(转发)深度学习模型压缩与加速理论与实战(一):模型剪枝
深度学习模型压缩与加速理论与实战(一):模型剪枝
2021-06-23 15:42:47
Source: https://blog.csdn.net/wlx19970505/article/details/111826742
Code: https://github.com/lixiangwang/model_prune_yolov3-
其他文献:
- SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications, Pengyi Zhang, Yunxin Zhong, Xiaoqiong Li [Paper]
- Learning Efficient Convolutional Networks through Network Slimming, Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, Changshui Zhang [Paper] [Code]
文章目录
通道剪枝
稀疏训练策略
层剪枝
微调精度恢复训练
剪枝顾名思义,就是通过一些算法或规则删去一些不重要的部分,来使模型变得更加紧凑,减小计算或者搜索的复杂度,一种典型的模型剪枝方法如下图:
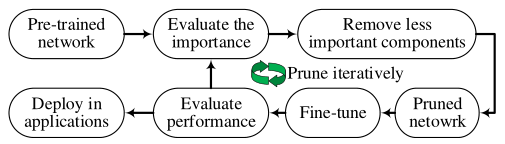
它包括四个迭代步骤:
1. 评估一个预先训练的深度模型中每个组件的重要性;
2. 剔除对模型推理不重要的成分;
3. 微调修剪模型,以弥补潜在的暂时性能下降;
4. 对微调后的模型进行评估,确定修剪后的模型是否适合部署。为了防止过度剪枝,最好采用增量剪枝策略。
对一个深度卷积系的模型而言,剪枝操作之前需要对模型进行稀疏化训练,从而根据稀疏情况进行模型组件的选择,通常来说,稀疏化有四个粒度的稀疏方式,分别是weight-level,kernel-level,channel-level,layer-level。weight-level具有最高的灵活性和泛化性能,也能获得更高的压缩比率,但是它通常需要特殊的软硬件加速器才能在稀疏模型上快速推理。相反,layer-level稀疏化不需要特殊的包做推理加速,而channel-level稀疏化在灵活性和实现上做了一个平衡,它可以被应用到任何典型的CNN或者全连接层(将每个神经元看作一个通道)。
在我们的方案中,结合layer-level和channel-level,相当于是考虑两个角度去剪枝模型:模型变短(layer-level)和模型变窄(channel-level),它的具体思路如下:
通道剪枝:
和模型剪枝的通用算法类似,我们的通道剪枝流程如下:
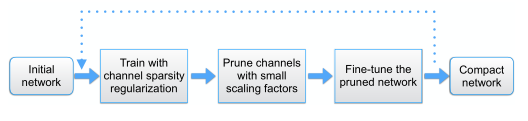
根据模型的主体结构,我们会筛选出参与剪枝的CBL结构(即Conv Layer + BN Layer + LeakyReLU Layer)的集合, 大部分分布于Darknet骨干网络,对于上采样 upsample 之前的一个CBL不参与剪枝(实验表明这个CBL对精度影响较大)。
如何去评估CBL集合中,每个channel的重要性呢?具体的做法是利用BN层中的缩放因子 γ,在训练过程当中来衡量 channel 的重要性,将低于一个阈值的CBL层的channel进行删减,达到压缩模型大小,提升运算速度的效果。其中,阈值可以通过我们设定的裁剪比例(超参数,实验可调)进行排序截断得到。如下图:
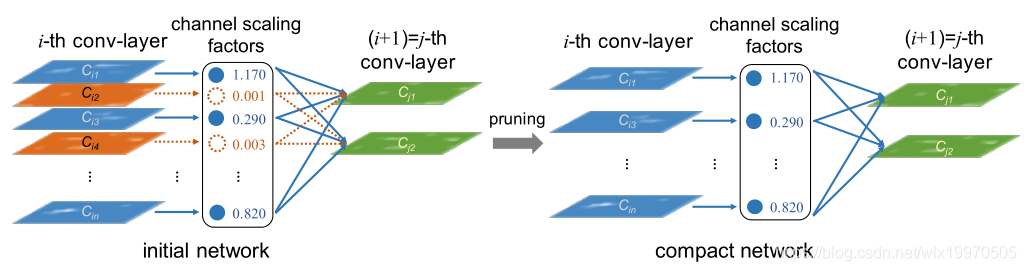
左边为训练后的稀疏模型,中间一列是scaling factors,也就是BN层当中的缩放因子γ,当γ较小时(如图中0.001, 0.003),所对应的channel就会被删减,得到右边所示的模型。在我们的算法在,先以全局阈值找出各卷积层的mask,然后对于每组 shortcut,它将相连的各卷积层的剪枝 mask 取并集,用 merge 后的 mask 进行剪枝,这样对每一个相关层都做了考虑,同时它还对每一个层的保留通道做了限制。如何去训练出这样的稀疏模型呢?一个简单的做法是对BN层在梯度回传的时候附加一个梯度,是只训练趋于稀疏化,具体做法可以反映在损失函数中,附加一个γ参数的L1正则项:
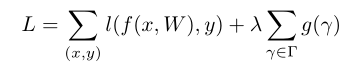
第一项是模型预测所产生的损失,第二项就是用来约束γ的,λ是权衡两项的超参。
稀疏训练策略:
在我们的方案中,对BN参数进行稀疏训练我们提供三种策略:
1. 恒定λ:
在整个稀疏过程中,始终以恒定的λ给模型添加额外的梯度,因为力度比较均匀,往往压缩度较高。但稀疏过程是个博弈过程,我们不仅想要较高的压缩度,也想要在学习率下降后恢复足够的精度,不同的λ最后稀疏结果也不同,想要找到合适的往往需要较高的时间成本。
2. 全局λ衰减:
设定在epochs的0.5阶段λ衰减100倍。前提是0.5之前权重已经完成大幅压缩,这时对λ衰减有助于精度快速回升,但是相应的bn会出现一定膨胀,降低压缩度,有利有弊,可以说是牺牲较大的压缩度换取较高的精度,同时减少寻找 λ 的时间成本。当然这个0.5和100可以自己调整。注意也不能为了在前半部分加快压缩 bn 而大大提高 λ,过大的 λ 会导致模型精度下降厉害,且 λ 衰减后也无法恢复。
3. 局部λ衰减:
在 epochs 的0.5阶段开始对85%的通道保持原力度压缩,15%的通道进行λ衰减100倍。这个85%是个先验知识,是由策略一稀疏后尝试剪通道几乎不掉点的最大比例,几乎不掉点指的是相对稀疏后精度;如果微调后还是不及baseline,或者说达不到精度要求,就可以使用策略三进行局部λ衰减,从中间开始重新稀疏,这可以在牺牲较小压缩度情况下提高较大精度。
在代码中需要在训练的时候,获取需要考量prune层的index,在进行梯度的附加项:
CBL_idx, _, prune_idx=parse_module_defs2(model.module_defs)
BNOptimizer.updateBN(model.module_list, opt.s, prune_idx, epoch,opt, opt.sr_mode)
其中,parse_module_defs2 的定义如下:
def parse_module_defs2(module_defs): CBL_idx = [] Conv_idx = [] shortcut_idx = dict() shortcut_all = set() ignore_idx = set() for i, module_def in enumerate(module_defs): if module_def['type'] == 'convolutional': if module_def['batch_normalize'] == 1: CBL_idx.append(i) else: Conv_idx.append(i) if module_defs[i + 1]['type'] == 'route' and 'groups' in module_defs[i + 1]: ignore_idx.add(i) elif module_def['type'] == 'upsample': # 上采样层前的卷积层不裁剪 ignore_idx.add(i - 1) prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx] return CBL_idx, Conv_idx, prune_idx class BNOptimizer(): ''' 稀疏训练 mode==1: 恒定s给bn回传添加额外梯度 mode==2: 全局s衰减,前50%epoch恒定s,后50%恒定s*alpha mode==3: 局部s衰减:前50%epoch恒定s,后50%中,对percent比例的通道保持s,1-percent比例的通道衰减s*alpha ''' @staticmethod def updateBN(module_list, s, prune_idx, epoch,opt=None,mode = None,percent = 0.85, alpha = 0.01): if mode == 1: for idx in prune_idx: bn_module = module_list[idx][1] bn_module.weight.grad.data.add_(s * torch.sign(bn_module.weight.data)) # L1 elif mode ==2: s = s if epoch <= opt.epochs * 0.5 else s * alpha for idx in prune_idx: bn_module = module_list[idx][1] bn_module.weight.grad.data.add_(s * torch.sign(bn_module.weight.data)) # L1 elif mode == 3: if opt.sr and opt.prune==1 and epoch > opt.epochs * 0.5: idx2mask = get_mask2(module_list, prune_idx, percent) if idx2mask: for idx in idx2mask: bn_module = module_list[idx][1] # bn_module.weight.grad.data.add_(0.5 * s * torch.sign(bn_module.weight.data) * (1 - idx2mask[idx].cuda())) bn_module.weight.grad.data.sub_((1-alpha) * s * torch.sign(bn_module.weight.data) * idx2mask[idx].cu
层剪枝:
层剪枝是在之前的通道剪枝策略基础上衍生出来的,在通道剪枝后进行层剪枝操作。针对每一个Darknet的shortcut层前一个CBL进行评价,对各层的γ均值进行排序,取最小的N层(N是实验中可调的超参数)进行层剪枝。为保证Darknet结构完整,这里每剪一个shortcut结构,会同时剪掉一个shortcut层和它前面的两个卷积层。Darknet中有23处shortcut,剪掉8个shortcut就是剪掉了24个层,剪掉16个shortcut就是剪掉了48个层,总共有69个层的剪层空间。
微调精度恢复训练:
在进行通道剪枝和层剪枝之后,一般精度都会有不同程度的下降,这取决于剪枝的力度,但一般都可以通过微调剪枝之后的模型后再训练进行精度恢复,由于剪枝后的模型更加简单,所以往往在任务目标不那么复杂的情况下,具有更好的泛化性能(即剪枝前的模型可能过拟合于任务的数据集,而剪枝并且微调训练后的模型精度可能表现的更好,这在我们的实验中是有体现的)。即使是微调训练精度恢复不上去,依然可以采用知识蒸馏技术,将剪枝前的模型作为教师模型,引导剪枝后的学生模型进行蒸馏训练。需要强调的是,蒸馏在这里只是辅助微调,如果注重精度优先,剪枝时尽量剪不掉点的比例,这时蒸馏的作用也不大;如果注重速度,剪枝比例较大,导致模型精度下降较多,可以结合蒸馏提升精度。或者如果微调后精度能很好的恢复上去,也不要采用蒸馏策略,因为蒸馏策略会限制学生网络的精度上限,且蒸馏训练会需要更大的GPU内存来实现,增加了实验的成本。
————————————————
版权声明:本文为CSDN博主「贝壳er」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wlx19970505/article/details/111826742

 浙公网安备 33010602011771号
浙公网安备 33010602011771号