论文笔记之:A CNN Cascade for Landmark Guided Semantic Part Segmentation
A CNN Cascade for Landmark Guided Semantic Part Segmentation
ECCV 2016
摘要:本文提出了一种 CNN cascade (CNN 级联)结构,根据一系列的定位(landmarks or keypoints),得到特定的 pose 信息,进行 语义 part 分割。前人有许多单独的工作,但是,貌似没有将这两个工作结合到一起,相互作用的 multi-task 的工作。本文就弥补这个缺口,提出一种 CNN cascade 的 tasks,首先进行 landmark的定位,然后将这个信息作为输入,用于指导 semantic part segmentation。作者将这个结构用于 facial part segmentation,取得了显著的效果。代码将会很快放出,候选连接如下:http://www.cs.nott.ac.uk/~psxasj/
引言:就像摘要里提到的差不多,就是这个意思。不废话了。看看效果图,然后看看别人怎么做的。。。

本文的创新点写的很有特色,说解决了下面的两个问题:
1. Is a CNN for facial part segmentation needed at all ?
2. Can facial landmarks be used for guiding facial part segmentation, thus reversing the result metioned above ?


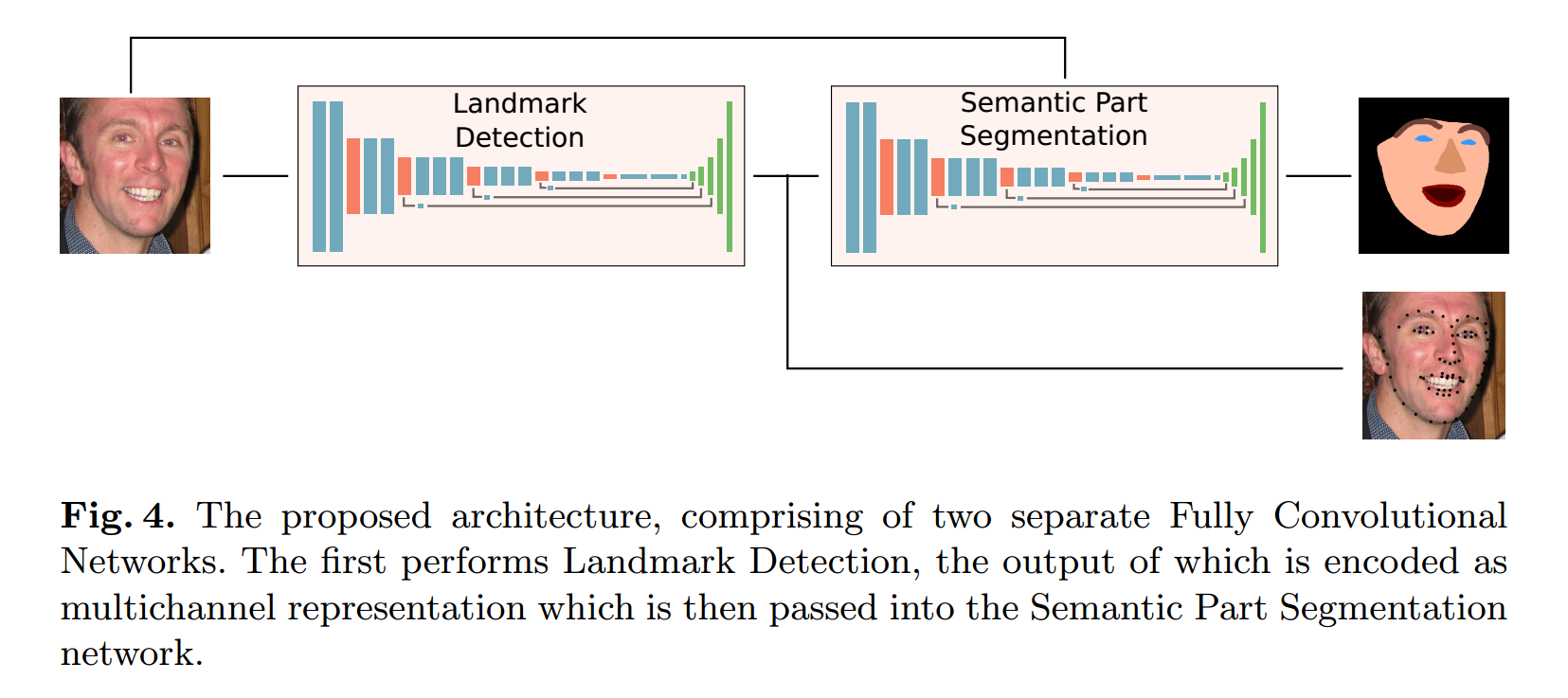
The Proposed Method :
本文提出的 CNN 级联网络结构,如上图 4 所示,是一个 landmark localisation 网络,紧跟着是一个 facial part segmentation 网络结构。这个级联网络是基于 VGG-FCN 的,基于 CAFFE ,主要由两个部分构成:
1. 利用交叉熵损失函数(Sigmoid Cross Entropy Loss)进行 facial landmarks 的检测,这是一个 FCN 网络;
2. 第二,是受到 human pose estimation method 【1】 的激发,检测到的 68 个定位点,编码成 68 个单独的 channels,这个 channels 在其对应的 landmark 位置有一个 2D Gaussian 。这 68 个channels 堆积在一起,和原始图像一起传送给 segmentation network。然后用标准的 Softmax loss 进行分割。
这里的【1】是:Human pose estimation with iterative error feedback. CVPR 2016
接下来,详细的介绍这两个网络架构:
Facial Landmark Detection:
对于 landmark detection 的训练过程类似于训练一个 FCN 用于 part segmentation。将 Landmarks 编码成位于提供的 landmarks' location 的 2D Gaussian。每一个 landmark 分配其单独的 channel 来阻止与其他 landmark 的重合,允许每一个 point 更加容易相互区分。与 part segmentation 主要的不同在于 其 loss function。Sigmoid Cross Entropy Loss 被用来回归一个像素点包含一个 point 的可能性。More concretely,给定我们的 gt Gaussians P 和 预测的 Gaussians p, 每一个相同维度是 N*W*H, 定义的损失函数为:
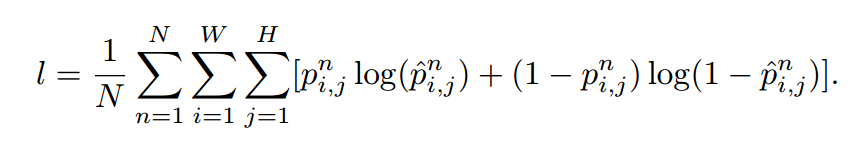
Guided Facial Part Segmentation:
采用和 FCN 类似的配置方法进行分割,利用 softmax loss 作为最后的损失函数。如果 N 是输出的个数,$p_{i, j}$ 是像素点$(i, j)$的预测输出,n 是 gt label,那么 softmax loss l 就可以表达为:
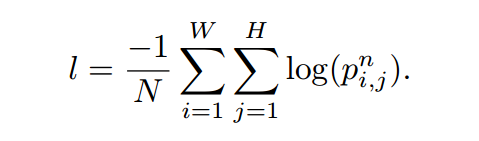
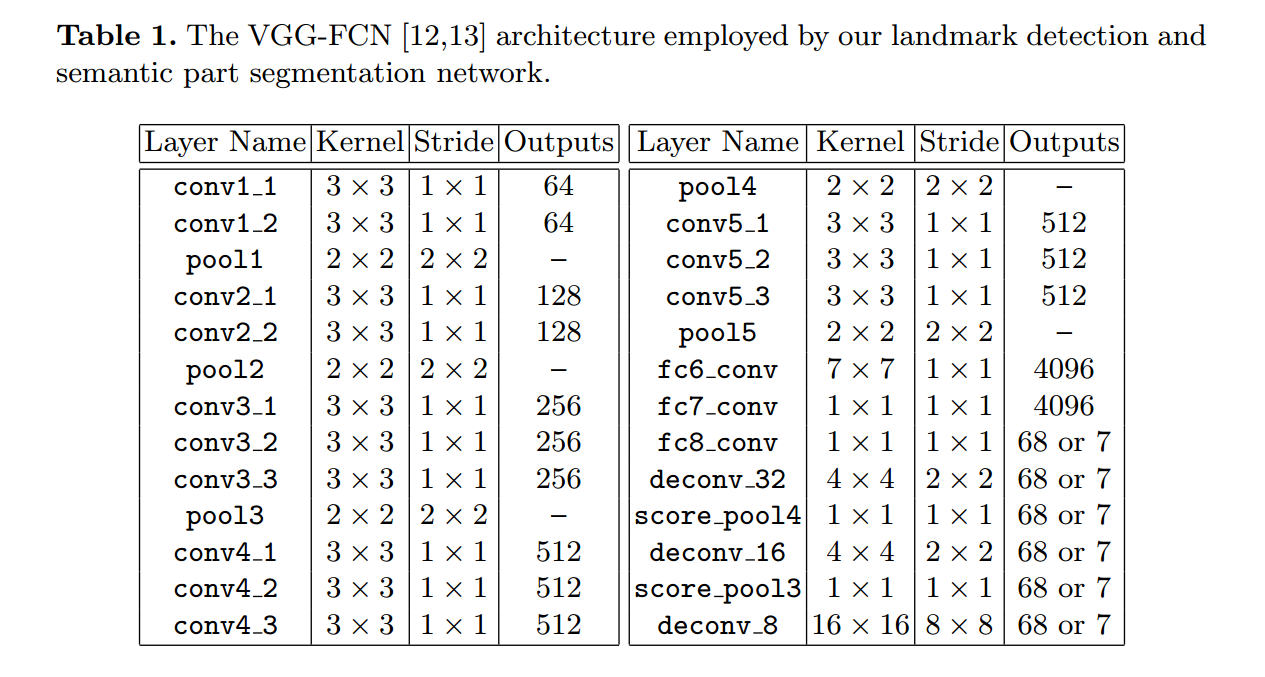
下面的表格展示了所用的 VGG-FCN 网络结构的具体参数设置:
Reference Paper:
1. Human pose estimation with iterative error feedback. CVPR 2016
2. A CNN Cascade for Landmark Guided Semantic Part Segmentation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号