Fusion of Detected Objects in Text for Visual Question Answering
Fusion of Detected Objects in Text for Visual Question Answering
2022-03-18 16:29:58
Paper: https://aclanthology.org/D19-1219/
Code: https://github.com/google-research/language/tree/master/language/question_answering/b2t2
1. Background and Motivation:
本文除了语言, 也考虑到了视觉上下文内容,表明合适的视觉与语言信息可以在 VQA 任务上获得提升。本文所考虑到的主要挑战是回答关于给定图像的自然问题。作者想要尝试解决的更加 general 的问题是如何在一个神经结构中编码视觉和文字信息。如何最好的做到这一点,目前学术界和产业界对该问题的仍然无法清晰的回答。文本实体如何与图像中的物体进行绑定?文本和图像在后期进行结合,允许独立的分析,或者其中一个的分析必须建立在另外一个之上?若何跨模态协同推理?在编码句子语义之前在视觉世界进行 words 的定位,是否合理?本文收集了一些证据来回答这些问题,通过设计 the Bounding Boxes in Text Transformer, B2T2, 一个神经网络结构进行多模态的编码,作者在 VCR 数据集上进行了验证。作者的实验发现:文本符号和视觉特征协同推理的 early fusion 是 VCR 任务最重要的的因素。在模型的输入端,输入越多的视觉物体特征,就可以得到更好的结果,尽管他们并不是显示的对文本进行协同推理;物体的位置特征也是非常有用的。基于 CC3M 数据集的预训练可以使得本文模型更容易进行训练。
2. Models and Methods:
2.1. Dual Encoder
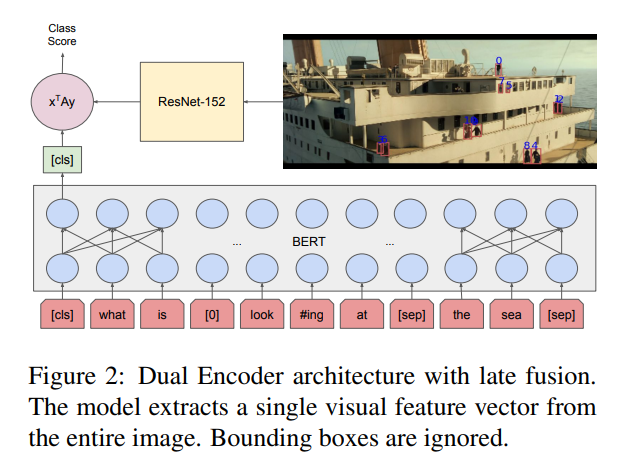
作者这里首先介绍了常规的 dual-encoder 的框架,如图 2 所示,底部的输入是文本信息,右上角是输入的图像信息,编码器分别为 BERT 和 ResNet-152。这两者的特征输入到分类器中,输出类别的得分。
2.2. B2T2:
然后作者介绍了本文提出的 B2T2 结构如图 3 所示,作者将其类别分布定义为:
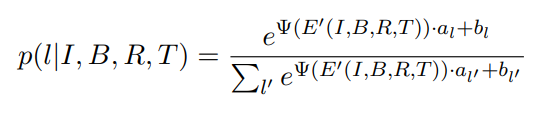
其中,al, bl 均为可学习的参数。E' is a non-contextualized representation for each token and of its position in text, but also of the content and position of the bounding boxes. 与 Dual-Encoder 的区别在于:text, image 以及 BBox 是在 non-contextualized token representations rather than right before the classification decision。
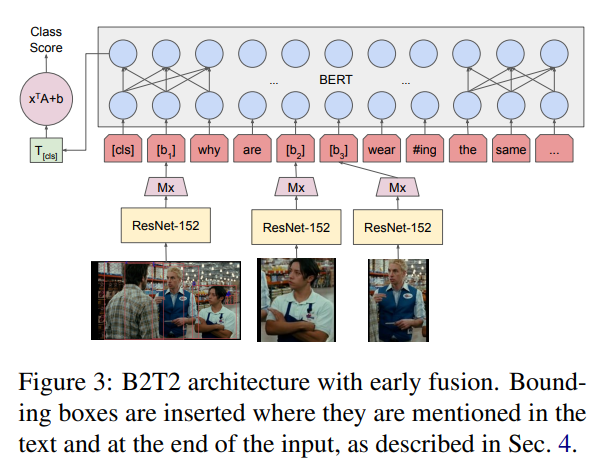
E' 的计算可以参考图 4,如下所示:

在预训练阶段,作者采用了 imposter identification 和 masked language model prediction (MLM) 的损失函数。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号