ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
2022-03-16 21:02:21
Paper: http://proceedings.mlr.press/v139/jia21b/jia21b.pdf
1. Background and Motivation:
随着深度学习逐步进入深水区,基于多模态大模型的预训练技术开始逐渐吸引众多研究者的关注。本文提到现有方法所得到的大型数据集,规模还不足,因此尝试利用 CC3M 数据集的收集方式,得到海量的带有噪声的 image-text pair 数据。但是不像 CC3M 那样采用严格的筛选方式得到较为干净的数据,作者仅采用简单的过滤方式,得到了比 CC3M 大两个数量级的数据集。作者的实验表明,在这种带有严重噪声的数据上得到的模型,也可以在众多任务上取得不错的效果。
为了训练该模型,作者利用一个目标函数在一个共享的隐层映射空间来对齐视觉和语言表示,使用的是一个简单地 dual-encoder 结构。类似的目标可以用于学习视觉-语义映射(visual-semantic embedding, VSE)。作者将其所得到的模型,定义为 ALIGN:A Large-scale ImaGe and Noisy-text embedding。图像和文本编码器是通过一个对比损失来建模的,通过拉近匹配样本的距离,而推远非匹配样本的距离。这也是自监督和监督表示学习常用的损失函数。这种对齐的图像和文本表示可以自然的适合跨模态匹配/检索任务,并在对应的数据集上均得到了领先的精度。
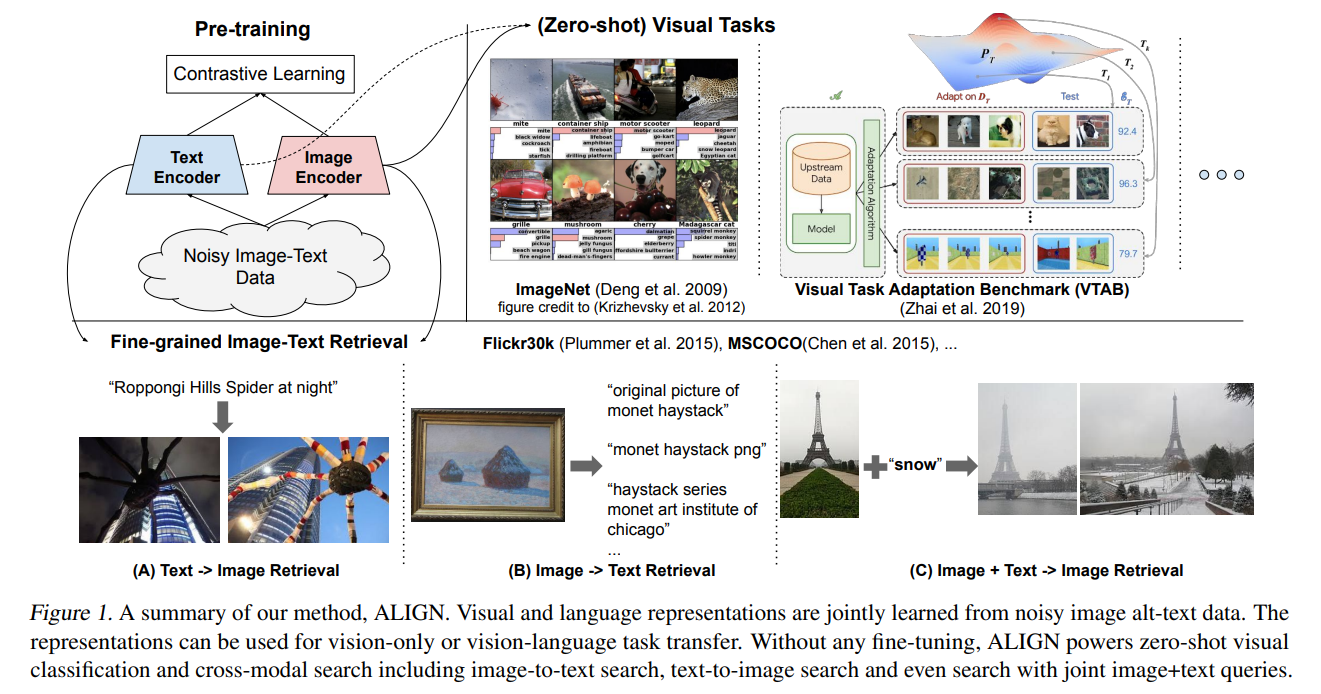
2. A large-scale noisy image-text dataset:
采用类似 CC3M 数据集的收集方法,得到海量 image-text pair,设计了简单的 image- 和 text-based filtering 操作,来进行简单的过滤。
3. Pre-training and Task Transfer:
采用了 dual-encoder 的方式进行 ALIGN 的预训练,该模型也是一种双塔结构。
Image encoder:EfficientNet
Text encoder:BERT
这两个 encoder 通过 normalized softmax loss 进行优化。在训练过程中,作者将匹配的 image-text pairs 作为正样本,其他随机组合的样本作为负样本。
在下游任务方便,ALIGN 在图文检索和图像识别方面进行了实验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号