Visualbert --- A simple and performant baseline for vision and language
Visualbert: A simple and performant baseline for vision and language
2022-03-20 15:19:04
Paper: https://arxiv.org/pdf/1908.03557
1. Background and Motivation:
本文提出了一种简单灵活的模型 VisualBERT 来捕获 image 和 对应文本之间的丰富语义信息。VisualBERT 将 BERT 和 pre-trained object proposal systems,如 Faster-RCNN 检测器,结合起来。特别的,从图像特征中提取出来的 object proposals 被当做是一种无序的 input tokens,将其和 text 输入到 VisualBERT 。输入的文本和图像输入被多个 Transformer layers 联合进行处理。单词和物体候选框之间的交互,使得模型可以捕获文本和图像之间错综复杂的关系。
类似 BERT,在额外资源上的 pre-training VisualBERT 可以对下游任务带来提升。为了学习两个模态之间的关系,作者将 VisualBERT 的预训练放在 image captioning data 上进行,其中,图像的细节语义信息在自然语言中得到了充分的表达。作者提出了两个 visually-grounded language model objectives 进行预训练:
1). masked language prediction;
2). image-text matching loss.
作者的实验表明,在 image captioning data 上进行这种预训练,对于 VisualBERT 来说可以较好地学习可迁移的文本和视觉表示。
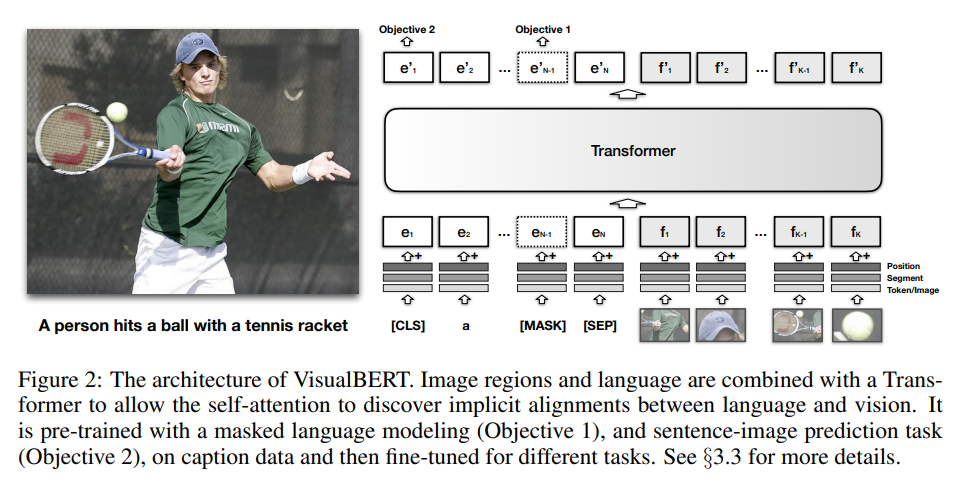
2. A Joint Representation model for vision and language:
如图 2 所示,该模型的输入有两个部分:图像 proposal 特征,以及 文本描述。此外,还有 segment embedding 和 position embedding。segment embedding 是指图像的 embedding,而不是 text embedding;position embedding 是用于对齐 words 和 BBox regions。
在训练阶段,作者进行了三个部分的训练:
1). 与任务无关的 pre-training:masked language modelling, sentence-image prediction.
2). 特定任务的 pre-training:在将 VisualBERT 在下游任务上进行微调之外,作者发现: it is beneficial to train the model using the data of the task with the masked language modelling with the image objective. 这个步骤使得 model 可以适应新的目标域。
3). Fine-tuning:这个步骤借鉴了 BERT fine-tuning,一个特定任务的输入,输出,目标被引入,Transformer 被训练用于最大化该任务的性能。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号