论文笔记之: Deep Metric Learning via Lifted Structured Feature Embedding
Deep Metric Learning via Lifted Structured Feature Embedding
CVPR 2016
摘要:本文提出一种距离度量的方法,充分的发挥 training batches 的优势,by lifting the vector of pairwise distances within the batch to the matrix of pairwise distances. 刚开始看这个摘要,有点懵逼,不怕,后面会知道这段英文是啥意思的。
引言部分开头讲了距离相似性度量的重要性,并且应用广泛。这里提到了三元组损失函数 (triplet loss),就是讲在训练的过程当中,尽可能的拉近两个相同物体之间的距离,而拉远不同物体之间的距离;这种做法会比普通的训练方法得到更好的效果。但是,文章中提到,现有的三元组方法却无法充分利用 minibatch SGD training 的 training batches 的优势。现有的方法首先随机的采样图像对或者三元组,构建训练 batches, 计算每一个 pairs or triplets 的损失。本文提出一种方法,称为:lifts,将 the vector of pairwise distances 转换成 the matrix of pairwise distance. 然后在 lifts problem 上设计了一个新的结构损失目标。结果表明,在 GoogleLeNet network 上取得了比其他方法都要好的结果。
然后作者简单的回顾了一下关于判别性训练网络(discriminatively training networks)来学习 semantic embedding。大致结构预览图如下所示:
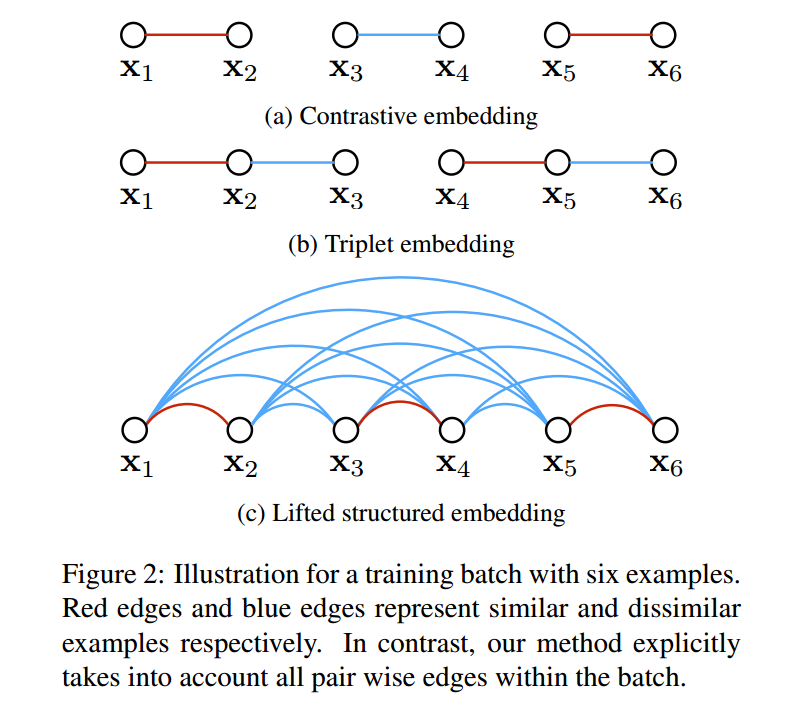
首先是: Contrastive embedding.
这种方法在 paired data ${(x_i, x_j, y_{ij})}$上进行训练。这种 contrastive training 最小化具有相同 label 类别的样本之间的距离,然后对不同label的样本,但是其距离小于 $\alpha$ 的 negative pair 给予惩罚。代价函数的定义为:
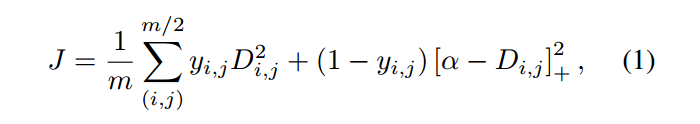
其中,m 代表batch中图像的个数,f(*)是网路输出的特征,即原文中表达的:the feature embedding output from the network. $D_{i, j}$ 是两个样本特征之间欧式距离的度量。标签 $y_{i, j} \in {0, 1}$表明是否样本对来自同一个类别。$[*]_+$ 操作是 the hinge function max(0, *)。
第二个是:Triplet embedding。
这个就是著名的三元组损失函数了,即:找一个 anchor,然后找一个正样本,一个负样本。训练的目的就是:鼓励网络找到一个 embedding 使得 xa and xn 之间的距离大于 xa and xp 加上一个 margin $\alpha$ 的和。损失函数定义为:
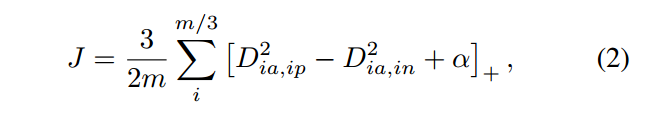
其中,D仍然表示样本之间特征的距离。
然后就是本文提出的一种度量方法了:
Deep metric learning via lifted structured feature embedding.
我们基于训练集合的正负样本,定义了一个结构化的损失函数:
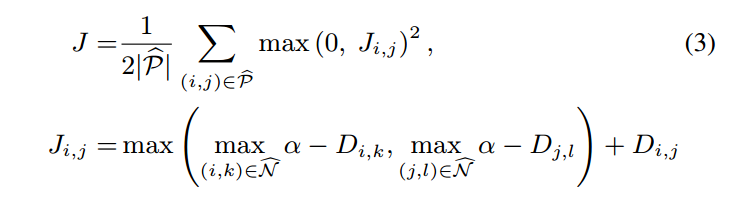
其中,P 是正样本的集合,N 是负样本的集合。这个函数提出了两个计算上的挑战:
1. 非平滑(non-smooth)
2. 评价和计算其子梯度需要最小化所有样本对若干次。
我们以两种方式解决了上述挑战:
首先,我们优化上述函数的一个平滑上界;
第二,对于大数据常用的方法类似,我们采用随机的方法。
然而,前人的工作都是用SGD的方法,随机的均匀的选择 pairs or triplets。我们的方法从这之中得到了借鉴:
(1). it biases the sample towards including "difficult" pairs, just like a subgradient of $J_{i,j}$ would use the close negative pairs;
(2). 一次采样就充分的利用了一个 mini-batch的全部信息,而不仅仅是两个pair之间的信息。
为了充分的利用这个 batch,一个关键的 idea 是增强 mini-batch 的优化以利用所有的pairs。
需要注意的是:随机采样的样本对之间的 negative edges 携带了非常有限的信息。
所以,我们的方法改为并非完全随机,而是引入了重要性采样的元素。我们随机的采样了一些 positive pairs,然后添加了一些他们的 difficult neighbors 来训练 mini-batch. 这个增强增加了子梯度会用到的相关信息。下图展示了一个 positive pair 在一个 batch 中的搜索过程,即:在一个 positive pair 的图像中,我们找到其 close(hard)negative images。
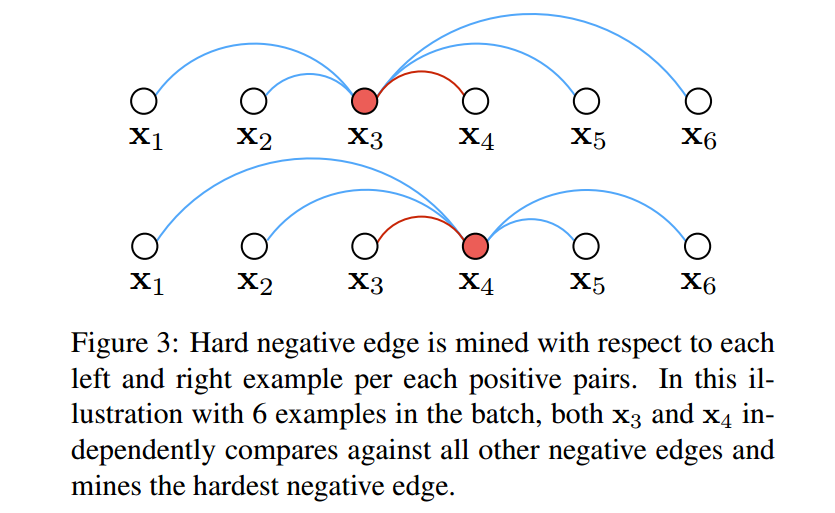
注意到我们的方法可以从两端开始搜索,而三元组则仅仅只能和定义好的结构上的元素进行搜索。
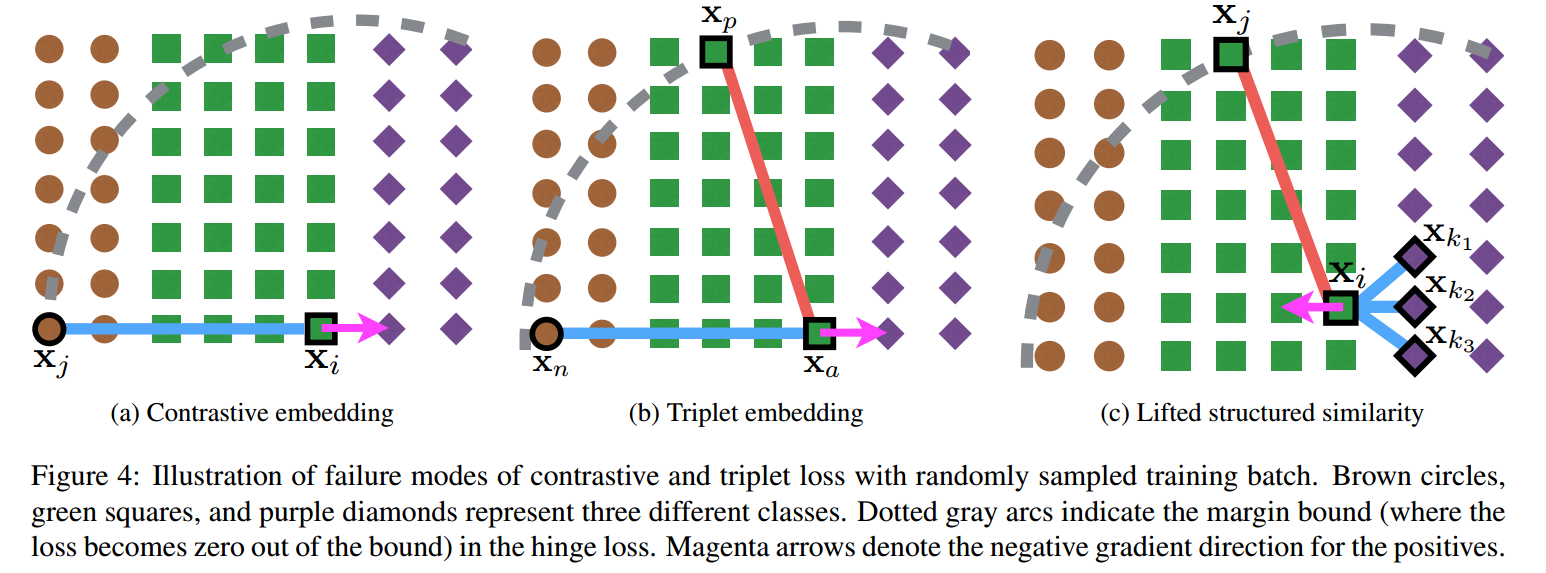
此外,搜索 single hardest negative with nested max function 实际上会导致网络收敛到一个 bad local optimum. 所以我们采用了如下的 smooth upper bound,所以 我们的损失函数定义为:

其中,P是batch中 positive pairs 集合,N 是negative pairs 的集合。后向传播梯度可以如算法1所示的那样,对应距离的梯度为:
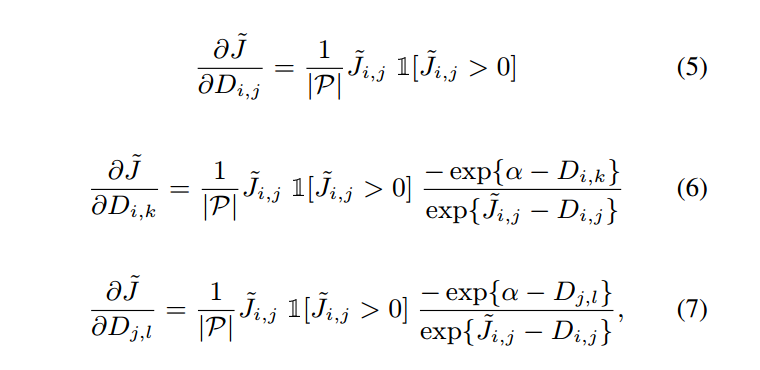
其中的 1[*] 是指示函数,如果括号内的判断为真,那么输出为1,否则就是0.
本文的算法流程图,如下所示:

结果展示:



文章总结:
可以看出,本文是在三元组损失函数基础上的一个改进。并非仅仅考虑预先定义好的样本之间的差异性,而是考虑到一个 batches 内部 所有的样本之间的差异。在这个过程中,文章中引入了类似 hard negative mining 的思想,考虑到正负样本之间的难易程度。并且为了避免网络的训练陷入到 局部最优的bug中去,引入了损失函数的上界来缓解这个问题。
一个看似不大的改动,却可以发到CVPR,也从某个角度说明了这个方法的价值。
难道,三元组损失函数就这样被这个算法击败了? 自己当初看到三元组损失函数的时候,为什么就没有忘这个方向去思考呢???
还有一个疑问是:为什么这种方法的操作,称为:lifted structured feature embedding ?
难道说,是因为这个左右移动的搜索 hard negative samples 的过程类似于电梯(lift)?那 feature embedding 怎么理解呢? embedding 是映射,难道是:特征映射么??


 浙公网安备 33010602011771号
浙公网安备 33010602011771号