
U-ViusalBERT --- Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions
Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions
2022-03-20 17:34:51
Paper: https://arxiv.org/pdf/2010.12831.pdf
Code: https://github.com/uclanlp/visualbert
本文拟解决 unpaired image-text data pre-training 问题。因为现有预训练方法均采用成对的 image-text 数据进行训练,但是实际上这种数据的获取和筛选较为困难。虽然现有的数据集也采用这种方式将数据规模处理到了几十亿的级别,但是数据收集和处理过程繁杂,效率较低。因此,作者思考是否可以利用 unpaired image-text data 进行预训练,以得到还不错的结果。
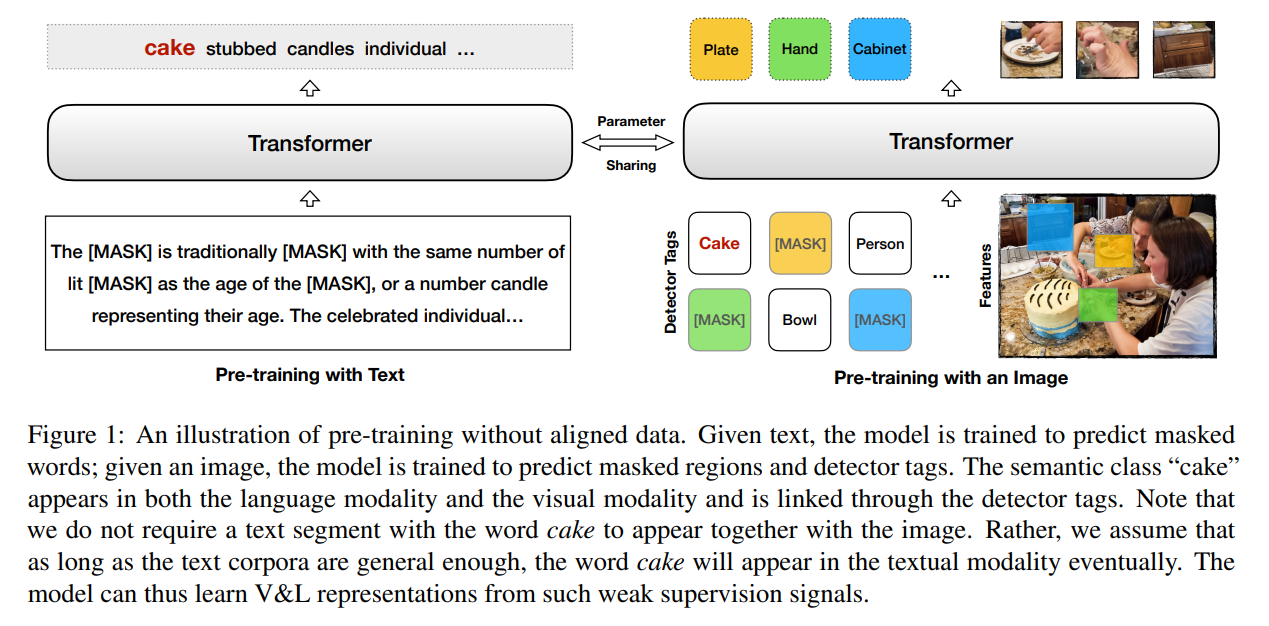
在方法部分,作者首先介绍了 VisualBERT 模型,然后讲解了用 aligned image-text data 进行预训练的过程。然后,讲解了本文所提出的 unpaired image-text data 训练得到的 Unsupervised VisualBERT。关于无监督预训练部分,作者提出了两个核心的设计:
1). mask-and-predict pretraining with unaligned data;
如图 1 所示,作者让 transformer 骨干网络进行共享,然后随机的在 text 和 image 域上进行预训练。具体的,对于 image 来说,作者对图像中的 patch 进行mask,然后让网路去预测被掩码的内容;对于 text 来说,作者对文本中的单词进行掩码处理,让模型进行预测。仅从这两个操作来看,并没有什么特殊的地方,因为这些操作都是单模态预训练技术的常规操作。作者将 image 和 text 这两个训练任务共享骨干网络后,总体的损失函数就是这两个单独损失的加和。
2). the detector tags;
类似 Oscar 预训练模型,作者也将物体检测器提取的 物体标签作为输入的一个部分。作者发现,从物体检测器标签的形式提供某种带有噪声的对齐,是有好处的。在预训练阶段,作者将 mask-and-predict objective 应用到 tags 上,也进一步促进了定位。空间坐标的映射和对应区域的坐标映射是相同的。坐标映射允许模型能够从不同区域中进行 tags 的区分。
=-=

 浙公网安备 33010602011771号
浙公网安备 33010602011771号