Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
2021-04-20 15:16:06
Paper: https://arxiv.org/pdf/2103.14030.pdf
Code: https://github.com/microsoft/Swin-Transformer
1. Background and Motivation:
本文提出了一种新的多层级 Transformer 视觉模型,该模型对不同的层次,使用了不同的窗口大小,使其可以作为一个 general 的backbone,用于目标识别、物体检测、语义分割等任务。
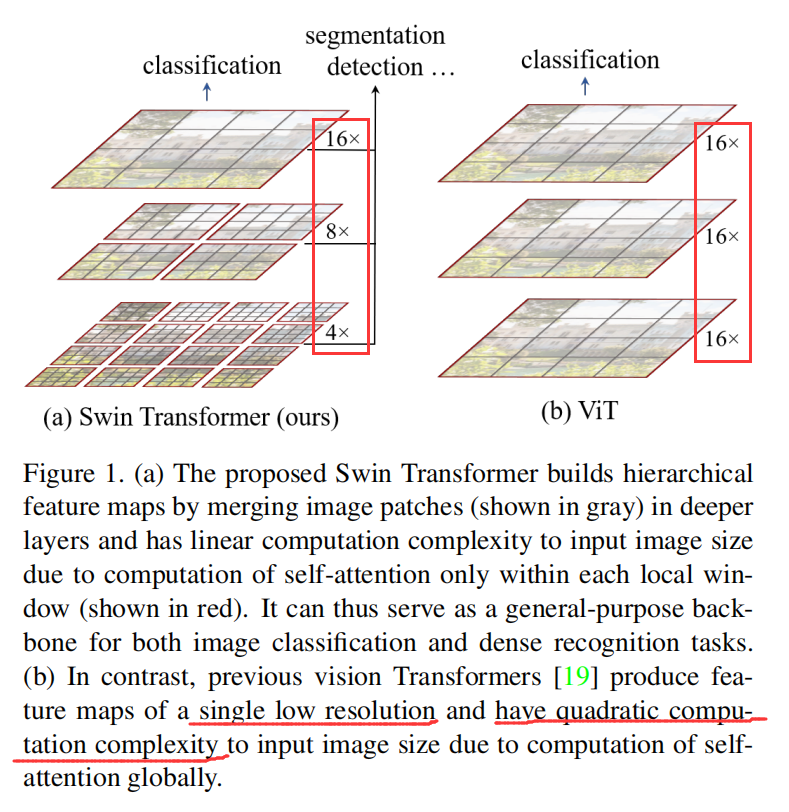
如图所示, 作者提到,从 NLP 领域将 Transformer 模型迁移到 CV 领域并不是很直观。主要是因为如下两点原因:
1). 尺寸
2). 像素分辨率更高 vs 句子中的单词
2. Swin-Transformer
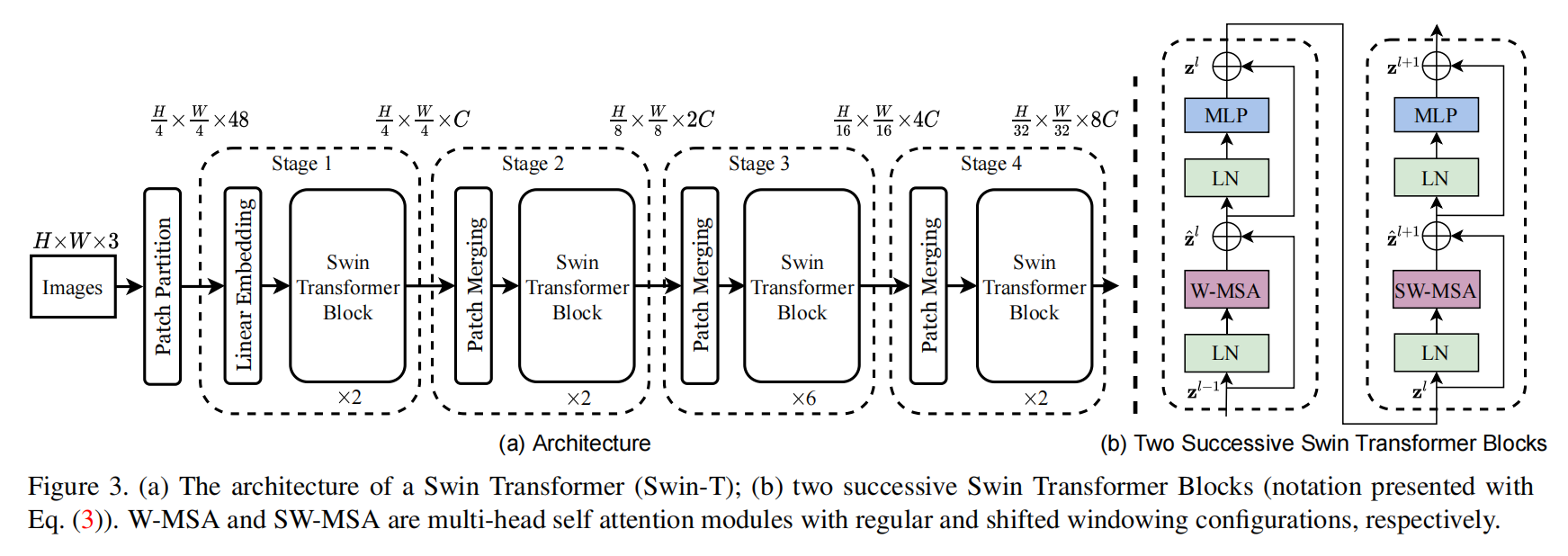
如图 3 所示,给定输入的图像,假设维度为 H*W*3,随后进行常规的图像分块(Patch Partition)。得到的每一个图像块当做是 tokens,然后将这些图像块的特征堆叠起来,构成向量。然后用一个 linear embedding layer 进行映射,可以是任意的维度,假设这里的维度为 C。可以看到作者将 Linear Embedding 和 Swindle Transformer Block 看做是第一阶段。
为了得到一个多层级的表达,作者提出随着网络深度的加深,利用 patch merging layer 进行 tokens 的减少。然后利用提出的 swin-transformer 模块进行特征学习。该模块与常规 transformer layer 的不同之处在于 shifted windows。一个 Swin-transformer block 包含一个 shifted window based MSA module,2-layer MLP with GELU non-linearity。
2.1. Shifted Window based Self-Attention:
Self-attention with non-overlapped windows.
为了更加有效地建模,作者在 local-windows 内部提出利用 self-attention 进行计算。假设每一个窗口包含 M*M 个图像块,一个全局 MSA module 和 基于 window 的图像块的复杂度分别为:
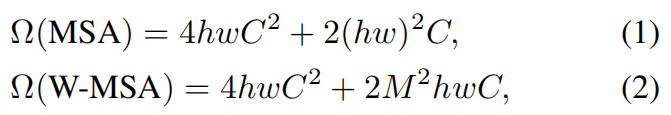
可以发现,Global self-attention 模块几乎是无法计算较大分辨率的图像。因此,这就极大的限制了其在计算机视觉领域中的应用。因为有些场景就是需要高清的图像处理技术。
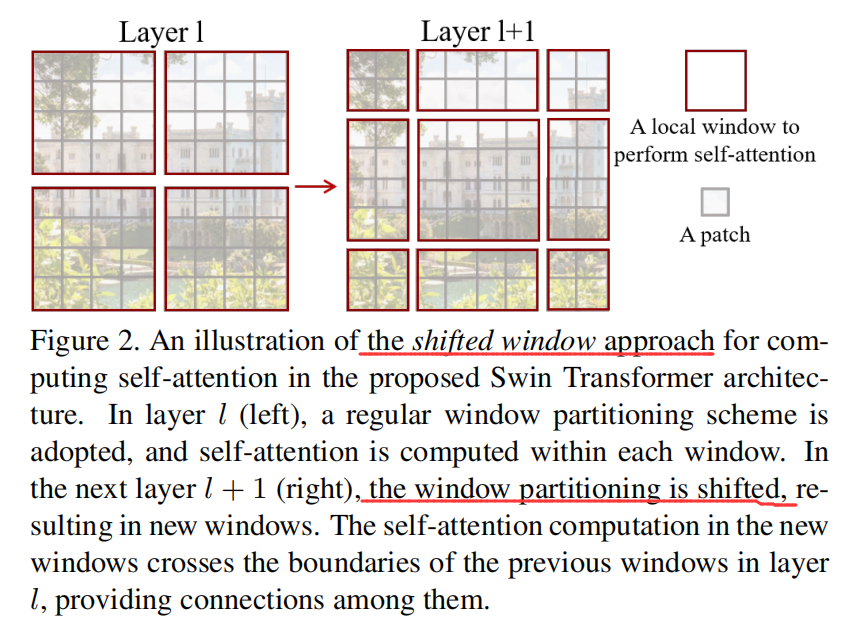
Shifted window partitioning in successive blocks.
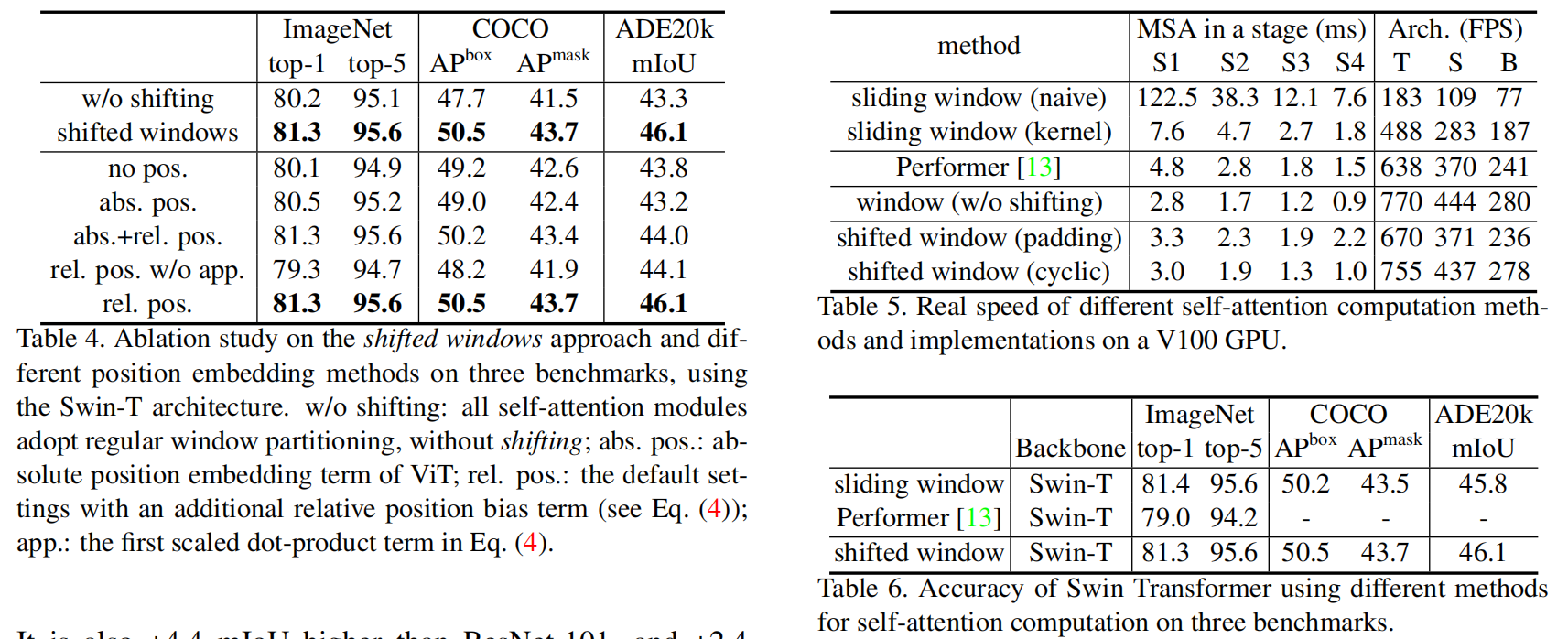
如图 2 所示,第一个模块用的是常规的窗口划分策略,即从左上角开始,将一个 8*8 的特征图,划分为 2*2 个 大小为 4*4 的图像块。然后紧跟着的模块采用的是 shifted windows,通过将窗口从常规划分窗口的位置移动 (M/2, M/2) 个位置。有了这种漂移的窗口划分方法,连续的 swin-transformer block 可以通过如下的方式进行计算:
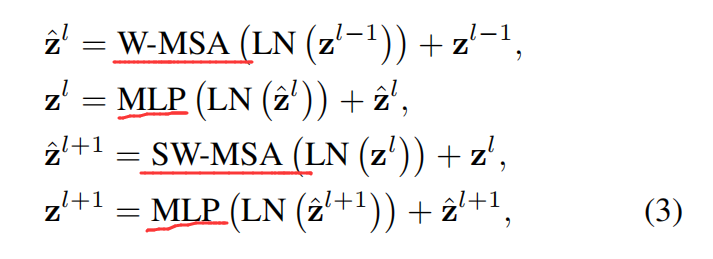
其中,Z^l 表示W-MSA 或者 SW-MSA 的第 l 个模块的输出特征。这种漂移窗口划分方法将相邻不重叠的窗口进行了关联,作者发现这对图像分类、物体检测、语义分割等任务均有提升。
Efficient Batch Computation for shifted configuration:
shifted window 方法所带来的一个问题是:显著的增加了 windows 个数。其中一些 windows 的大小小于 M*M。一种 naive 的做法是将其填充到 M*M 的大小,而在计算 attention的时候,将填充的东西直接给忽略。本文提出一种更加有效的方法,即:cyclic-shifting toward the top-left direction
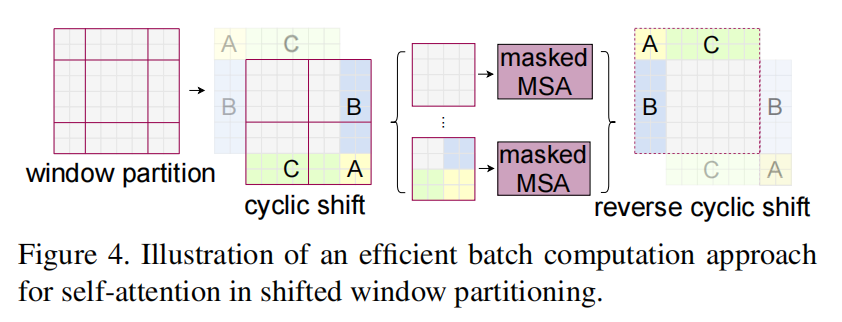
在这次 shift 之后,一批 window 可能包含几个 sub-windows,并且在 feature maps 上并不相邻,所以,可以用掩模的方法来限制 self-attention 的计算。有了这个 cyclic-shift,batched windows 的个数保持了和常规 windows 划分方法相同数量,因此也是较为高效的。
Relative Position Bias:
在计算 self-attention 的时候,作者考虑新增了一个 relative position bias 到每一个 head,来计算相似性:
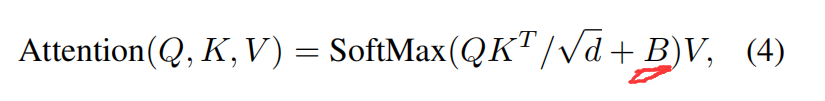
其中,Q, K, V 分别表示 query, key and value matrices, d 是 query/key 维度,M^2 是一个窗口内图像的块数。
2.2. Architecture Variants:
常规的模型称为 Swin-B,此外,作者还搞了很多变体,例如 Swin-T,Swin-S,Swin-L,分别是 0.25,0.5 以及 2 倍的模型大小和计算复杂度。值得注意的是,这里的 Swin-T 和 Swin-S 和 ResNet-50,ResNet-101 的参数量相当。这些模型变体的超参数如下所示:

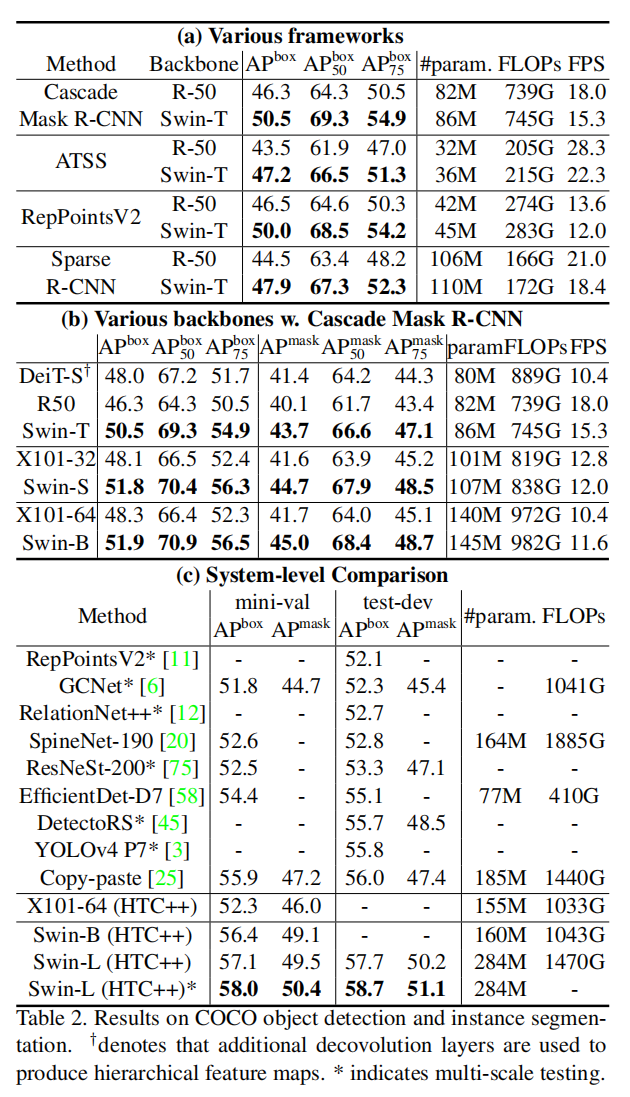
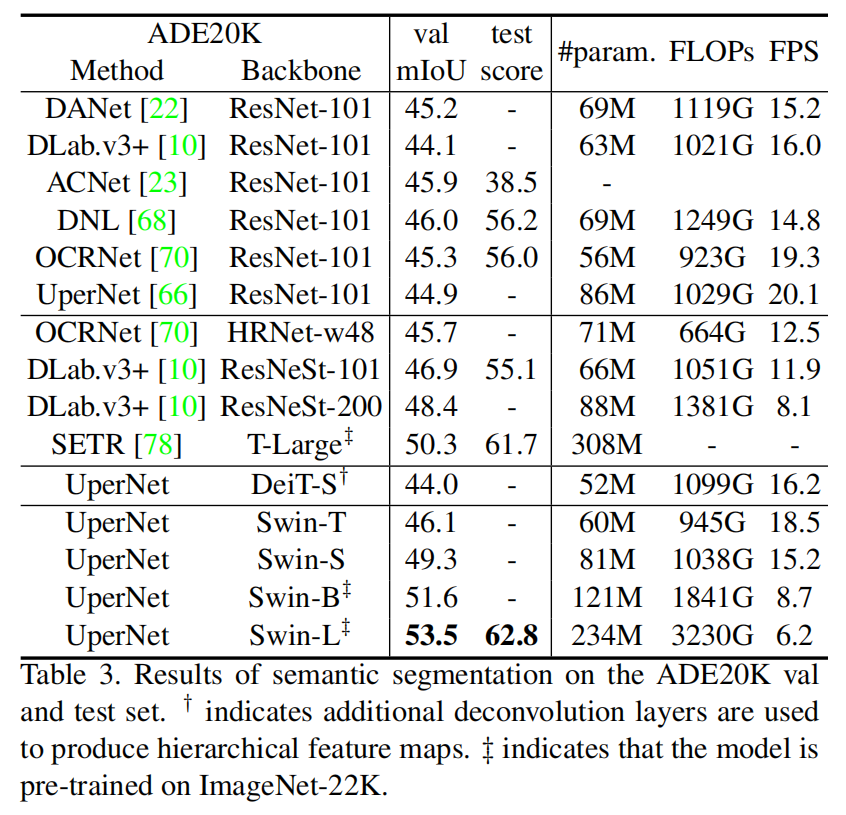
3. Experimental Results:
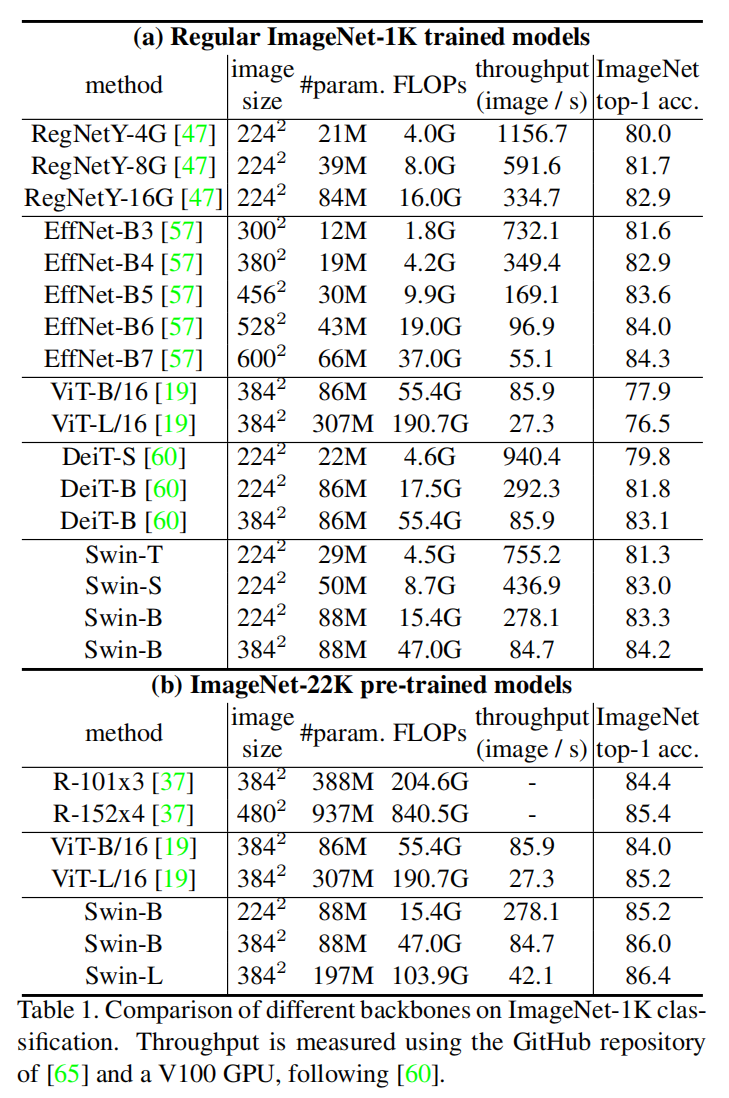
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号