发,神经元使用得越多,可能越聪明,也因此能够做出更好的选择。另一种辅助任务是回馈预测任务。因为在很多场景下,回馈r并不是每时每刻都能获取的(比如在Labyrinth中吃到苹果才能得1分),所以让神经网络能够预测回馈值会使其具有更好的表达能力。在UNREAL算法中,使用历史连续多帧的图像输入来预测下一步的回馈值作为训练目标。除了以上两种回馈预测任务外,UNREAL算法还使用历史信息额外增加了价值迭代任务,即DQN的更新方法,进一步提升算法的训练速度。
UNREAL算法本质上是通过训练多个面向同一个最终目标的任务来提升行动网络的表达能力和水平,符合人类的学习方式。值得注意的是,UNREAL虽然增加了训练任务,但并没有通过其他途径获取别的样本,是在保持原有样本数据不变的情况下对算法进行提升,这使得UNREAL算法被认为是一种无监督学习的方法。基于UNREAL算法的思想,可以根据不同任务的特点针对性地设计辅助任务,来改进算法。
小结
深度增强学习经过近两年的发展,在算法层面上取得了越来越好的效果。从DQN,A3C到UNREAL,精妙的算法设计无不闪耀着人类智慧的光芒。在未来,除了算法本身的改进,深度增强学习作为能够解决从感知到决策控制的通用型学习算法,将能够在现实生活中的各种领域得到广泛的应用。AlphaGo的成功只是通用人工智能爆发的前夜。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号