利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
数据的组织格式为:
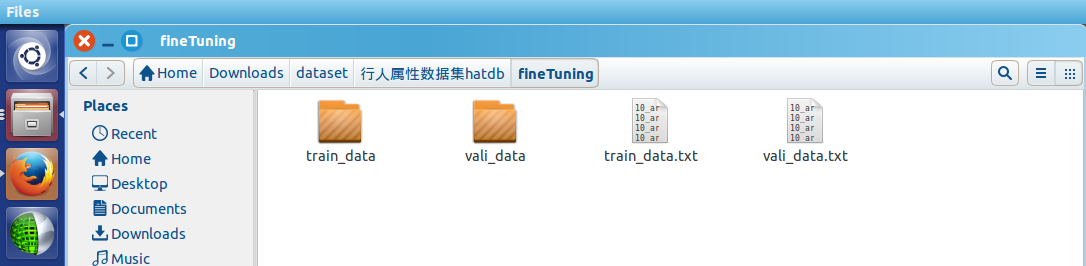
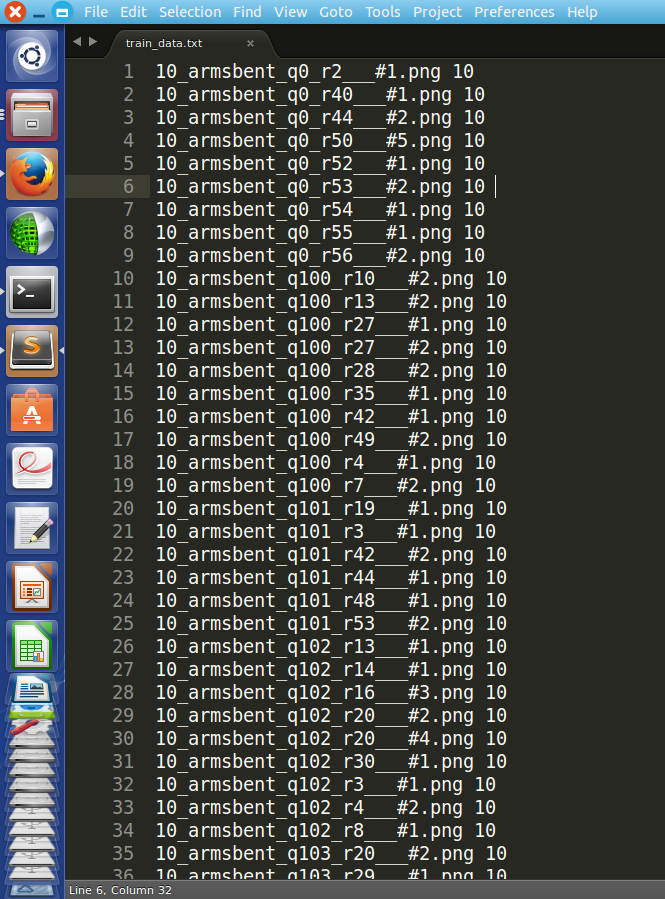
首先,所需要的脚本指令路径为:
/home/wangxiao/Downloads/caffe-master/examples/imagenet/
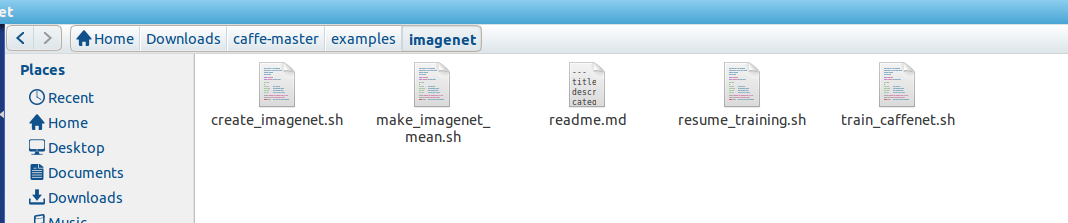
其中,生成lmdb的文件为: create_imagenet.sh
接下来的主要任务就是修改自己的data的存放路径了。
1 #!/usr/bin/env sh
2 # Create the imagenet lmdb inputs
3 # N.B. set the path to the imagenet train + val data dirs
4
5 EXAMPLE=../wangxiao
6 DATA=../fine_tuning_data
7 TOOLS=../build/tools
8
9 TRAIN_DATA_ROOT=../fine_tuning_data/training/data/
10 VAL_DATA_ROOT=../fine_tuning_data/validation/data/
11
12 #TRAIN_DATA_ROOT=/media/yukai/247317a3-e6b5-45d4-81d1-956930526746/---------------/Attribute reconginition/final_PETA_dataset/whole_benchmark/用于微调网络的数据/training/data/
13 #VAL_DATA_ROOT=/media/yukai/247317a3-e6b5-45d4-81d1-956930526746/---------------/Attribute reconginition/final_PETA_dataset/whole_benchmark/用于微调网络的数据/validation/data/
14
15 # Set RESIZE=true to resize the images to 256x256. Leave as false if images have
16 # already been resized using another tool.
17
18 # RESIZE=false default parameter and wangxiao modify it in 2015.10.13 1:25
19
20 RESIZE=true
21 if $RESIZE; then
22 RESIZE_HEIGHT=256
23 RESIZE_WIDTH=256
24 else
25 RESIZE_HEIGHT=0
26 RESIZE_WIDTH=0
27 fi
28
29 if [ ! -d "$TRAIN_DATA_ROOT" ]; then
30 echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
31 echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
32 "where the ImageNet training data is stored."
33 exit 1
34 fi
35
36 if [ ! -d "$VAL_DATA_ROOT" ]; then
37 echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
38 echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
39 "where the ImageNet validation data is stored."
40 exit 1
41 fi
42
43 echo "Creating train lmdb..."
44
45 GLOG_logtostderr=1 $TOOLS/convert_imageset \
46 --resize_height=$RESIZE_HEIGHT \
47 --resize_width=$RESIZE_WIDTH \
48 --shuffle \
49 $TRAIN_DATA_ROOT \
50 $DATA/training/final_train_data.txt \
51 $EXAMPLE/PETA_train_lmdb
52
53 #echo "Creating val lmdb..."
54
55 #GLOG_logtostderr=1 $TOOLS/convert_imageset \
56 # --resize_height=$RESIZE_HEIGHT \
57 # --resize_width=$RESIZE_WIDTH \
58 # --shuffle \
59 # $VAL_DATA_ROOT \
60 # $DATA/validation/final_test_data.txt \
61 # $EXAMPLE/PETA_val_lmdb
62
63 echo "Done."
都修改完成后,在终端执行:create_imagenet.sh,然后会有如此的提示,表示正在生成lmdb文件:
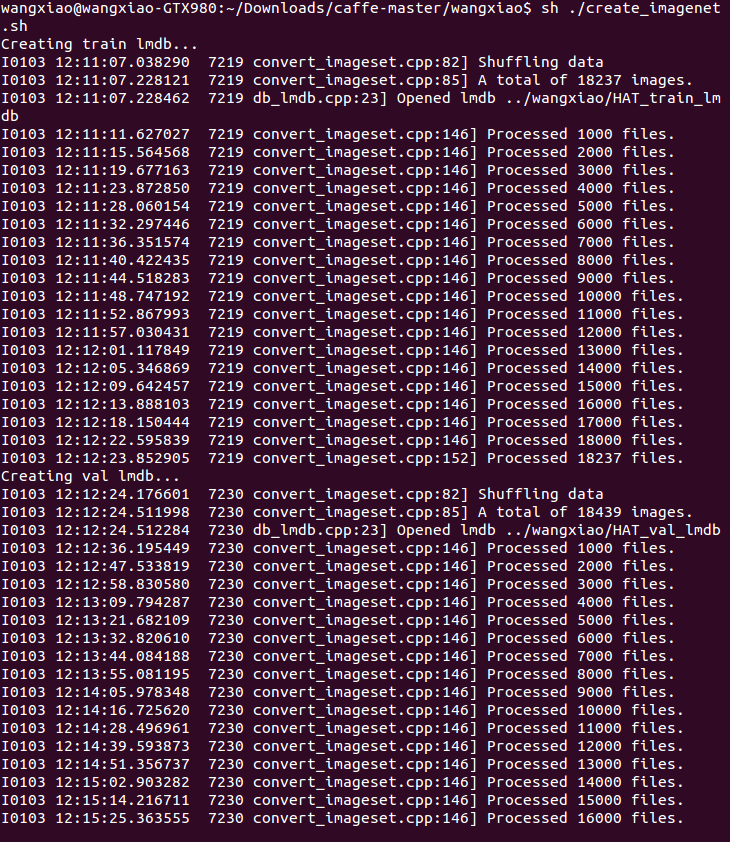
然后完成后,提示: Done. 然后可以看到已经生成了所需要的文件:

然后利用 make_imagenet_mean.sh 生成所需要的 mean file :
caffe-master$: sh ./make_imagenet_mean.sh
1 #!/usr/bin/env sh
2 # Compute the mean image from the imagenet training lmdb
3 # N.B. this is available in data/ilsvrc12
4
5 EXAMPLE=../wangxiao
6 DATA=./data
7 TOOLS=../build/tools
8
9 #echo $TOOLS/compute_image_mean $EXAMPLE/HAT_train_lmdb \
10 # $DATA/HAT_mean.binaryproto
11 $TOOLS/compute_image_mean $EXAMPLE/HAT_train_lmdb \
12 $DATA/HAT_mean.binaryproto
13 echo "Done."
然后就生成了 HAT_mean.binaryproto
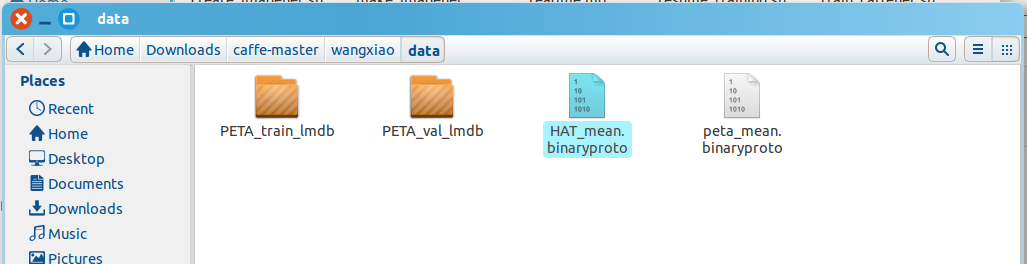
其中,caffe路径下:/home/wangxiao/Downloads/caffe-master/examples/imagenet/readme.md 对这个过程有一个详细的解释。
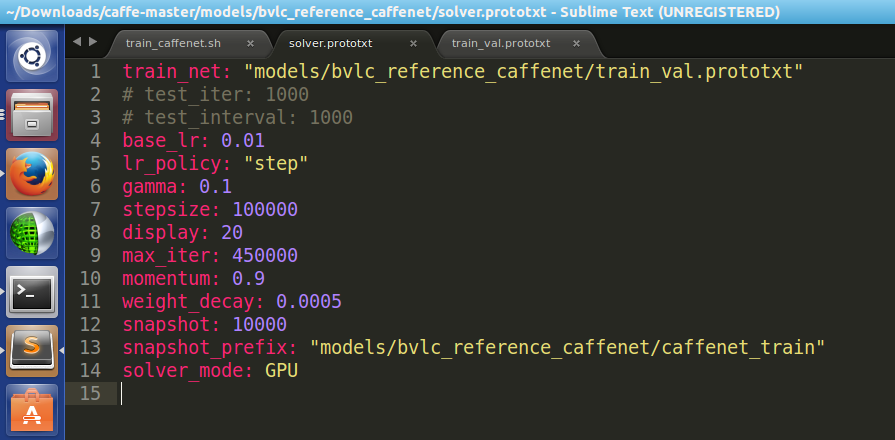
然后就是查看 solver.prototxt:

1 net: "models/bvlc_reference_caffenet/train_val.prototxt"
2 test_iter: 1000
3 test_interval: 1000
4 base_lr: 0.01
5 lr_policy: "step"
6 gamma: 0.1
7 stepsize: 100000
8 display: 20
9 max_iter: 450000
10 momentum: 0.9
11 weight_decay: 0.0005
12 snapshot: 10000
13 snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
14 solver_mode: GPU
打开 models/bvlc_reference_caffenet/train_val.prototxt
需要修改的也就到第55行:
1 name: "CaffeNet"
2 layer {
3 name: "data"
4 type: "Data"
5 top: "data"
6 top: "label"
7 include {
8 phase: TRAIN
9 }
10 transform_param {
11 mirror: true
12 crop_size: 227
13 mean_file: "wangxiao/HAT_data/HAT_mean.binaryproto"
14 }
15 # mean pixel / channel-wise mean instead of mean image
16 # transform_param {
17 # crop_size: 227
18 # mean_value: 104
19 # mean_value: 117
20 # mean_value: 123
21 # mirror: true
22 # }
23 data_param {
24 source: "wangxiao/HAT_data/HAT_train_lmdb"
25 batch_size: 256
26 backend: LMDB
27 }
28 }
29 layer {
30 name: "data"
31 type: "Data"
32 top: "data"
33 top: "label"
34 include {
35 phase: TEST
36 }
37 transform_param {
38 mirror: false
39 crop_size: 227
40 mean_file: "wangxiao/HAT_data/HAT_mean.binaryproto"
41 }
42 # mean pixel / channel-wise mean instead of mean image
43 # transform_param {
44 # crop_size: 227
45 # mean_value: 104
46 # mean_value: 117
47 # mean_value: 123
48 # mirror: true
49 # }
50 data_param {
51 source: "wangxiao/HAT_data/HAT_val_lmdb"
52 batch_size: 50
53 backend: LMDB
54 }
55 }
然后执行:
终端会有显示:
1 I0103 13:44:21.027832 9543 net.cpp:297] Network initialization done.
2 I0103 13:44:21.027839 9543 net.cpp:298] Memory required for data: 1757220868
3 I0103 13:44:21.027928 9543 solver.cpp:66] Solver scaffolding done.
4 I0103 13:44:21.028312 9543 caffe.cpp:212] Starting Optimization
5 I0103 13:44:21.028326 9543 solver.cpp:294] Solving CaffeNet
6 I0103 13:44:21.028333 9543 solver.cpp:295] Learning Rate Policy: step
7 I0103 13:44:22.012593 9543 solver.cpp:243] Iteration 0, loss = 7.52783
8 I0103 13:44:22.012660 9543 solver.cpp:259] Train net output #0: loss = 7.52783 (* 1 = 7.52783 loss)
9 I0103 13:44:22.012687 9543 solver.cpp:590] Iteration 0, lr = 0.01
10 I0103 13:44:41.812361 9543 solver.cpp:243] Iteration 20, loss = 3.9723
11 I0103 13:44:41.812413 9543 solver.cpp:259] Train net output #0: loss = 3.9723 (* 1 = 3.9723 loss)
12 I0103 13:44:41.812428 9543 solver.cpp:590] Iteration 20, lr = 0.01
13 I0103 13:45:01.553021 9543 solver.cpp:243] Iteration 40, loss = 2.9715
14 I0103 13:45:01.553104 9543 solver.cpp:259] Train net output #0: loss = 2.9715 (* 1 = 2.9715 loss)
15 I0103 13:45:01.553119 9543 solver.cpp:590] Iteration 40, lr = 0.01
16 I0103 13:45:21.574745 9543 solver.cpp:243] Iteration 60, loss = 2.91547
17 I0103 13:45:21.574798 9543 solver.cpp:259] Train net output #0: loss = 2.91547 (* 1 = 2.91547 loss)
18 I0103 13:45:21.574811 9543 solver.cpp:590] Iteration 60, lr = 0.01
19 I0103 13:45:41.247493 9543 solver.cpp:243] Iteration 80, loss = 2.96451
20 I0103 13:45:41.247627 9543 solver.cpp:259] Train net output #0: loss = 2.96451 (* 1 = 2.96451 loss)
21 I0103 13:45:41.247642 9543 solver.cpp:590] Iteration 80, lr = 0.01
22 I0103 13:46:00.941267 9543 solver.cpp:243] Iteration 100, loss = 2.85887
23 I0103 13:46:00.941318 9543 solver.cpp:259] Train net output #0: loss = 2.85887 (* 1 = 2.85887 loss)
24 I0103 13:46:00.941332 9543 solver.cpp:590] Iteration 100, lr = 0.01
25 I0103 13:46:20.628329 9543 solver.cpp:243] Iteration 120, loss = 2.91318
26 I0103 13:46:20.628463 9543 solver.cpp:259] Train net output #0: loss = 2.91318 (* 1 = 2.91318 loss)
27 I0103 13:46:20.628476 9543 solver.cpp:590] Iteration 120, lr = 0.01
28 I0103 13:46:40.621937 9543 solver.cpp:243] Iteration 140, loss = 3.06499
29 I0103 13:46:40.621989 9543 solver.cpp:259] Train net output #0: loss = 3.06499 (* 1 = 3.06499 loss)
30 I0103 13:46:40.622004 9543 solver.cpp:590] Iteration 140, lr = 0.01
31 I0103 13:47:00.557921 9543 solver.cpp:243] Iteration 160, loss = 2.9818
32 I0103 13:47:00.558048 9543 solver.cpp:259] Train net output #0: loss = 2.9818 (* 1 = 2.9818 loss)
33 I0103 13:47:00.558063 9543 solver.cpp:590] Iteration 160, lr = 0.01
因为设置的迭代次数为: 450000次,所以,接下来就是睡觉了。。。O(∩_∩)O~ 感谢木得兄刚刚的帮助。
------ 未完待续------

另外就是,当loss 后期变化不大的时候,可以试着调整学习率, 在Solver.prototext中:
1 train_net: "models/bvlc_reference_caffenet/train_val.prototxt"
2 # test_iter: 1000
3 # test_interval: 1000
4 base_lr: 0.0001
5 lr_policy: "step"
6 gamma: 0.1
7 stepsize: 100000
8 display: 20
9 max_iter: 450000
10 momentum: 0.9
11 weight_decay: 0.0005
12 snapshot: 10000
13 snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
14 solver_mode: GPU
base_lr: 0.0001 每次可以改为0.1×base_lr, 这里的 0.0001 是我两次调整之后的数值。
然后运行 resume_training.sh
1 #!/usr/bin/env sh
2
3 ./build/tools/caffe train \
4 --solver=models/bvlc_reference_caffenet/solver.prototxt \
5 --snapshot=models/bvlc_reference_caffenet/caffenet_train_iter_88251.solverstate
将snapshot改为之前中断时的结果即可,即: caffenet_train_iter_88251.solverstate
继续看loss是否降低。。。
--------------------------------- 未完待续 ---------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号