论文笔记之:Attention For Fine-Grained Categorization
Attention For Fine-Grained Categorization
Google ICLR 2015
本文说是将Ba et al. 的基于RNN 的attention model 拓展为受限更少,或者说是非受限的视觉场景。这个工作和前者很大程度上的不同在于,用一个更加有效的视觉网络,并且在attention RNN之外进行视觉网络的预训练。
前人的工作在学习 visual attention model 时已经解决了一些计算机视觉问题,并且表明加上不同的attention mechanisms 可以有效的提升算法的性能。但是之前的工作基本都是受限的环境或者基于玩具这种数据集,本文的算法可以处理更加具有挑战性的因素,如:遮挡等更加复杂的场景。下面这个数据集就给出了案例:

本文模型框架主要来源于“ Multiple Object Recognition with Visual Attention ”,大体上是一直的,主要有一下几点不同:
1. our model chooses actions for N glimpses and then classifies only after the final glimpse, as opposed to the sequence task in Ba et al. 每一个实验当中 glimpse的个数是固定的。
2. 因为数据集中的图像是不断变化的,那么“foveal” glimpses patches 的大小和输入图像最短边的比例保持一致。
3. 用“vanilla” RNN 来代替 LSTM,在 glimpse n 处,$r_n^{(1)}$ and $r_n^{(2)}$ 都由4096个点构成,当$i =1, 2$时,$r_n(i)$ 和 $r_{n+1}(i)$ 是全连接的。
4. 本文并非将 glimpse visual core $G_{image}(x_n|W_{image})$ and $G_{loc}(l_n|W_{loc})$的输出进行元素级相乘,而是将其输出进行concatenate实现线性组合,然后使其通过一个全连接层。
最后,然后是最大的不同之处在于:将visual glimpse network $G_{image}(x_n|W_{image})$ 替换为 基于"GoogleLeNet" model的更加强大且有效的视觉核心(visual core)。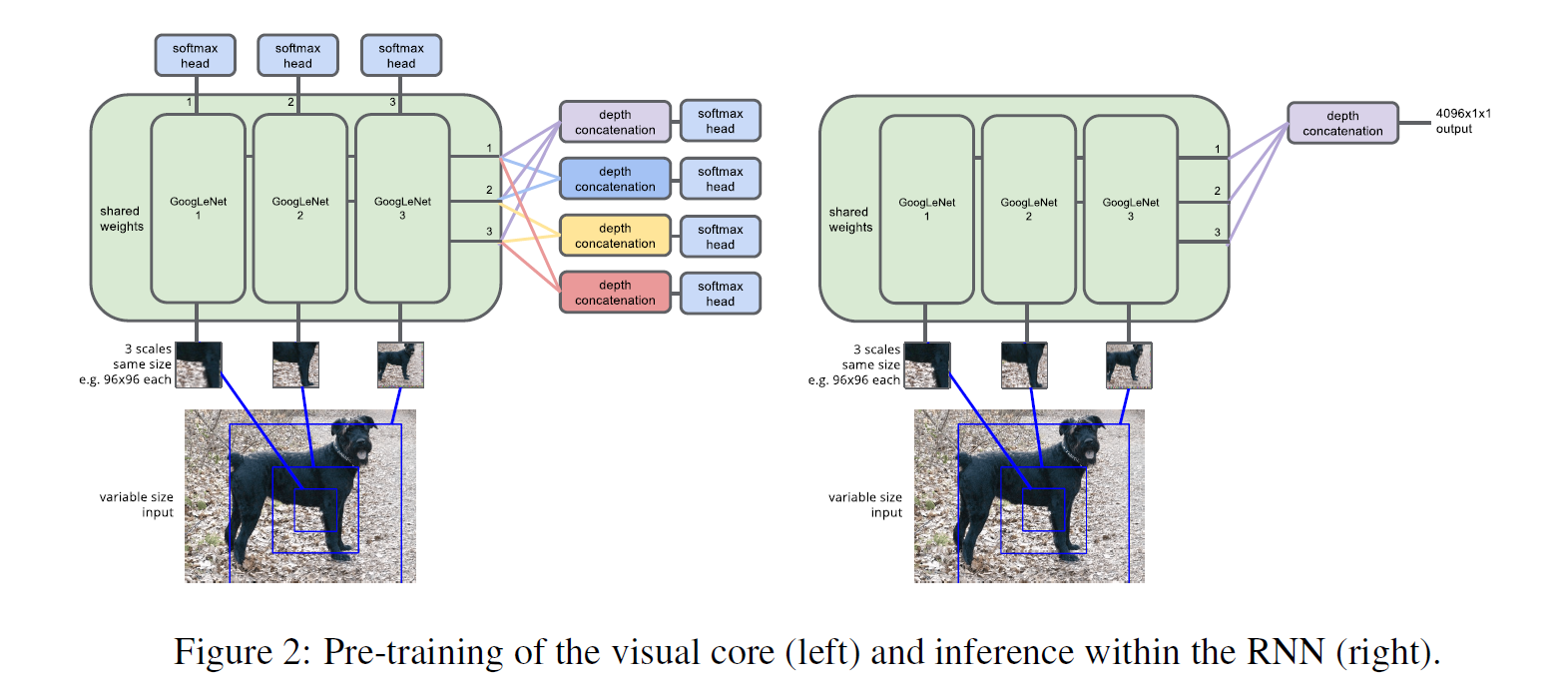
由于是基于他人的框架,所以本文对模型方面的介绍较少,我待会回去解释下那个引用的文章,结合那篇文章,来理解这个paper。
留下空白页,谈谈自己的感受:
我先去看看那个文章,回头再补回来!等我!!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号