
ActBERT: Learning Global-Local Video-Text Representations
ActBERT: Learning Global-Local Video-Text Representations
2022-03-17 16:41:43
1. Background and Motivation:
本文受到 BERT 在 NLP 领域巨大成功的启发,尝试探索以自监督的方式进行 video-text 的联合学习。数据的问题,可以尝试从 YouTube 等网上获取,其中,旁边解说可以和视频中的物体很好地对应。
本文提出了 ActBERT 来学习一个联合 video-text 的表达,从成对的视频序列和文本描述中揭示了全局-局部视觉信息。全局和局部信息与语义流可以有效地进行交互。ActBERT 结合了巨大的上下文信息,探索了细粒度的关系进行 video-text 的联合建模。
首先,ActBERT 将全局动作,局部区域物体和文本描述结合到一个框架中。人的行为(Actions)是不同视觉相关任务的核心。准确的识别人类的动作可以表明模型在运动理解和复杂程度的推理的能力。显示的在预训练阶段建模人类行为可能是一种有效地方式。长期行为序列,进一步提供了时序依赖。虽然行为信息非常重要,但是却被前人的工作经常忽略。为了建模人类行为,作者从文本描述中提取动词(verbs),然后从原始数据集上构建了一个行为分类数据集。然后,一个 3D CNN 被用于预测行为标签。从这个优化的网络中提取出的特征,被作为行为的 embedding。利用这种方式可以得到 Clip 级别的行为,然后对应的标签可以被嵌入。除了上述全局行为信息,本文也结合了局部区域信息来提供细粒度的视觉信息。物体区域提供了细粒度的视觉信息,包括区域物体特征,物体的位置。语言模型可以从区域信息中获得益处,以更好的进行 language-visual 的对齐。
第二,本文也引入了 TaNgled Transformer 模块从三个源头进行编码:global actions, local region objects, and linguistic tokens。作者设计了一个混合的Transformer 模块来建模这三个信息。为了增强两个视觉信息和一个语言特征之间的联系,作者利用了一个单独的 transformer module 来对每一个模态进行了编码。
此外,本文设计了四个代理任务来训练 ActBERT,即:masked language modelling with global and local visual cues, masked action classification, masked object classification and cross-modal matching. 所得到的预训练模型在五个下游任务,如:video captioning, action segmentation, text-video clip retrieval, action step localization, and video question answering.
2. Model Architecture:
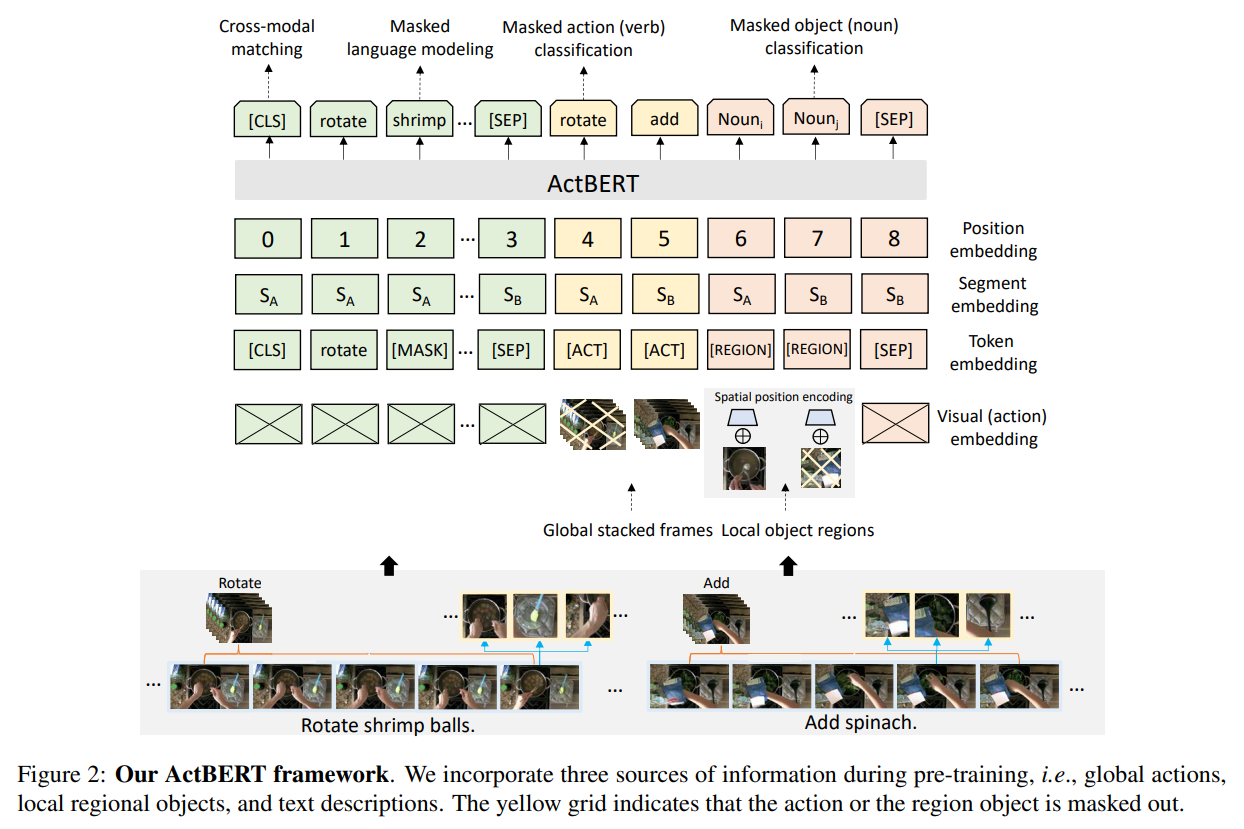
如上图所示,该网络的输入包括:actions, image regions, linguistic descriptions, special tokens。其中 special tokens 是用于区分不同的输入。可以发现,本文提出的网络结构,其输入与其他工作的核心区别在于:利用一个额外的行为预测模块,得到了预处理后的中间结果,然后将其当做是一个输入。这样就与其他 vision-text 工作区分开来了。特别是两模态融合 和 tangled transformer。
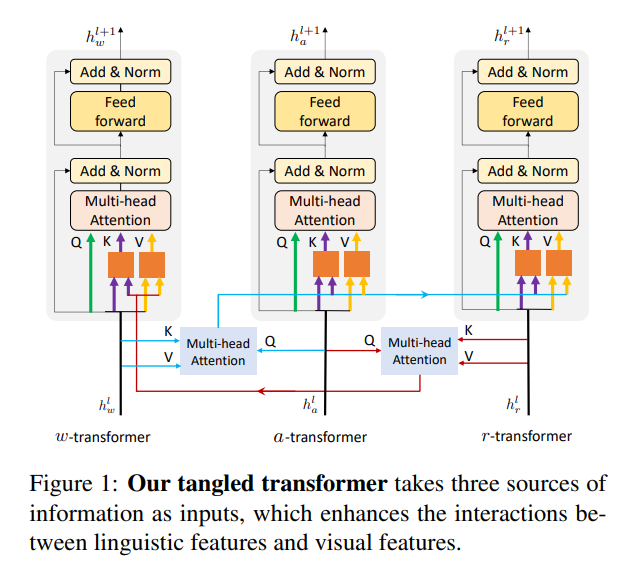
关于新设计的 tangled transformer 模块,如图 1 所示,可以看做是 co-attention 的一个拓展。作者专门对比了 ViLBERT 中提出的 co-attention 模型,并列出了三点区别:
First, the co-attentional transformer block simply passes the keys and values from one modality to the other modality’s attention block, without further pre-processing.
Second, ViLBERT treats the two modalities equally, while our tangled block utilizes a global cue to guide the selection of local hints from linguistic and visual features.
Third, the keys and values from different modalities replace the origin key-values in ViLBERT, while our tangled transformer stacks the key-value with the original one. In this way, both the linguistic and visual features are incorporated during transformer encoding.
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号