DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods)
前面介绍了很多关于 state or state-action pairs 方面的知识,为了将其用于控制,我们学习 state-action pairs 的值,并且将这些值函数直接用于执行策略和选择动作.这种形式的方法称为:action-value methods.
下面要介绍的方法也是计算这些 action (or state) values,但是并非直接用于选择 action, 而是直接表示该策略,其权重不依赖于任何值函数.
1.1 Actor-Critic Methods.
Actor-critic methods 是一种时序查分方法(TD),有一个独立的记忆结构来显示的表示策略,而与 value function 无关.该策略结构称为:actor,因为其用于选择动作,预测的值函数被称为:critic,因为其用于批判 actor 执行的动作.学习是on-policy的: the critic must learn about and critique whatever policy is currently being followed by the actor. The critique takes the form of a TD error. 尺度信号是单纯的 critic 的输出,并且引导 actor and critic 的学习,像下图所示:
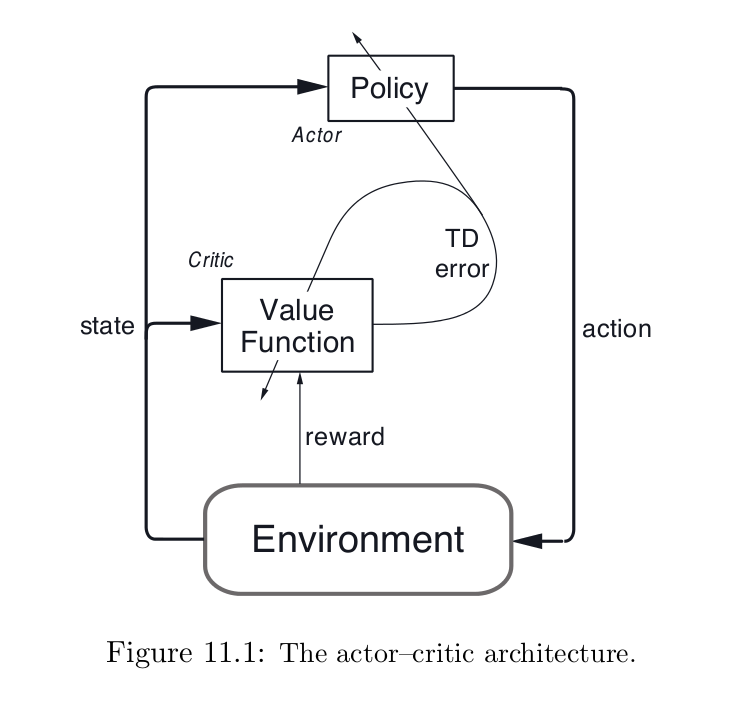
Actor-critic methods 是 gradient-bandit methods自然的拓展到 TD-learning和全部的 RL 学习问题. 通常情况下, the critic 是状态-值函数.再一次的动作选择之后,the critic 评价新的策略来检测是否事情朝着期望的方向发展.评价通常是根据 TD error 得到的:

其中,$V_t$是第 t 时刻 the critic 执行的值函数,TD error可以被用来评价刚刚选择的 action,在状态$S_t$下选择的动作$A_t$.是否TD error是 positive的,这表明若是,则会在将来加强选择该动作的趋势,若是负的,则会降低选择该动作的优先级.假设动作是由 the Gibbs softmax method 产生的:

其中,$H_t(s, a)$是在第 t 时刻由策略参数可改变的 actor 的值,表示在时刻 t 状态 s 下选择每一个动作 a 的趋势(preference).通过增加或者减少 $H_t(S_t, A_t)$ 来调整上述选择,即:
![]()
其中 $\beta$是另一个正的步长参数.
这仅仅是 actor-critic method 的案例,另一个变种用另一种方式来选择动作,或者 eligibility traces.另一个共同的地方,像强化对比方法,是为了包括额外的因子来改变证据的量(is to include additional factors varying the amount of credit assigned to the action taken, $A_t$).比如,一个通用的像这样的因子是和选择动作$A_t$相反的关系,得到如下的更新法则:

许多最早的强化学习系统利用的TD方法是 actor-critic methods. 然后,更多的注意力被放在学习动作-值函数(action-value functions) 和 从估计的值来充分的决定一个策略(例如:Sarsa and Q-learning).这个分化也许仅仅是一个历史的偶尔.例如:你可能会想到中间的结构,an action-value function 和 an independent policy 将会被学到.在任何事件当中,actor-critic methods 是为了保持当前的兴趣,由于两个特别明显的优势:
1.他们需要最小的计算量来达到选择动作的目的.考虑一种情况,有许多有限的可能的选择---例如,一个 continuous-valued action.任何方法仅仅学习动作值(action values)必须搜索这个有限的结合,从而实现选择 action 的目的.如果该policy是显示的存储的,接着,对于每一个动作选择可能不需要如此的计算量.
2.他们可以学习一个显示的随机策略;即,他们可以学习选择不同 actions 的最优概率.这个能力被证明在竞争和non-Markov cases 是非常有效的.
此外,在 actor-critic methods 不同的 actor 会使得他们在一些领域更有吸引力,如:生物模型.在一些领域中,可能也更加简单的在允许的策略结合上进行特定领域的约束.
11.2 Eligibility Traces for Actor-Critic Methods

 浙公网安备 33010602011771号
浙公网安备 33010602011771号