Unicoder-VL: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training
2022-03-22 14:22:12
Paper: https://ojs.aaai.org/index.php/AAAI/article/download/6795/6649
Code: https://github.com/microsoft/Unicoder
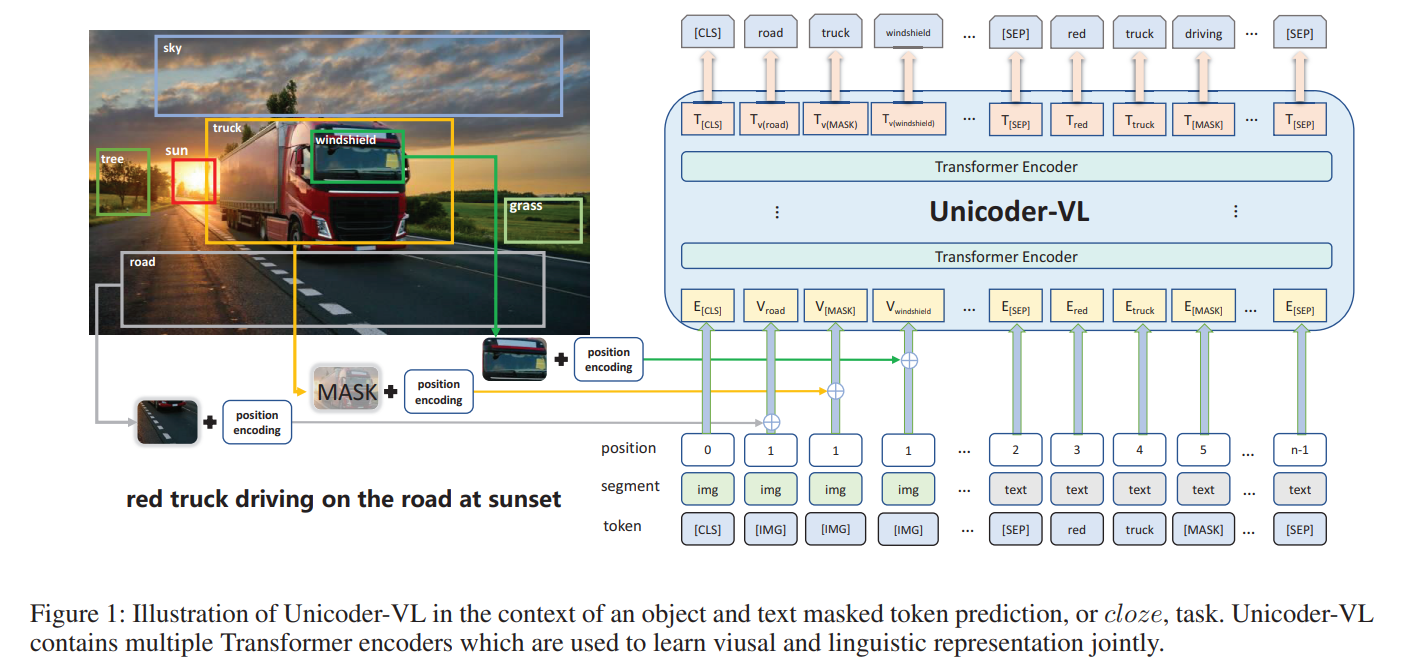
如图 1 所示, 作者从给定的图像中,先用 faster RCNN 抽取 proposal,得到对应的特征和 label。针对这些输入,作者加入了位置编码,然后输入到 Transformer encoder 中,进行特征提取。在预训练阶段,作者采用了三个损失函数,即:Masked Language Modeling(MLM), Masked Object Classification(MOC) and Visual-linguistic Matching(VLM)。感觉也是主流的预训练目标。
在下游任务上,作者采用了 Image-Text Retrieval,Zero-shot Image-Text Retrieval,Visual Commonsense Reasoning。
Stay Hungry,Stay Foolish ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号