CLIP: Learning Transferable Visual Models From Natural Language Supervision
CLIP: Learning Transferable Visual Models From Natural Language Supervision
2021-11-25 21:29:02
Paper: https://arxiv.org/pdf/2103.00020.pdf
Code: https://github.com/OpenAI/CLIP
2. Model:
2.1 数据集: 关于数据集部分,作者收集了大概 400 million(image, text)的样本。所得到的数据规模和用于训练 GPT-2 数据大致在同一个级别。
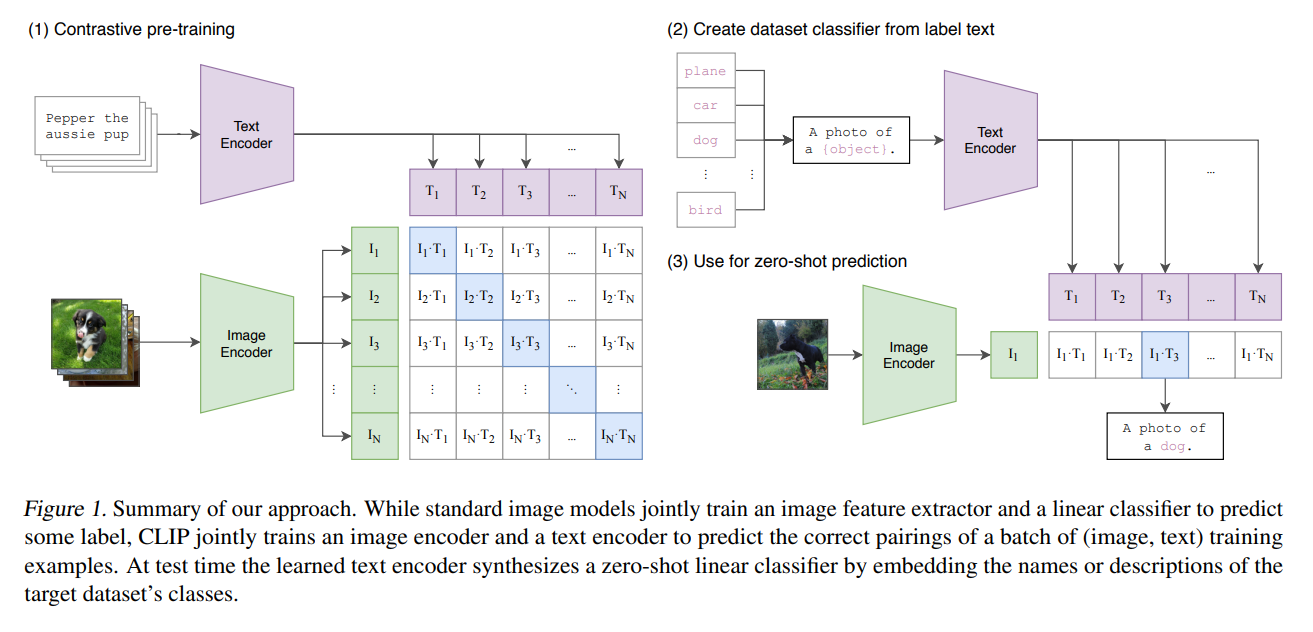
2.2 选择一个有效的预训练方法:
作者提到刚开始的做法和 VirTex 类似,联合的在 image CNN 和 text Transformer 上从头训练,以预测图像中的语言。然而,作者在扩大化该模型时,遇到了困难。如图 2 所示,此处的效率值与 bag of words prediction 的方式相比,效率低了将近三倍。最近一些对比表示学习的工作表明:对比目标可以超过同等的预测目标 (contrastive objectives can outperform the equivalent predictive objective)。注意到这一发现,作者探索训练一个系统来解决潜在更容易的代理任务,仅预测哪个文本作为一个整体可以与图像进行匹配,而不是那个文本的哪个单词。与 bag of words 编码基准相同,作者将预测目标切换为了对比目标,如图 2 所示,在迁移到 ImageNet 数据集上时,得到了 4倍的效率提升。

给定一个 batch,即 N 个 image-text pair,CLIP 被训练用于预测 N*N 个可能的配对中,哪个是真实的。为了做到这一点,CLIP 学习了一个多模态的映射空间,通过联合训练一个图像编码器和一个文本编码器,来最大化正确匹配的图像和文本映射之间的余弦相似度,同时最小化剩下并不匹配的样本之间的相似度。
由于过拟合不是一个非常严重的问题,训练 CLIP 的细节可以得到极大的简化。可以直接从头训练 CLIP,而不用预训练权重。表示和对比映射空间的非线性映射被移除,仅采用一个线性映射,将每一个编码器的表示映射为不同模态映射空间。作者也将文本转换函数移除,从文本中均匀采样单个句子,因为许多 CLIP 预训练模型的图文对就是单个句子。
2.3. 选一个和扩大化模型:
作者考虑到两种不同的结构作为图像编码器。对于第一种,作者采用了 ResNet50 网络,并对其进行了部分改善。 第二种网络结构是最近比较火热的 ViT 模型。文本编码器是 Transformer。
选定模型后,需要进行模型扩大化处理,本文对图像分支的网络从三个维度进行了扩充,即 width,depth,以及 resolution。对于文本分支的网络,仅对模型的宽度进行了扩充。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号