OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation
OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation
2021-07-21 20:23:07
Paper: https://arxiv.org/pdf/2107.00249.pdf
Code: Not available yet
1. Background and Model:
本文提出一种联合三个模态的预训练模型,以取得更好的结果。模型 OPT 的示意图如下所示,该模型是一个大型语料库上进行学习的,包含了 language-vision-audio 三元组。可以通过多任务学习的方式进行学习,可以有效地适应到下游任务,给定单个,双流,甚至三个模态的输入。模型包含三个 single-modal encoders, a cross-modal encoder, two cross-modal decoders.

跨模态理解需要对齐输入,从细粒度符号级别 到 粗粒度样本级别。工作的方式就是跨模态的翻译,cross-modal generation, 可以进行模态级别的建模。 所以作者提出的 OPT 模型可以从三个角度进行学习,即:token-level,modality-level,sample-level 进行建模。
从模型结构的角度上来说,主要分为如下三个部分:
1.1 Single-Modal Encoder:
Text Encoder: 首先利用 WordPieces 对文本进行划分,得到符号序列。最终的 embedding 是通过对每一个符号映射和位置编码相加,然后用 layer-norm layer 进行处理;
Vision Encoder: 利用 Faster rcnn 模型提取视觉表示,即 ROI features。然后编码了其 7-D 的位置特征 [x1, y1, x2, y2, w, h, w*h],其中 x1 y1 x2 y2 是 box 的顶点坐标,w 和 h 分别表示该区域的宽和高。然后,视觉信息和位置信息分别用两个 fc layer 映射到同一个空间。通过将两个 fc 的输出相加,得到该分支的结果。然后输入到 layer-norm layer 中。
Audio Encoder: 作者利用 wav2vec 2.0 得到音频信息符号,提取每一个符号的特征,然后输入到 layer-norm 中得到最终 audio 的特征。
1.2 Cross-modal Encoder:
作者引入了一个跨模态编码器来进行多个模态的融合,其实就是简单地 concatenate,然后输入到一个 transformer 模块中:
![]()
1.3 Cross-Modal Decoder:
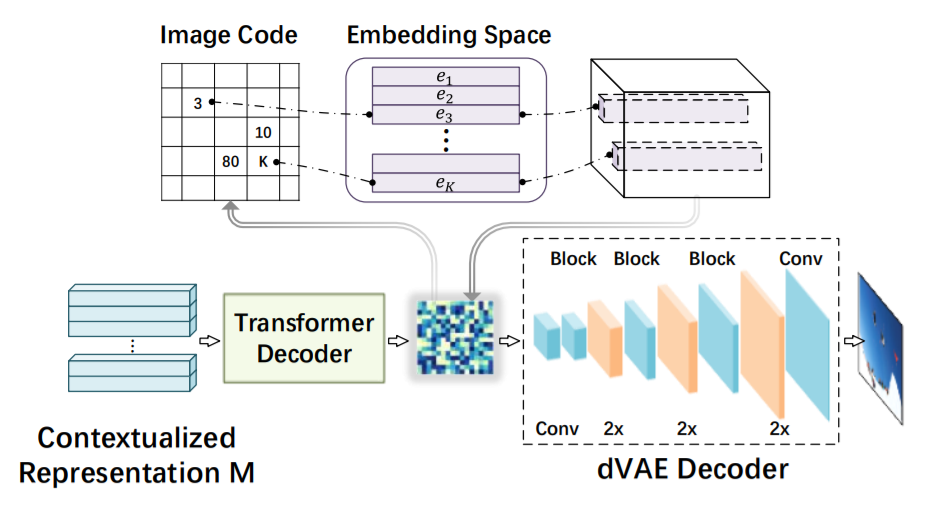
作者这里引入了两个 decoder 分支,一个是 text decoder,一个是 vision decoder。其中文本解码器就是 Transformer 进行单词的预测。视觉解码器则是 two-stage framework:离散表示学习 和 语言建模。
第一阶段聚焦于将 image 转换为 离散的 codes,dVAE 模型用于实现该过程。第二阶段是,建构了一个 language model,来学习产生 code sequence。
2. Pre-training Tasks:
作者构建了三个预训练任务进行自监督学习:
1). token-level modeling,
这个思路较为常见,即利用产生式模型的机制,对三个模态分别进行掩模处理,预测对应被 mask 掉的部分;
2). modality-level modeling,
Modality-level masking: 作者以 30% 的概率去擦除其中一个 或者 两个模态的输入。三个模态均被擦除的可能性被设置为 0. 毕竟,还是要有可用信息的嘛。以使得 OPT 模型可以在模态缺失的条件下,取得较好的下游任务适应,即可以处理单个模态,两个模态和三个模态输入的任务设定。
Denoising Text Reconstruction: 利用 Transformer decoder 进行输入文本的重构;
Denoising Image Reconstruction: 利用 VAE 模型来重构图像样本;
3). sample-level modeling.
对于 text-image-audio 样本对,作者随机的对其中的 1-2 个模态进行替换,以让模型去区分到底是不是 matching 的:
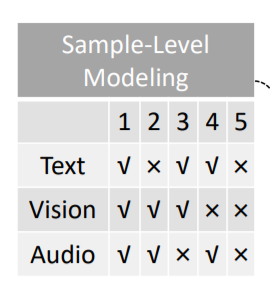
如上图所示,共分为 5 种情况。作者提取 [CLS] 符号的输出表示,作为三元组的联合表达,然后输入到 fc layer 和 sigmoid 函数中,去预测得分。预测的得分是 5-D 的输出。
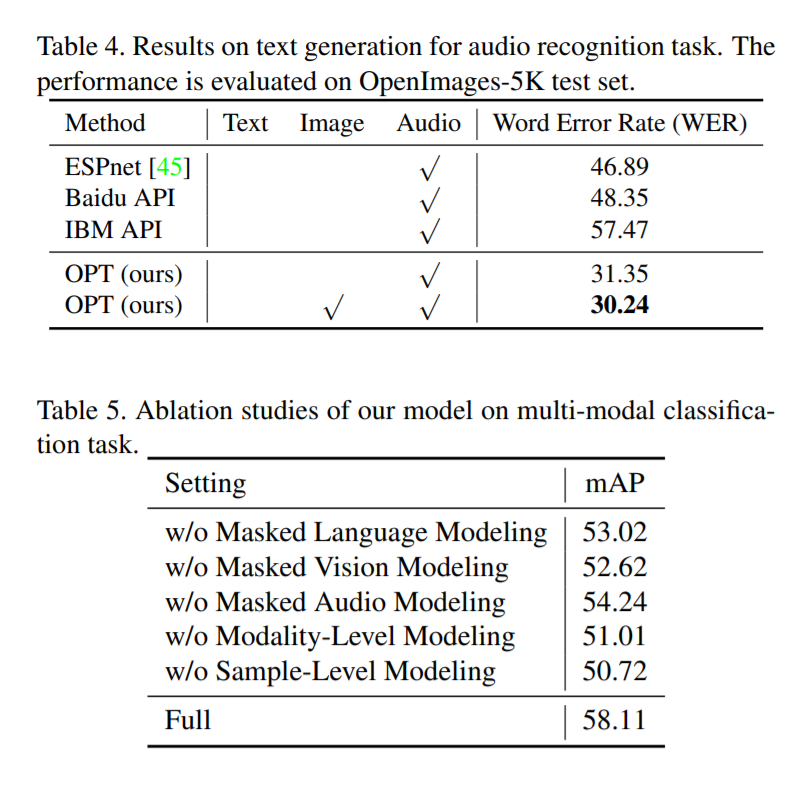
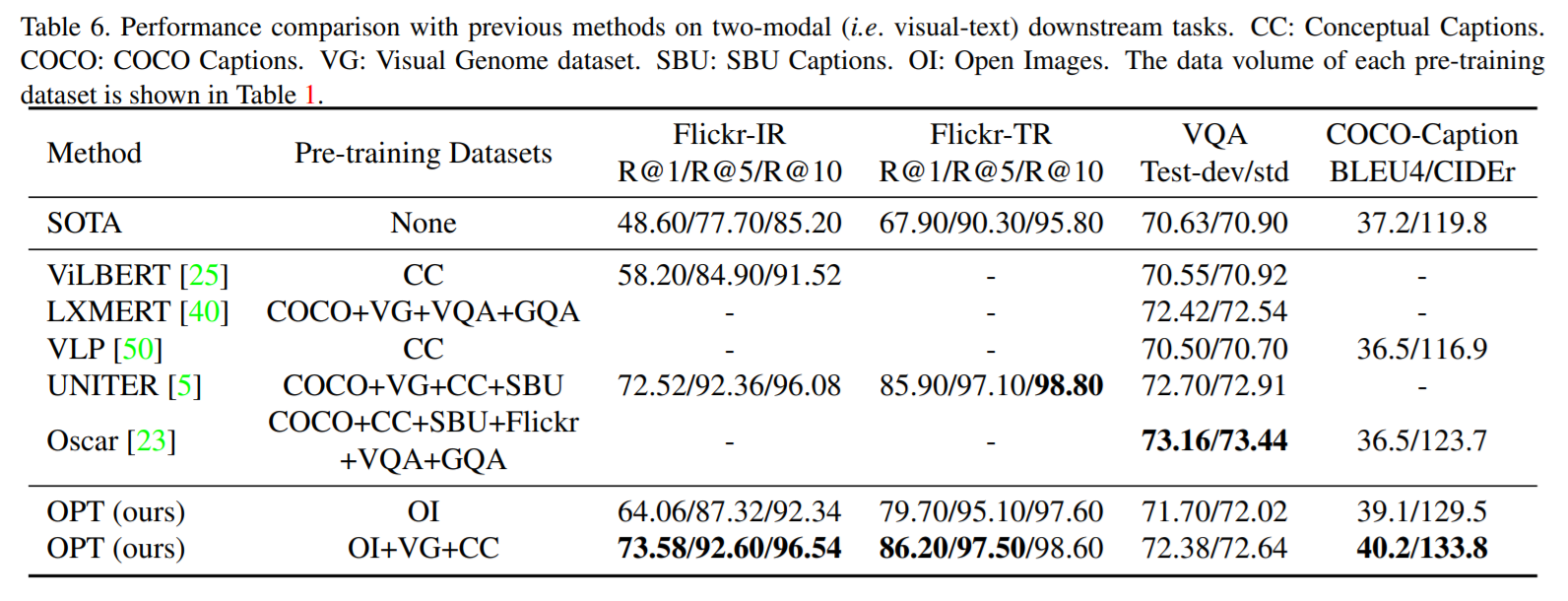
3. Experiments:


==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号