ActionCLIP: A New Paradigm for Video Action Recognition
ActionCLIP: A New Paradigm for Video Action Recognition
2022-07-02 17:38:37
Paper: 2109.08472.pdf (arxiv.org)
Code: https://github.com/sallymmx/ActionCLIP.git
Paper list: thunlp/PromptPapers: Must-read papers on prompt-based tuning for pre-trained language models. (github.com)
1. Background and Motivation:
一般来说,现有的视频分类方法都是采用的特征提取+分类的方式,将其看做是一个 1-N 的映射问题。本文从模态匹配(Modality-matching)的角度出发,将视频行为识别看作是一个对比学习问题。这两种学习范式可以归纳为:
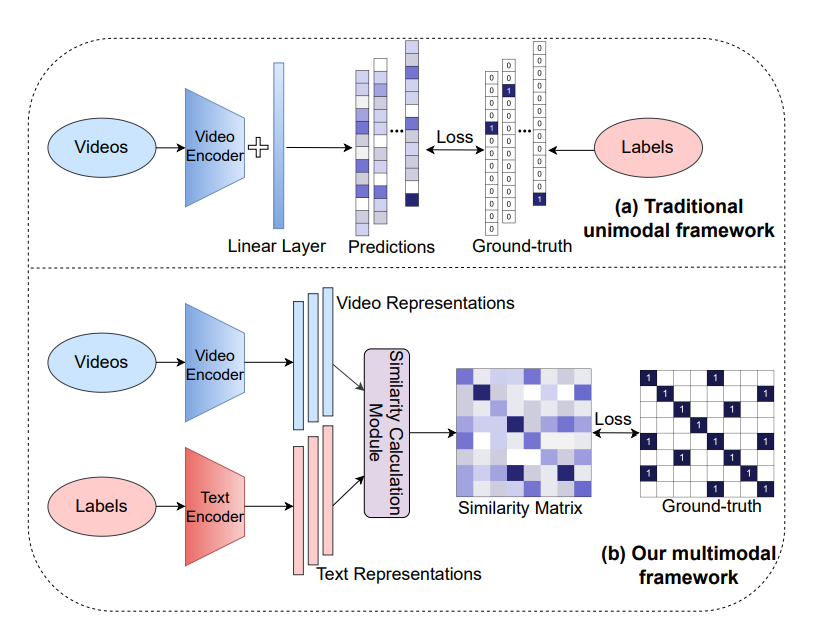
作者提到这种方式具有如下两种优势:
1). 可以利用更多的语义语言监督信息来增强传统行为识别方法的表示;
2). 确保所设计的模型可以在不用额外标注或者参数的前提下,实现 zero-shot 的迁移。
为了实现上述的效果,作者提到如果采用现有的 video-text 的方式进行学习,收集数据的过程将会变得非常痛苦。考虑到现在非严格对齐的 video-text 数据非常富裕,可以用 pre-train 的方式进行这种对比关系的学习。这个过程需要大量的算力支持,而且现有很多方法都采用了这种方式得到了多模态大模型,作者就想:那我还重新训练个啥?我直接用他们放出来的模型进行微调不就行了吗?考虑到这里,作者就采用了 pre-train,prompt,fine-tuning 的范式进行行为识别。具体怎么做的呢?且看下文分析。
2. Approach:
2.1. The New Paradigm: pre-train, prompt, fine-tuning:
* Pre-training: 首先需要利用现有的 预训练多模态大模型 进行第一步 image/video-text 相关性(也可以称为相似性)的学习。作者总结了当前主流的预训练方法:multimodal matching (MM), multimodal contrastive learning (MCL) and masked language modeling (MLM). 但是由于对算力的需求太大,作者这里直接利用前人提供的大模型来进行。
* Prompt:是近期 NLP 领域较为热点的一个话题。其目的是通过调整下游任务的定义形式,使得下游任务和预训练之间的形式更加接近。这样的话,就可以最大化预训练模型的优势,而不用换一种任务再去做特征上的微调。原文的定义是:adjusting and reformulating the downstream tasks to act more like the upstream pre-training tasks. 作者这里定义了两种 prompt,即:text-prompt 和 visual-prompt。
* Fine-tune: 在拥有足够的下有任务数据时,明显可以提升最终的测试性能。当 prompt 引入了新的参数时,需要将其结合到整个网络中进行 end to end 的学习。
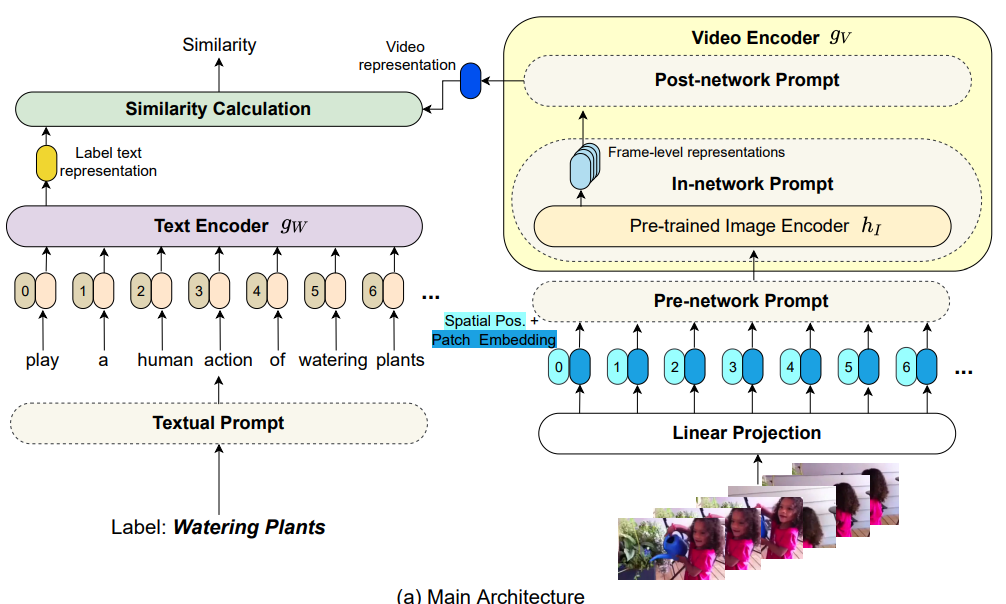
2.2. New Paradigm Instantiation Details:
作者提到如图 2(a) 所示,给定 image 和 对应的 label 信息,作者首先将行为的词汇转换为一句话。这个步骤是通过手动设置的 prompt 模板实现的。然后利用 CLIP 大模型的 language encoder 分支对该这句话进行映射,得到对应的特征表达。
对于 images,作者采用了 CLIP 大模型的 visual-encoder 来提取其特征,这里采用三种 prompt 变体来实现这个功能。具体的:
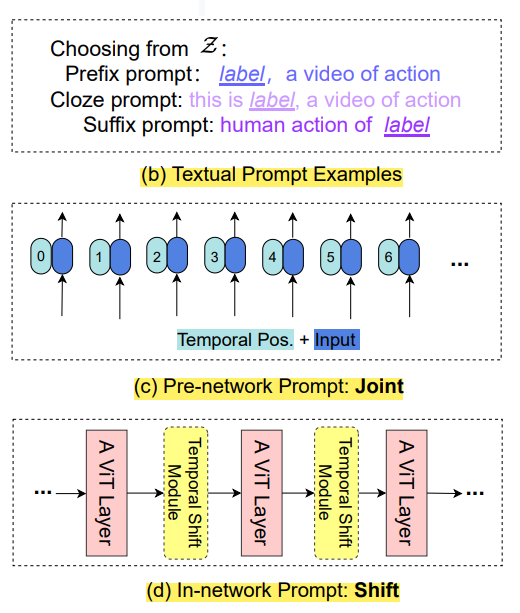
* Pre-network Prompt. 如上图 (c) 所示,这个部分的 prompt 主要体现在时空信息建模上,即:作者同时考虑到了 spatial positional encoding, 和 temporal positional encoding. 时序位置编码主要是用于指示 frame index。
* In-network Prompt. 如上图 (d) 所示,作者这里尝试引入一个 parameter-free prompt,简称 Shift。作者这里引入了 temporal shift module (ref: Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7083–7093, 2019.),沿着时间维度将部分时序通道进行偏移,以促进近邻视频帧时间的信息交互。作者在每两层 gV 之间添加一个 TSM 模块,但是这个东西是不带参数的,因此并不改变模型的参数量。
* Post-network prompt. 给定一个带有 F 帧的视频 X,作者分别用两个独立的 encoder 来编码空间和时间特征。第一个时间编码器,仅建模同一个 frame index 的 token 之间的关系。作者将多帧的 frame-level 的特征进行组合,并将其输入到 temporal encoder 中,以建模来自不同时刻的 token 之间的联系。这里,作者提供了四个选项,分别是: mean pooling, 1d-cnn, lstm, transformer。

===== 总体感受:
* 针对行为识别这个任务来说,将传统 1-N 的分类任务转换为多模态融合对比学习的框架,无疑是创新很大的。这也提供了一个新的研究思路。
* 从具体做法来看,从行为识别的 label 词汇 到 一句话的转换部分,介绍较少,这部分应该是 prompt 工程的核心。visual-prompt 的角度来看,作者提供了三个变体,分别从输入,网络和信息汇总三个角度进行特征学习。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号