12-in-1: Multi-Task Vision and Language Representation Learning
12-in-1: Multi-Task Vision and Language Representation Learning
2022-03-17 09:45:41
Code: https://github.com/facebookresearch/vilbert-multi-task
1. Background and Motivation:
本文提出了一种多任务学习的方法,可以将不同 vision-language 任务放到一个模型中进行训练。得到了更好的性能提升,所有任务的平均提升幅度为 2.05 个点。之所以这么做,是因为虽然 vision-language 任务设定不同,但是均需要对图像或者文本有深入的理解才能完成的很好。因此,这些任务是可以共享模型的。在本文中,作者将 12 个不同数据集,共计 4 种任务,在 ViLBERT 的基础上进行了多任务联合训练。实验结果表明,在 12 个任务中,11个任务均获得了提升。此外,作者提到联合的预训练步骤,对于单个任务来说也是非常有效的提升精度的方式。
2. Approach:
2.1 基础模型:
这里的基础模型采用的是 ViLBERT (ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks),该框架如图所示:
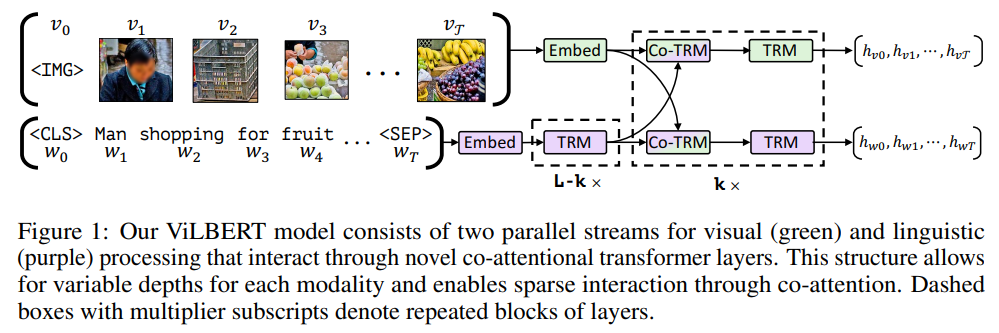
可以发现,ViLBERT 是由两个并行的分支构成的,每一个分支都包含 Transformer Blocks,然后中间接了 co-attentional transformer layers (Co-TRM),确保两个模态之间可以自由的进行信息交流。ViLBERT 是在 CC3M 数据集上,利用两个代理任务:masked multi-modal modelling 以及 multi-modal alignment prediction。
2.2. Multi-Task Learning:
作者这里考虑一种简单的 multi-task model,每一个任务均包含一个任务特定的 “head”,共享的是 ViLBERT 主干网络。 学习的目标是最小化在所有任务上的损失。鉴于不同任务的学习难度不同,作者这里设计了一种 task token 来对比进行建模 {IMG, v1, . . . , vn, CLS, TASKt, w1, . . . , wm, SEP}。剩余的优化目标均为多个任务各自的优化目标,即:Vocab-Based VQA Output, Image Retrieval Output, Referring Expressions Output, Multi-modal Verification Output.
2.3. Large-Scale Multitask Training:
本文所有的模型均在 CC3M 上进行了预训练处理,包括本文的自监督任务。
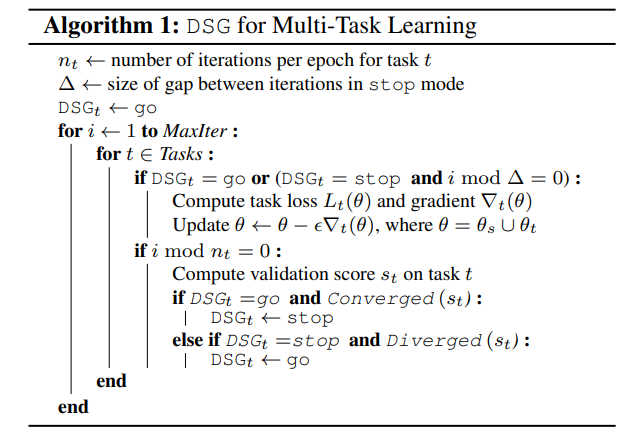
Dynamic Stop-and-Go:由于不同任务可能具有不同的困难程度和数据集规模,简单进行任务循环,可能导致在简单任务上的过拟合。通常,早停机制可以有效的缓解该问题, 然而在多任务训练过程中停止一个任务,会导致灾难性遗忘。作者引入了一种直观但是有效的动态停止和进行机制 (dynamic stop and go, DSG) 以避免这些问题。作者监督每一个任务的验证集损失,每一个任务 epoch 进行一次计算。如果两个 epoch 性能提升低于 0.1%,则认为达到了收敛,并将其转换为 stop 模式。在 DSG stop 模式下,一个任务仅在一个 iter-gap 上进行一次更新。如果验证集性能从任务最好的性能降低了0.5%,则会进入停止模式,该任务被认为收敛了,并转移为 go 模式。
Curriculum Learning:
作者这里进行了课程学习策略 和 反课程学习策略。但是与之前的观测不同,作者发现:当将其与本节提出的策略将结合的时候,利用非课程可以得到更好的性能。
此外,作者也提到,warm-up duration 和 local scaling 均是非常重要的技巧,适度的调整可以获得意想不到的性能。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号