Self-Supervised Learning with Swin Transformers
Self-Supervised Learning with Swin Transformers
2021-05-11 20:32:02
Paper: https://arxiv.org/pdf/2105.04553.pdf
Code: https://github.com/SwinTransformer/Transformer-SSL
1. Background and Motivation:
作者提到最近 cv 领域的两个技术潮流,一个是以 MoCo 为首的自监督视觉表达;另一个是以 Transformer 为首的骨干网络的设计。但是目前这两种技术尚未有效地进行结合,还是独立发展的阶段。MoCo v3 和 DINO 都尝试将自监督学习和 Transformer 的架构结合起来,并在物体分类任务上,如 ImageNet 上进行了实验。但是尚未有工作将其拓展到下游任务,如物体检测、分割等任务。作者将他们之前设计的 Swin-Transformer 和 自监督学习的技术相结合,尝试拓展到这两个领域。之所以能这么做,是因为 Swin-Transformer 的架构具有这方面的优势。
除了骨干网络方面的改进,作者也提出了一种自监督学习的技术,通过将 MoCo v2 和 BYOL 相结合,得到了 MoBY。作者提到,当将该自监督学习的权重迁移到物体检测和分割任务上时,得到了和监督学习类似的效果。更狠的是,作者直接说,本文无新技术的创新,只是提供了一种组合之前好的技术的方法,但是使用了较少的 tricks,以及超参数的调整,在 ImageNet 上取得了高精度。
2 A Baseline SSL Method with Swin Transformers:
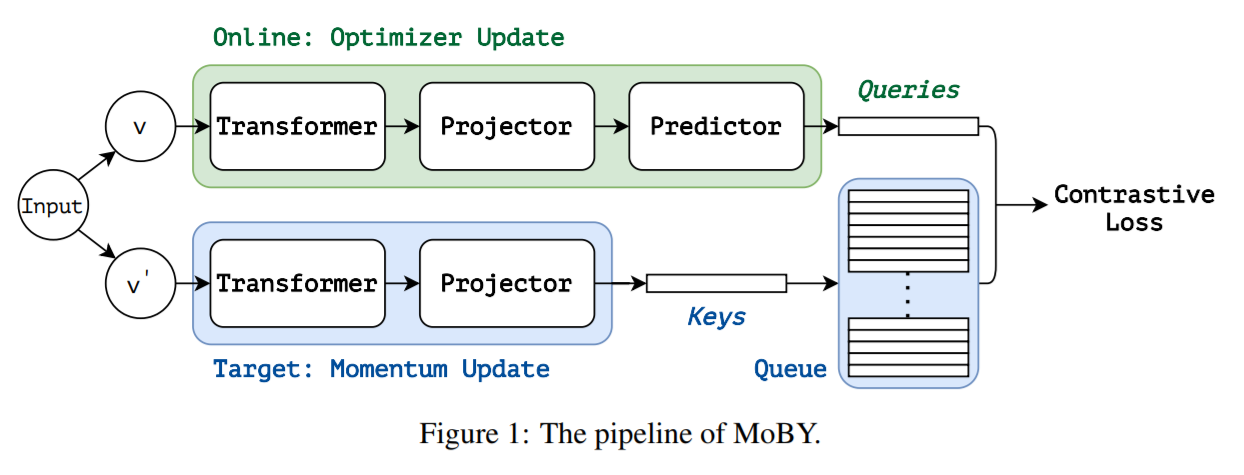
MoBY: a self-supervised learning approach:
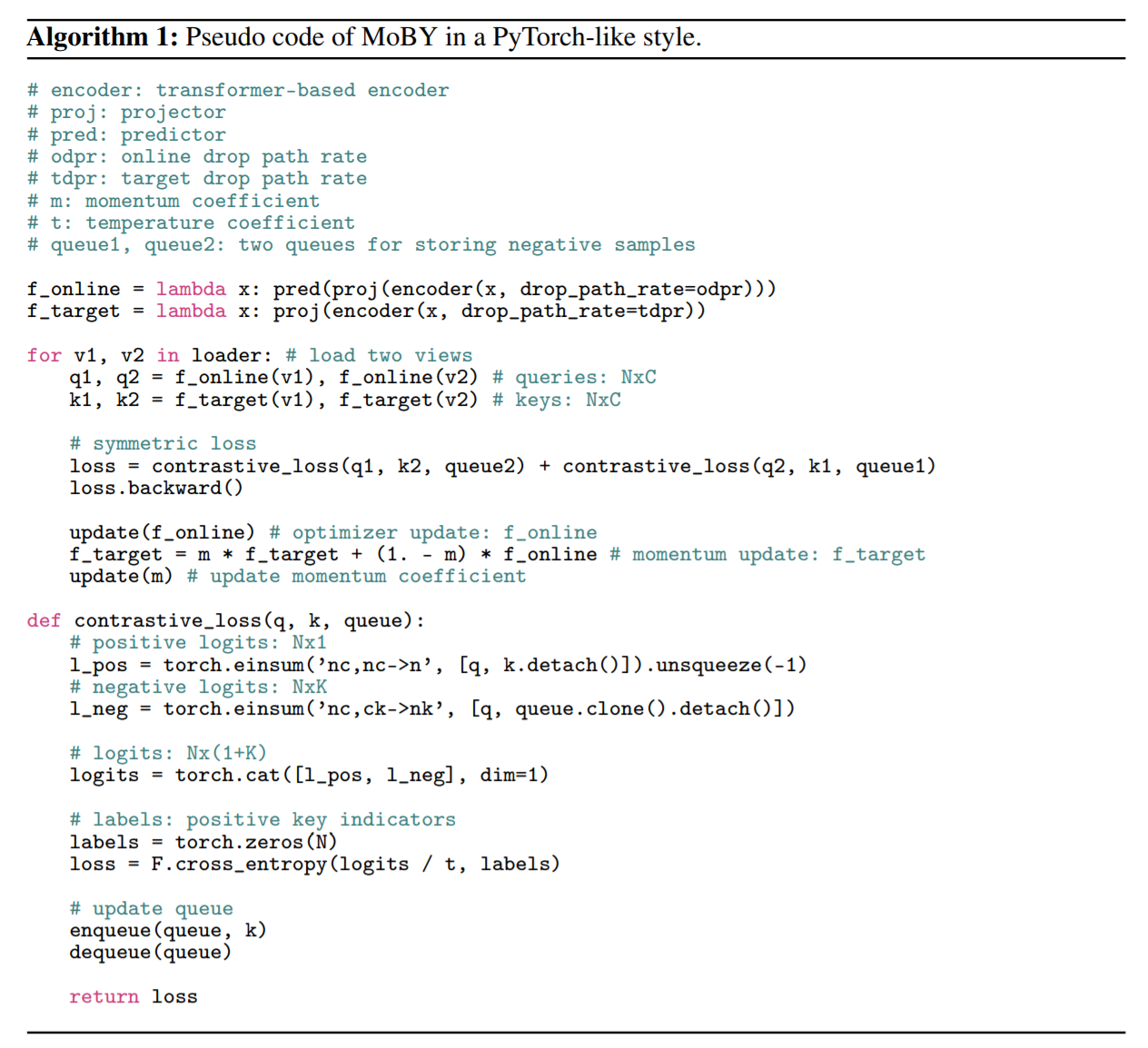
本文提出的 MoBY 方法的流程图如图 1 所示,有两个 encoder,一个是 online encoder,另外一个是 target encoder。这两个 encoder 都有一个 backbone 以及 一个 projector head(两层的 MLP),online encoder 还有另外一组 prediction head,这样就使得两个 encoder 并不是对称的。online encoder 是利用梯度进行更新,target encoder 在每一次训练迭代中,是 online encoder 的一个 moving average?
随后,用了一个对比损失函数,来学习特征表达。具体来说,对于 online view q,其对比损失可以通过如下的损失进行计算:

其中,k+ 是 target feature,ki 是 key queue 的 target feature,K 是 key queue 的大小,默认是 4096。在训练过程中,和大部分基于 Transformer 的方法一样,本文也采用 AdamW optimizer。
Swin Transformer as the backbone:
作者这里采用的是 Swin-T 作为骨干网络,其模型的复杂度和 ResNet-50,DeiT-S 差不多。
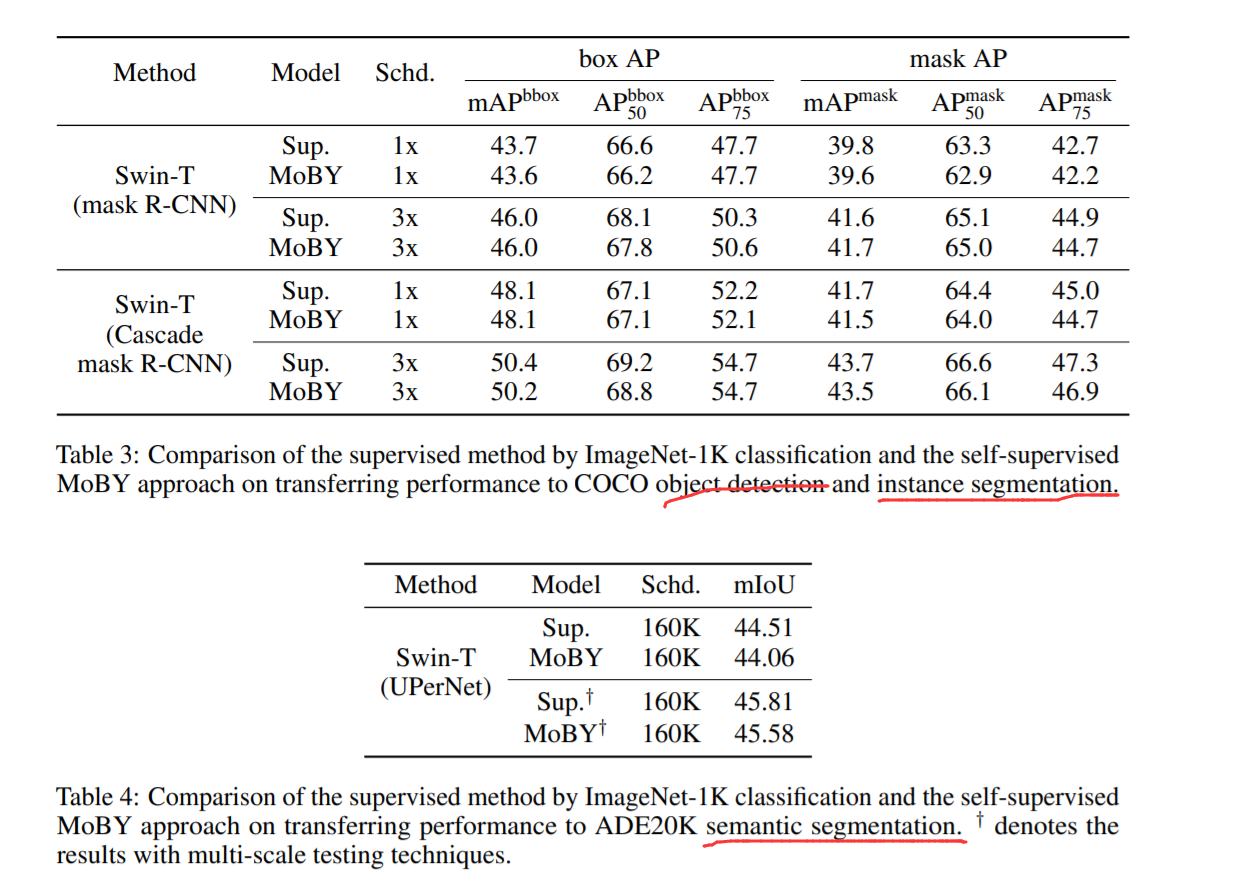
3. Experimental Results :
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号