论文笔记之:Continuous Deep Q-Learning with Model-based Acceleration
Continuous Deep Q-Learning with Model-based Acceleration
本文提出了连续动作空间的深度强化学习算法。
开始正文之前,首先要弄清楚两个概念:Model-free 和 Model-based。引用 周志华老师的《机器学习》中的一段话来解释这个概念,即:
Model-based learning:机器已对环境进行了建模,能够在机器内部模拟出与环境相同或者近似的状况。在已知模型的环境中学习称为“有模型学习”,也就是这里讲的 model-based learning。此时,对于任意状态 x,x' 和 动作 a,在状态 x 下执行 动作 a 转移到 状态 x' 的概率p 是已知的,该转移所带来的奖赏 R 也是已知的。
那么,于此相对应,就是 Model-free learning。
那么什么是:on-policy 什么是:off-policy ?
我们知道一个策略的好坏需要进行评估,然后对学习到的比较差的策略,需要进行改进,完善。那么问题来了,如果说被评估和被改进的是同一个策略,那么就是属于:on-policy,否则,如果 被评估 和 被改进的不是同一个策略,则是属于 off-pocicy。
那么我们就想问?哪个比较好?为什么说 策略评估 和 策略改进不是同一个策略 ??
恩 这个问得好!答案是: 。 。 。
Model-free RL 已经成功的应用于许多具有挑战性的问题,最近也被拓展去处理大型神经网络策略和值函数。但是,model-free 算法的样本复杂性,特别是当使用高维的函数估计时,使其应用范围局限在物理系统中。本文,探索了一种新的在连续控制任务上降低样本复杂性的探索算法 和 表示。提出了两种互补性的技术来改善该算法的效率。首先,我们提出一个连续的Q-learning algorithm 的变种,并且命名为:Normalized adantage function (NAF),来替换经常使用的 策略梯度 和 actor-critic methods。NAF 允许我们利用 Q-learning 和 经验回放来处理连续的任务,并且在模拟的机器人控制任务上提升了性能。为了进一步的提升我们算法的效率,本文探索了利用学习到的模型来加速 model-free RL 的过程。
引言部分:
Model-free RL 已经成功的应用于一系列的具有挑战性的问题上。并且已经拓展到大型的神经网络和策略值函数上,这使得直接将原始表态表示作为输入传给神经网络,来训练策略对付复杂的任务。但是,model-free 算法的样本复杂性,特别是当使用高维的函数估计时,使其应用范围局限在物理系统中。在这种情况下,选择有效的 model-free algorithms 使用更加合适的,特定任务的表示,以及 model-based algorithms 来用监督学习的方法来学习系统的模型,并且在该模型下进行策略的优化。利用特定任务的表示显著的改善了效率,但是限制了能够从更加广泛的 domain 知识上学习和掌握的任务的范围。利用 model-based RL 能够改善效率,但是约束了策略只是和学习到的 model 一样好。在许多实际任务上,去表示一个好的策略 可能比 学习一个好的model 更加容易。所以,通过降低样本的复杂性,改善 model-free DRL 的泛化能力到实际 domains。
本文提出了两个互补性的技术来改善 DRL 在连续控制领域的效率:
1. 提出 Q-learning 的变种,适用于连续领域;
2. 结合 连续的 Q-learning 和 学习到的模型,来加速学习的过程。
除了提出一种改善的 model-free DRL 算法之外,本文也结合了 model-based RL 来加速学习过程,而没有扔掉 model-free 方法的优势。
一种方式是:对于 off-policy 算法,例如:Q-learning 结合由一个 model-based planner 产生的 off-policy experience。但是,这个解是自然的一个,我们经验评价表明这没法有效的加速学习。就像我们在评价中讨论的那样,这部分是由于 值函数估计算法的本质问题,必须要经历好的和坏的状态转移来准确的对值函数进行建模。我们提出了另一种方法来结合学习的模型到我们的连续动作 Q-learning 算法,基于 imagenation rollouts:
on-policy samples generated under the learned model, analogous to the Dyna-Q method.
本文的创新点有:
1. 我们得到和评价一个 Q-function表示,可以进行有效的连续 domains 的Q-learning;
2. 我们评价几个 naive 的方法来融合学习到的模型 和 model-free Q-learning,但是表明在我们连续控制任务上几乎没有影响;
3. 我们提出将 局部线性模型 和 局部 on-policy imagination rollouts 来加速 model-free 连续的 Q-learning,并且表明这个操作在样本复杂性上产生了巨大的改善。
Background:
Model-Free Reinforcement Learning
当 system dynamics $p(x_{t+1}|x_t, u_t)$ 是未知的,就像实际系统当中,如机器人中经常遇到的。Off-policy 算法利用值或者 Q-函数估计原则上可以达到很好的数据效率,但是,采用这种方法在连续的任务上通常需要在不同的目标上优化两个函数估计。我们不采用标准的 Q-learning,因为其只有一个目标。本节总结下 Q-learning,此粗略的介绍下,有需要请看原文。
Q-learning 的目标就是在一个状态下,选择一个动作 a,使得得到的奖赏最大化,即:
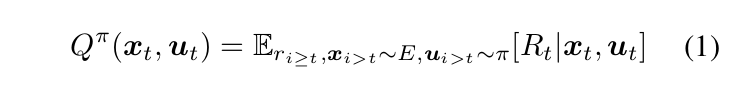
上面这个公式就是 Q 函数,学习的目标就是最小化 Bellman error,我们固定 目标 $y_t$:
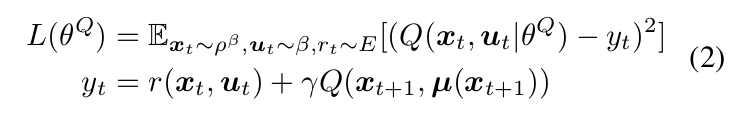
其中,这个就是和神经网络结合之后的产物,将下一个时刻的最大化的Q值作为要学习的目标,也可以看做是监督学习当中的 label。
对于连续动作问题, Q-learning 就变得困难了,因为每次迭代它都需要最大化一个复杂的 非线性的函数。
就是由于这个原因,连续领域经常利用 actor-critic methods 来解决,除了要学习 Q 函数 或者 值函数“critic”,还需要学习一个额外的参数化的 “actor”策略 $\pi$,如:DDPG 算法。
为了描述我们的方法,此处也定义 在给定策略 $\pi$之后,值函数 V 和 优势函数 A:

Model-based Reinforcement Learning :
。 。 。
4. Continuous Q-learning with Normalized Advantage Functions :
我们首先提出一种简单的方法来使得 Q-laarning 可以在连续动作空间和深度神经网络相结合,此处称为:Normalized Advantage Functions(NAF)。归一化优势函数(Advantage Function)背后的 idea 是为了表示 Q-learning 当中的 Q-function Q(xt, ut),使得 其最大值可以在Q-learning 更新的过程中简单,且有理有据的决定。
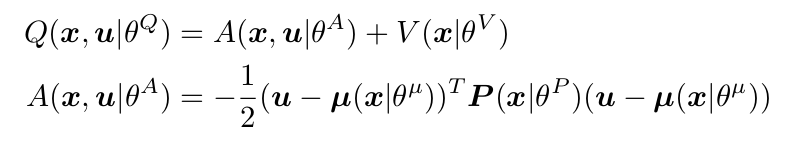
将 Q 值分解为 两项,即: advantage term A 和 state-value term V 其实早在 1993 和 1996 年救被人提出来了,只是最近 ICML 2016 的 Best Paper 又将其在离散的动作问题上进行了探索。
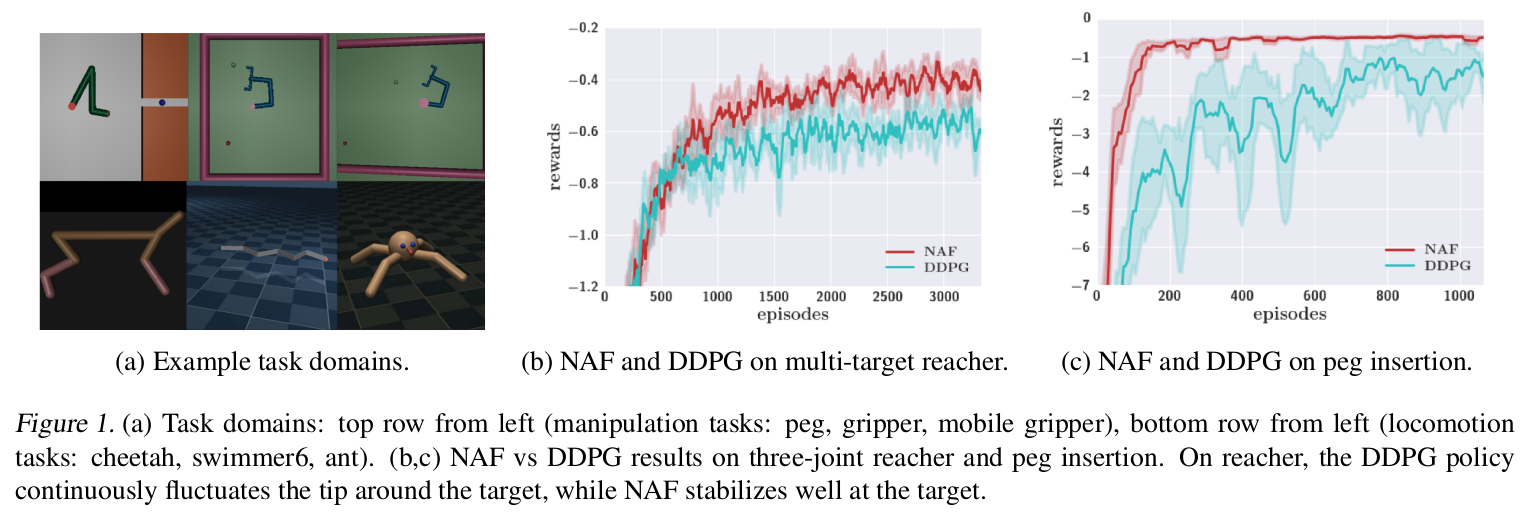
本文的初始算法流程总结如下:

our method is the first to combine such representations with deep neural networks into an algorithm that can be used to learn policies for a range of challenging continuous control tasks.
本文是第一个将 动作值函数和深度学习网络 融合进一个算法,并且将其用于学习策略,从而实现应用在连续控制任务上。
算法理解:
随机的初始化归一化的 Q network ;
利用上述初始化的 Q network 来初始化目标网络 Q' ;
初始化 回放容器(replay buffer)R ;
对于 episode 1:M
初始化一个随机过程 $\mathcal{N}$ 来进行动作的探索;
接收初始观测状态 x1~p(x1);
对于 t = 1:T
选择一个 action $ u_t $;
执行该动作,观察得到的奖赏 r_t 和 转移后的状态 $x_{t+1}$;
在回放容器 R 中存储 transitions $(x_t, u_t, r_t, x_{t+1})$;
对于迭代次数 = 1:I ,
从回放单元 R 中随机的抽取一个由 m 个 transitions 得到的 minibatch;
设置 ![]() ; ---> 设置目标或者讲是:label
; ---> 设置目标或者讲是:label
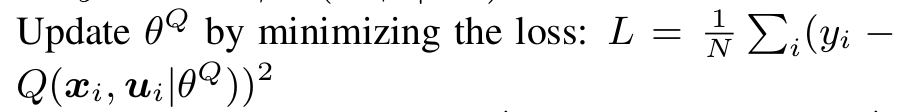 ---> 相当于是在训练网络结构的参数;
---> 相当于是在训练网络结构的参数;
更新目标网络 ![]() ;
;
5. Accelerating Learning with Imagination Rollouts
NAF 展现出在连续控制领域,对比 actor-critic model-free RL 方法的优势,但是结合已经学习到的 model,在一些额外假设的条件下,可以改善数据的有效性(Improve data efficiency)。我们将表明将特定类型的学习到的model 结合到 带有 NAF 的Q-learning 算法当中,可以改善 sample efficiency;而与此同时,用 model-free learning 可以微调 final policy 达到较好的效果。
5.1. Model-Guided Exploration
一个很直观的方法来结合学习到的 model 到 一个 off-policy 算法当中,就是利用学习到的 model 通过规划(planning)或者轨迹优化(trajectory OPtimization)来产生好的探索行为。为了评价这个 idea,我们利用了 iLQG 算法在该模型的基础上来产生好的轨迹,然后将这些轨迹 和 replay buffer 混合在一起。但是有意思的是,即使在 真正的model下进行 planning,用这种方法得到的提升也是很小的。导致这种结果的潜在直觉是:off-policy iLQG 探索和学习到的策略大不相同,而 Q-learning 必须要考虑到不同,为了弄清楚给定动作的优越性。也就是说,只展示给算法 good actions 使不够的,而必须也让其经历 bad actions 来彻底的理解哪些动作更好 或者 哪些更坏。
5.2 Imagition Rollouts
上述结果表明:Q-learning 基于最小化时间差来学习一个策略,需要有噪声的 on-policy actions 来继承。
基于学习到的 model 产生合成的 on-policy trajectories ,加上这些合成的样本到 replay buffer,(我们称为: imagination rollouts)来增强 Q-learning 可用经验的数量。我们使用的特定方法是利用混合的 planned iLQG trajectories 和 on-policy trajectories 在实际世界中执行 rollouts, 然后 我们利用学习到的 model 产生额外的合成 on-policy rollouts。这种方法可以看做是 Dyna-Q algorithm的一个变种。但是 Dyna-Q 主要用来处理小的 离散的系统,利用迭代的 refitting 线性模型允许我们拓展该方法到 DRL 的连续控制领域(continous control domains)。在一些场景中,我们甚至可以产生所有后者大部分的实际 rollouts,这里用的是 off-policy iLQG controllers,这在 safety-critic domains 是非常关键的,因为残缺的训练策略可能会采取危险的actions。

知乎上“DQN 从入门到放弃系列”:
DQN从入门到放弃7 连续控制DQN算法-NAF
1 前言
在上一篇文章DQN从入门到放弃6 DQN的各种改进中,我们介绍了DQN的各个方面的改进。从各种改进的角度和思路很有利于我们思考如何去创新这个事情。那么,本着从入门到放弃的精神[呲牙],在今天这篇文章中,我们还是来分析一下将DQN拓展到连续控制的算法------NAF。
2 DQN算法用在连续控制上存在的问题
从之前对DQN的分析,大家已经知道,DQN是一个面向离散控制的算法,也就是说输出的动作是离散的,不是连续的。这里也单独说一下离散控制和连续控制。这可以认为是增强学习任务的一种分类方法。那么一开始在没有引入深度学习的情况下,增强学习的任务基本是面向低维输入,低维输出的问题,因为高维的问题难度实在是太大,很难收敛。那么,DQN,引入了深度学习,使得输入可以拓展到高维空间,比如玩Atari,完全图像输入,维度是80x80=6400维,但是玩Atari的输出只是离散的键盘按键输出,比如Breakout这个游戏,也就是4个输出。而如果问题换成一个机械臂的控制呢?假设有6个关节,然后每个关节的扭矩输出是连续值,也就是在一个范围内任意取值,比如(-1,1)。那么,即使把每一个输出离散化,比如精度到0.01,那么一个动作有200个取值,那么6个关节也就是1200个取值,这比4个输出大得多。更何况如果进一步提升这个精度,那么取值的数量就成倍增加了。这就是连续控制比离散控制难得多的地方。
那么DQN为什么没办法直接用在连续控制上呢?原因很简单,DQN依靠计算每一个动作的Q值,然后选择最大的Q值对应的动作。那么这种方法在连续控制上完全不起作用。因为,根本就没办法穷举每一个动作,也就无法计算最大的Q值对应的动作。
所以,问题也就来了:
如何将DQN拓展成能够用在连续控制上的深度增强学习算法?
3 Continuous Deep Q-Learning with NAF
http://arxiv.org/abs/1603.00748
在上面这篇Paper中,作者提出了一种idea来实现连续控制。基本思路是这样的:
Step 1:在DQN的框架下,连续控制的输出需要满足什么条件?
因为DQN是通过计算Q值的最大值来选择动作。那么对于连续控制,我们已经无法选择动作,我们只能设计一种方法,使得我们输入状态,然后能够输出动作,并且保证输出动作对应的Q值是最大值。
Step 2:又要输出动作,又要输出Q值?
第一步的分析我们会发现一个两难的境地,就是我们输入状态,输出的时候,既要能输出动作,还要能输出Q值。那么这个时候,我们有两种选择,一种就是弄两个神经网络,一个是Policy网络,输入状态,输出动作,另一个是Q网络,输入状态,输出Q值。另外一种就是弄一个神经网络,既输出动作,有能输出Q值。先说第一种做法。这种做法其实就是Actor-Critic算法的做法。这种做法需要能够构建一个能够更新Policy网络的方法。而DQN并没有提供更新Policy网络的方法。这使得我们要基于DQN做文章,只有一个办法,就是只弄一个神经网络,既能输出动作也能输出Q值。But,how?
Step 3:如何构建神经网络,又能输出动作,也能输出Q值,而且动作对应的Q值最大?
这个问题确实是很困难的一个问题,很难直接就想出一个好的做法。虽然在Paper中作者其实只用了一段话来说明他们的方法,但是确实是很酷的idea。先提一下这些作者Shixiang Gu, Timothy Lillicrap, Ilya Sutskever, Sergey Levine 后面两个都很牛。然后我们还是直接分析他们提出的方法吧!
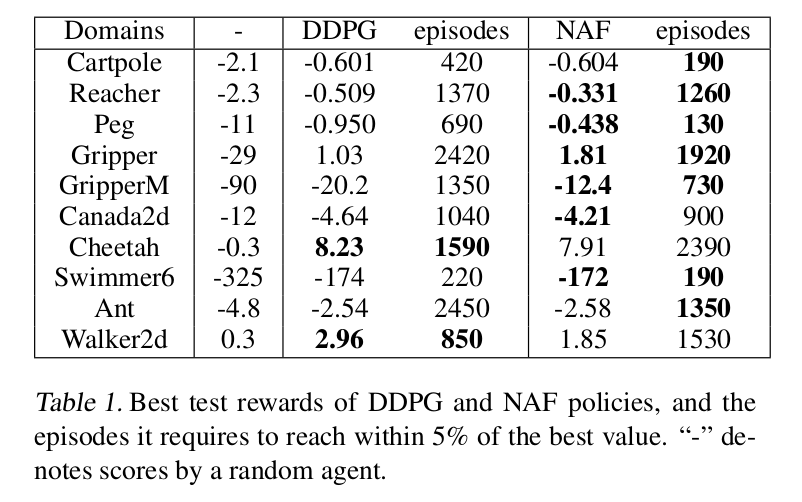
 上图就是这个方法的示意图了。输入输出关系非常复杂。正常简单的Q网络就是200relu之后直接输出Q,但是这里经过很多复杂的步骤之后才输出Q。
上图就是这个方法的示意图了。输入输出关系非常复杂。正常简单的Q网络就是200relu之后直接输出Q,但是这里经过很多复杂的步骤之后才输出Q。
基本的idea就是引入了Advantage,也就是每一个动作在特定状态下的优劣。我们不是要选最优的动作吗?其实就是要选Advantage最大的动作。Q,A(Advantage)和V(Value)的关系如下:
所以,核心idea来了:如果我们能够限制A小于等于0,并且选择的动作对应的A为0,那么问题就解决了。要做到这点,一种简单的想法就是让
P为正
也就是二次方程取负。这个时候当a=x即选择的动作时为0.
那么具体构建当然是用矩阵的方式来构建。只是显然复杂的多。
state经过两个200层的神经网络(包含非线性)后分别构建三个分力的全连接层,输出Value,mu(动作)还有构建矩阵P所需的L0。也就是同时输出了价值还有动作
那么最大的问题就是如何构造A的矩阵表示了。
 上式是A的矩阵表示,也就是一个二次型。其中x是状态,u是动作,mu是神经网络的输出动作。
上式是A的矩阵表示,也就是一个二次型。其中x是状态,u是动作,mu是神经网络的输出动作。
那么令,也就是
即
要满足这个要求,P必须为正定矩阵。这本身也就是正定矩阵的定义。
接下来就是如何构造P的问题了。
这里作者竟然采用了乔列斯基(Cholesky)分解:
若A为n阶对称正定矩阵,则存在唯一的主对角线元素都是正数的下三角阵L,使得,此分解式称为 正定矩阵的乔列斯基(Cholesky)分解。
也就是构造了一个对角线元素都是正数的下三角阵L,然后利用L构造P。
---------------------------------------------------------------------------------------
上面的分析确实是有点复杂。
那么我们再回到上面那个神经网络流程图来具体看看神经网络具体是怎么处理的?
1)State,维度是输入维度state_dim
2) 经过两个200的RELU全连接层
3)输出V,维度为1
4)输出mu(动作),维度为动作的维度action_dim
5)输出L0,维度为(action_dim)x(action_dim+1)/2,也就是构造下三角矩阵L所需要的维度
6)构造L。将L0转化为L.也就是将一个列向量转换为下三角矩阵,就是从新排列,然后把对角线的数exp对数化。
7)根据L构造P。
8)根据mu,P,action构造A
9)根据A和V构造Q,也就是Q=A+V
综上,最终输出Q,并且可以根据DQN的方法进行梯度下降。
 以上就是这个算法的整个过程。
以上就是这个算法的整个过程。
3 小结
这个算法确实设计精美,但实现起来其实蛮复杂。未来需要有更多的改进!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号