Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
2021-07-20 08:58:37
Paper: cvpr2021
Code: https://github.com/google-research-datasets/conceptual-12m
1. Background and Motivation:
当前 vision-language 的预训练模型大行其道,如何获取海量的 image-language 数据对成了一个棘手的问题。当前算法一般采用多个公共数据集构成几百万级别的语料库。但是这些数据,作者认为还不够,无法较好的学习长尾视觉概念。通过放宽过滤网上图像文本数据的条件,使得最终收获的图像更多,达到更高的召回率。作者给出的案例如下所示:

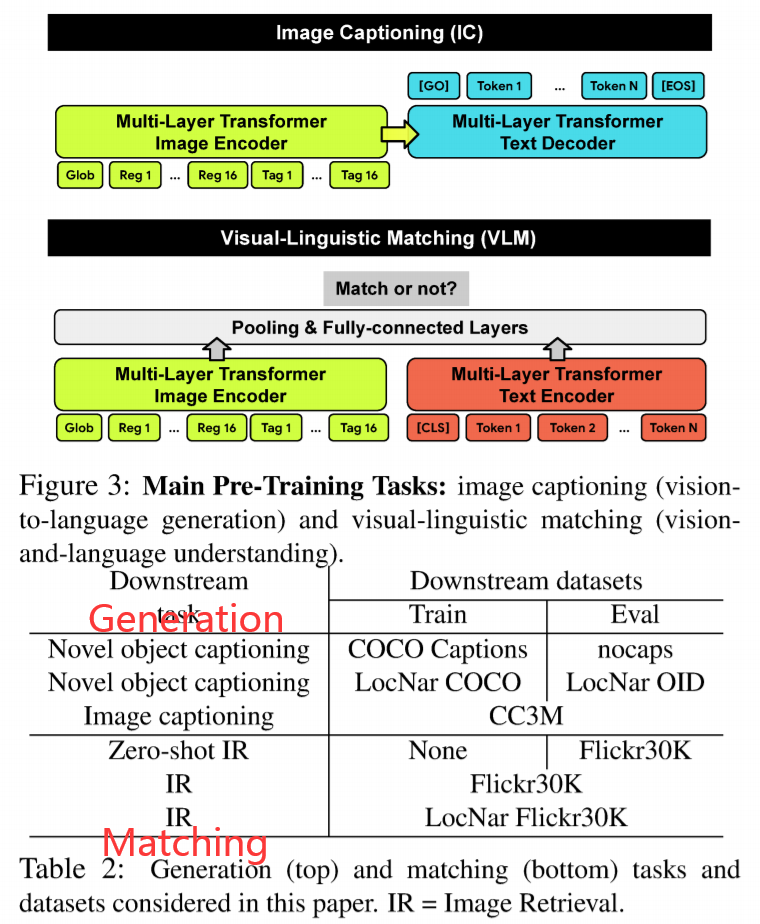
此外,作者在该数据集上进行了产生式和匹配任务的学习。如下图所示,一个是 image captioning,另外一个是图像文本匹配。并在多个下游任务上进行了实验,如表格2所示。
2. Input Representation and Results:
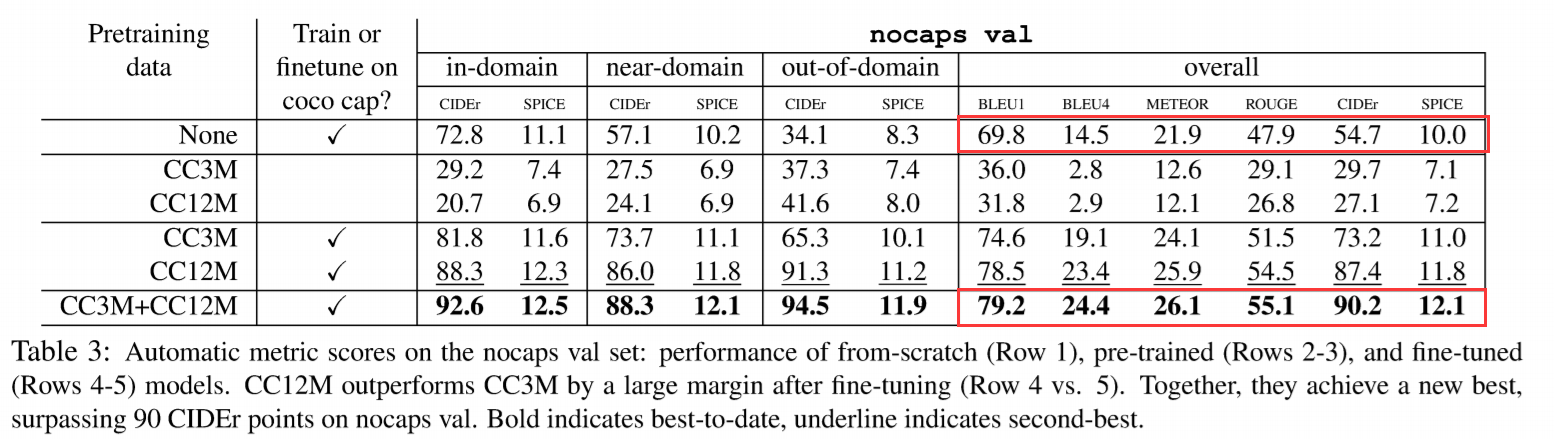
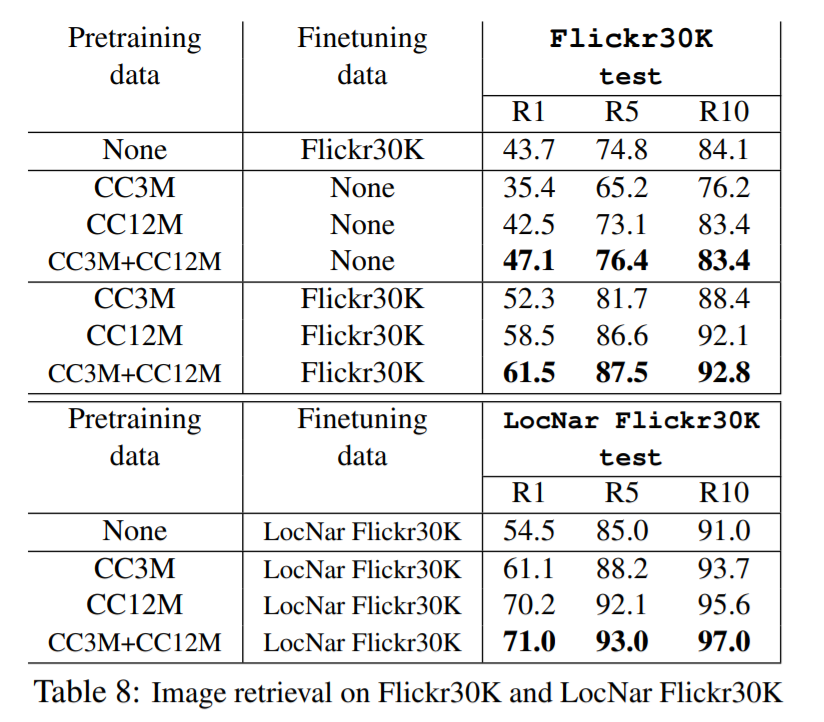
作者采用了 graph-RISE 的方法来提取整张图像的特征,在 visual Genome 上训练 faster RCNN,骨干网络为 ResNet101。现在 JFT 数据集上进行训练,然后在 ImageNet 上进行微调。选择前 16个 box 及其特征。利用 Google 的 API 算法,预测得到 16 个图像标签,将其当做文本输入。这些全局,局部,和标签特征,一起被当做是一个 1+16+16 的向量,作为模型的底层特征。如下所示,预训练+微调的结果,得到了大幅度的提升:

==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号