
论文笔记之:Multiple Object Recognition With Visual Attention
Multiple Object Recognition With Visual Attention
Google DeepMind ICRL 2015
本文提出了一种基于 attention 的用于图像中识别多个物体的模型。该模型是利用RL来训练 Deep RNN,以找到输入图像中最相关的区域。尽管在训练的过程中,仅仅给出了类别标签,但是仍然可以学习定位并且识别出多个物体。
Deep Recurrent Visual Attention Model
文中先以单个物体的分类为基础,再拓展到多个物体的情况。用基于attention的模型来处理一张图像 x 是有N steps的序列处理问题,每一个step是由扫视构成的,然后紧跟着是 glimpse。在每一个step n 中,该模型从一个 glimpse observation $x_n$ 接收到位置信息 $l_n$。模型利用该 observation 来更新自身的状态,并且输出下一个 time-step的位置$l_{n+1}$。通常情况下,一个 glimpse $x_n$的像素点个数都会比原始图像x要小很多,使得处理一个glimpse的计算代价独立于原始图像的大小。
模型的图形化表示如图所示:
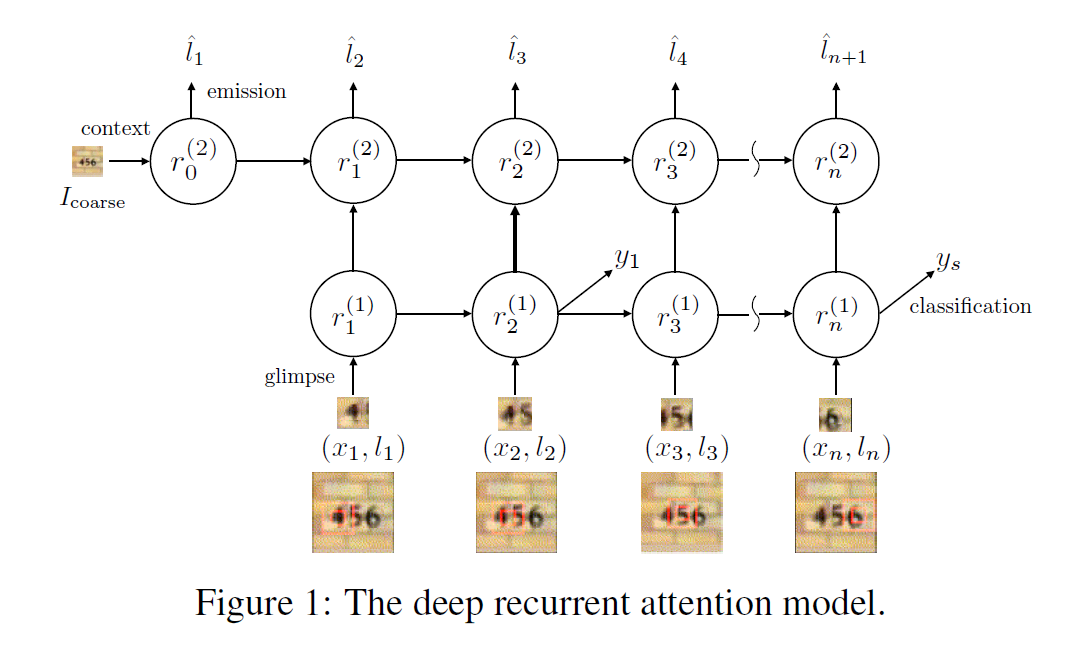
该模型可以分解成多个子成分,即:每一个都将输入输出成向量。
Glimpse Network
该网络是一种非线性函数,接收当前输入的图像patch或者说是 glimpse,$x_n$,以及其位置序列$l_n$,其中$l_n = (x_n, y_n)$作为输入,输出一个向量$g_n$。Glimpse Network 的工作就是从原始图像中从位置$l_n$附近提取一组有用的特征。利用$G_{image}(x_n|W_{image})$来表示函数$G_{image}(*)$ 的输出向量,$G_{image}(*)$的输入是图像patch $x_n$,然后以权重$W_{image}$参数化,$G_{image}(*)$ 通常由三个卷积隐层构成,没有pooling layer,然后紧跟着一个全连接层。另外,$G_{loc}(l_n|W_{loc})$利用全连接的隐层来映射出位置元组,$G_{loc}(l_n|W_{loc})$ 和 $G_{image}(x_n|W_{image})$ 拥有相同的维度。我们将这两个向量进行点乘操作得到最终的 glimpse feature vector $g_n$:
$g_n = G_{image}(x_n|W_{image} G_{loc}|W_{loc})$.
Recurrent Network
RN 汇聚从每一个glimpse上提取的信息,并且以一种 coherent manner 组合起来以保存空间信息。从 glimpse Network 得到的glimpse feature vector $g_n$ 作为每一个时刻 RN的输入。RN 由两个循环层和非线性函数 $R_{recur}$构成,定义两个 recurrent layer的输出为$r^{(1)}$ and $r^{(2)}$ :
$r^{(1)} = R_{recur}(g_n, r_{n-1}^{(1)}|W_{r1})$ and $r^{(2)} = R_{recur}(g_n, r_{n-1}^{(2)}|W_{r2})$
我们用LSTM单元来处理非线性$R_{recur}$,因为其具有学习长期依赖(long-range dependencies)和稳定的学习动态(stable learning dynamics)的能力。
Emission Network (放射网络?)
该网络将RN 当前的状态作为输入,然后预测出 glimpse network 应该向何处提取图像patch。这个就像一个指挥中心,从 RN 中基于当前的内部状态,控制着 attention。由一个全连接隐层构成,将feature vector $r_n^{(2)}$从recurrent layer的顶部映射成坐标元组$l_{n+1}$:

Context Network
Context Network 提供了 RN的输出状态,其输出用于 emission Network 来预测第一个glimpse的位置。Context Network $C(*)$ 将下采样的图像 $I_{coarse}$作为输入,并且出书一个固定长度的向量 $c_I$。该结构信息提供了一个可见的提示,即:所给图像潜在的感兴趣区域的位置。采用三个卷积层将粗糙的图像 $I_{coarse}$ 映射成特征向量作为 RN 的top recurrent layer $r^2$ 的初始状态。底层 $r^1$初始化为零向量,原因后面会具体介绍。
Classification Network
分类网络基于底层RN的最终的特征向量 $r_N^{(1)}$预测出一个类别标签 y。由一个全连接隐层和softmax 输出层构成:
$P(y|I) = O(r_n^1|W_o)$
理想情况下,深度循环attention model 应该学习去寻找对分类物体相关的位置。Contextual information的存在,提供了一个“short cut”的解决方案,使得模型通过组合不同glimpse的信息从而更加容易学习到Contextual information。我们阻止如此不想要的行为,通过链接 context network and classification network 到不同的 recurrent layer。所以,最终使得contextual information 不能被直接用于 classification network,然后只影响模型产生的glimpse locations序列。
1. Learning Where and What ?
给定一张图像 I 的类别标签 y,我们可以利用交叉熵目标函数,将学习过程规划为 有监督分类问题。attention model 基于每一个 glimpse 得到潜在的位置变量 l,然后提取出对应的patches。所以我们可以通过忽略 glimpse locations 来最大化 类别标签的似然性 :
$log p(y|I, W) = log\sum_l p(l|I,W)p(y|l, I, W)$。
忽略的目标函数可以通过其 variational free energy lower bound F 来学到:

将上述函数求关于模型参数W的导数,可以得到学习的规则:
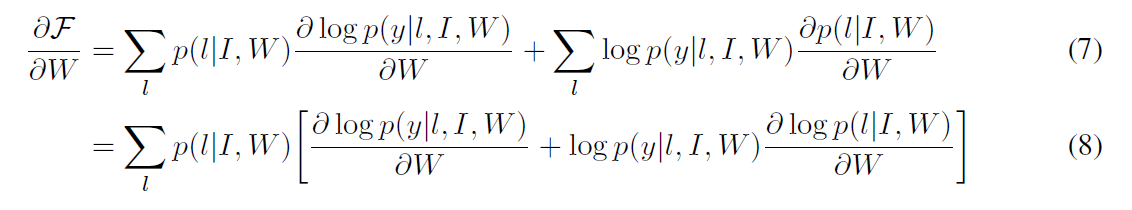
在glimpse 序列中的每个glimpse,很难在训练中估计许多成指数式glimpse locations。公式(8)的和可以利用蒙特卡罗采样(Monte Carlo Samples)的方法来进行估计:

公式(10)提供了一种实际的算法来训练深度attention model。即,在每次glimpse之后,我们从模型中预测出的glimpse location中进行采样。这些样本然后用于标准的后向传播来得到当前模型参数的估计。似然性 $log p(y|l^m, I, W)$ 有一个 unbounded range,可以在梯度估计中引入大量的 high variance。特别是,当图像中采样的位置偏离物体时,log 似然性会引入 一个不想要的较大的梯度更新,并且通过剩下的模型进行后向传播。
我们可以减小公式(10)中的 variance, 通过将 $log p(y|l^m, I, W)$ 替换为 0/1离散指示函数 R,然后利用一个baseline technique 来解决该问题:

像所展示的那样,recurrent network state vector $r_n^{(2)}$ 用来估计每一个glimpse 基于状态的baseline $b$,此举明显的改善了学习的效率。该baseline 有效地中心化了随机变量 R,并且可以通过向期望的R值进行回归而学习到。给定指示函数和baseline,我们有如下的梯度更新:

其中,超参数 $\lambda$ 平衡了两个梯度成分的尺度。实际上,通过利用 0/1指示函数,公式13的学习规则就等价于 利用强化学习的方法来训练attention model。当看作是强化学习更新时,公式13的第二项就是基于glimpse policy的期望奖励 R的对应W的梯度无偏估计。此处有点绕人,看原文吧:the second term in equation 13 is an unbiased estimate of the gradient with respect to W of the expected reward R under the model glimpse policy。
在推理的过程中,前馈位置估计可以用作位置坐标的决策性估计,以此提取模型下一个输入图像patch。该模型表现的像一个常规的前馈网络。我们的 marginallized objective function equation 5 通过利用位置序列的采样,提供了一个预测期望的类别估计,并且对这些估计进行平均:
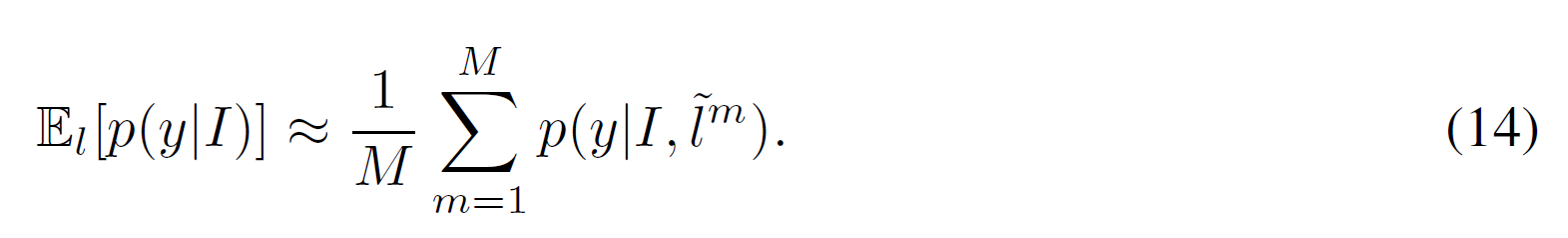
通过平均分类估计,这允许attention model 可以多次评价。作者的实验表明平均 log 概率可以得到最优的性能。
2. Multi-Object/Sequential Classification as a Visual Attention Task
3. 实验部分:
这里只是给出部分贴图,具体参考文章原文。

文中给出了两个数据集上的结果。从上图可以看出,最左边是输入图像,右边5列分别是学到的 glimpse location。此处有一个trick,即:对于glimpse network 有两种尺寸可以提升性能。即,给定一个 glimpse location $l_n$,可以提取两个patch,第一个是 original patch,第二个是 下采样的粗糙的 image patch,将这两个patch 组合在一起即可。
我的感受:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号