论文笔记之:Speed Up Tracking by Ignoring Features
Speed Up Tracking by Ignoring Features
CVPR 2014
Abstract:本文提出一种特征选择的算法,来实现用最“精简”的特征以进行目标跟踪。重点是提出一种上界 (Upper Bound)来表示一块区域包含目标物体的概率,并且忽略掉这个 bound比较小的区域。我们的实验表明,忽略掉 90%的特征,仍然取得了不错的结果(未损失精度)。
Ignoring Features in Tracking .
基于滑动窗口的跟踪器,计算大量的 bounding-box 和 target object 之间的相似性,并且返回最大相应的位置,作为跟踪的结果。有两种属性,可以用于提升该类算法的速度:
(1)the score they compute is defined as the sum of a bias b and inner product between the object model W and the features X extracted from bounding box B ;
(2)the individual feature values can be upper and lower bounds for popular features including HOG features, LBP and Haar features.
本文提出的 feature ignoring tracker (FIT)探索了上述两种属性,目的是发现具有最高响应值的位置,而对于大部分 bbox 来说都不计算其全部得分。
FIT 扔掉了具有较小机会得到最高score 的 Bbox,after only a small subset of the feature is considered。
FIT 通过如下的过程,完成该目标:
(1)Upper bounding the probability that a bounding box can attain the highest score, considering the part of the inner product currently computed ;
(2)discarding bounding box for which this probability is below some threshold .
FIT 对物体表观模型 w 进行排序,具有最高绝对权重 的特征 x 最先被考虑。(排序操作仅仅执行一次,从而不影响 tracker 的跟踪效率);
接下来,FIT 基于前 d features 计算所有可能 Bbox 的subscore。
我们选择具有最大 subscore 的 Bbox 作为第一个候选区域,然后计算这个 Bbox 里面的全部得分。
为了确定是否我们仍然需要考虑任意的其他的 Bbox B 的 更多 feature,我们计算 Bbox B 仍然可能会得到更高得分的概率,相比较刚刚选定的候选 Bbox :
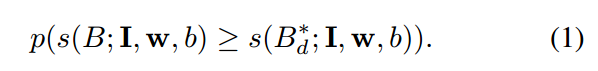
但是这个概率在没有特征分布 P(x) 的前提下是无法计算的。 但是 给定 Bbox B 划定一个得到比预定的 Bbox 更高得分的概率是可能的:

where expectation is over the part of the bounding box score that has not yet been computed .
重要的是,公式 2 的上界可以有效的进行计算,因为 w 当中的元素是 sort 之后的,我们该 feature 的 upper and lower bound ,u and l. 特别的,公式 2 可以计算如下:
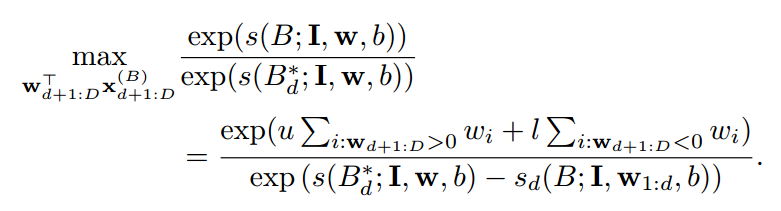
注意到,w 当中正样本和负样本的个数可以通过离线的计算得到,并且存储 d 的每一个值,分母当中的每一项都是预先计算好的。所以,公式 2 当中 Bbox B 的上界的时间复杂度为 O (1)。
FIT 接下来通过计算 公式 2 的 Upper Boun,然后扔掉所有的 Bbox ,其 upper bound 小于设定的阈值的时候。接着,剩余的 Bbox 的 subscore 通过添加新的 feature 子集进行更新,实际的 score 是基于更新的 subscore 得到最可靠的位置,Bbox 的score小于阈值的,则会被扔掉。重复迭代此过程,直到只剩下一个 Bbox 或者 所有的特征都用于计算 Bbox 的 score。伪代码见下图:

总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号